

Wat is bijenkorffunctie?
Zoals we vandaag weten, is Hadoop een van de veelzijdige technologieën voor big data. Hadoop heeft de mogelijkheid om grote datasets aan te kunnen, maar omdat de datagroei evenredig is, is het moeilijk om programma's voor het verminderen van kaarten te verminderen. Voor het uitvoeren van SQL-query's, aanwezig in HDFS, werd een dergelijke technologie geïntroduceerd door Hadoop genaamd apache Hive gestart door Facebook. Hive wordt veel gebruikt door de data-analist. Ze worden ingezet voor drie functionaliteiten, namelijk: Data Summarization, data-analyse op gedistribueerd bestand en data-query. Hive biedt SQL-achtige query's genaamd HQL - hoge query-taal ondersteunt DML, door de gebruiker gedefinieerde functies. Hive compiler converteert deze query intern naar taken om de kaart te verminderen, wat het werk van Hadoop bij het schrijven van complexe programma's vereenvoudigt. We kunnen een bijenkorf vinden in applicaties zoals Datawarehousing, datavisualisatie en ad-hocanalyse, Google Analytics. Het belangrijkste voordeel is dat ze gebruikmaken van SQL-kennis, een basisvaardigheden die wordt geïmplementeerd in datawetenschappers en softwareprofessionals.
Verschillende bijenkorffuncties in detail
Hive ondersteunt verschillende gegevenstypen die niet in andere databasesystemen worden gevonden. het bevat een kaart, array en struct. Hive heeft een aantal ingebouwde functies om verschillende wiskundige en rekenkundige functies voor een speciaal doel uit te voeren. Functies in bijenkorf kunnen worden onderverdeeld in de volgende typen. Het zijn ingebouwde functies en door de gebruiker gedefinieerde functies.
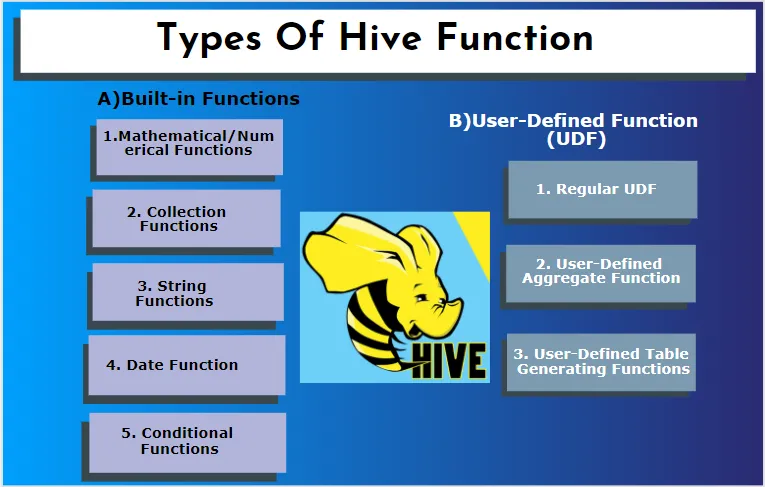
A) Ingebouwde functies
Deze functies halen gegevens uit de componenttabellen en verwerken de berekeningen. Sommige van de ingebouwde functies zijn:
1. Wiskundige / numerieke functies
Deze functies worden voornamelijk gebruikt voor wiskundige berekeningen. Deze functies worden gebruikt in SQL-query's.
| Functienaam | Voorbeeld | Beschrijving |
| ABS (dubbel x) | Hive> selecteer ABS (-200) van tmp; | Het geeft de absolute waarde van een getal terug. |
| CEIL (dubbel x) | Hive> selecteer CEIL (8.5) van tmp; | Hiermee wordt het kleinste gehele getal opgehaald dat groter is dan of gelijk is aan de waarde x. |
| Rand (), rand (int seed) | Hive> selecteer Rand () van tmp;
Rand (0-9) | Het retourneert een willekeurig getal, afhankelijk van de zaadwaarde zouden de gegenereerde willekeurige getallen deterministisch zijn. |
| Pow (dubbel x, dubbel y) | Hive> selecteer Pow (5, 2) van tmp; | Het retourneert x waarde verhoogd naar de y macht. |
| VLOER (dubbele y) | Hive> selecteer FLOOR (11.8) van tmp; | Het retourneert een maximaal geheel getal kleiner dan of gelijk aan om waarde y te geven. |
| EXP (dubbel a) | Hive> selecteer Exp (30) van tmp; | Het retourneert de exponentwaarde van 30. de natuurlijke algoritmewaarden. |
| PMOD (int a, int b) | Hive> selecteer PMOD (2, 4) van tmp; | Het geeft de positieve modulus van het getal. |
2. Collectiefuncties
Het dumpen van alle elementen en het retourneren van afzonderlijke elementen is afhankelijk van het gegevenstype.
| Functienaam | Voorbeeld | Beschrijving |
| Map_values (Map) | Hive> selecteer kaartwaarden ('hi', 45) | Het haalt ongeordende array-elementen op. |
| Grootte (kaart) | Bijenkorf> selecteer grootte (kaart) | Retourneert het aantal elementen in de gegevenstypekaart. |
| Array_contains (Array b) | Hive> selecteer array_contains (a (10)) | Retourneert TRUE als de array de waarde bevat. |
| Sorteermatrix (matrix a) | Hive> selecteer sort_array ((10, 3, 6, 1, 7)) | Sorteert de invoerarray in oplopende volgorde volgens de natuurlijke volgorde van de arrayelementen en retourneert de waarde. |
3. Stringfuncties
Met behulp van stringfuncties wordt data-analyse uitstekend uitgevoerd.
| Splitsen (string s, string pat) | Hive> selecteer split ('educba ~ hive ~ Hadoop, ' ~ ') output: ("educba", "hive", "Hadoop") | Het splitst tekenreeks rond pat-uitdrukkingen en retourneert een array. |
| laden (string s, int Len, stringpad) | Hive> selecteer belasting ('EDUCBA', 6, 'H') | Het retourneert tekenreeksen met juiste vulling met de lengte van de tekenreeks. (padkarakter). |
| Lengte (string str) | Bijenkorf> selecteer lengte ('educba') | Deze functie retourneert de lengte van de tekenreeks. |
| Rtrim (string a) | Hive> selecteer rtrim ('TOPIC');
Uitgang: 'Onderwerp' | Het retourneert het resultaat door ruimtes aan de rechterkant te knippen. |
| Concat (string m, string n) | Hive> selecteer concat ('data', 'ware') Resultaat: Dataware | Het resulteert in de tekenreeks door twee tekenreeksen samen te voegen, dit kan een willekeurig aantal ingangen hebben. |
| Achteruit (string s) | Hive> selecteer reverse ('Mobile') | Retourneert het resultaat van een omgekeerde tekenreeks. |
4. Datum functie
Het is noodzakelijk om een gegevensindeling in de component te hebben om Null-fouten in de uitvoer te voorkomen. Het is noodzakelijk dat datumcompatibiliteit compatibel is met bijenkorf geïntroduceerde datumfuncties.
| Unix_timestamp ( Stringdatum, stringpatroon) | Hive> selecteer Unix_ timestamp ('2019-06-08', 'jjjj-mm-dd'); Resultaat: 124576 400 benodigde tijd: 0, 146 seconden | Deze functie retourneert de datum naar het specifieke formaat en retourneert seconden tussen datum en Unix-tijden. |
| Unix_timestamp (tekenreeksdatum) | Hive> selecteer Unix_ timestamp ('2019-06-08 09:20:10', 'jjjj-mm-dd'); | Het retourneert de datum in 'jjjj-MM-dd HH: mm: ss' formaat in Unix-tijdstempel. |
| Uur (tekenreeksdatum) | Hive> selecteer uur ('2019-06-08 09:20:10'); Resultaat: 09 uur | Het geeft het tijdstempeluur terug |
5. Voorwaardelijke functies
| If (Booleaanse test, T-waarde true, t false) | Hive> selecteer IF (1 = 1, 'TRUE', 'FALSE') als IF_CONDITION_TEST; | Het controleert met de voorwaarde of de waarde true retourneert 1 en false retourneert 0. |
| Is niet nul (b) | Hive> Select is niet null (null); | Dit haalt geen nuluitspraken op. als null onwaar retourneert. |
| Coalesce (waarde1, waarde2) | Voorbeeld: bijenkorf> selecteer coalitie (Null, null, 4, null, 6). het keert terug 4. | Het haalt eerst geen nulwaarden uit de zoeklijst. |
B) Door gebruiker gedefinieerde functie (UDF)
Hive gebruikt gebruikersspecifieke functies volgens de clientvereisten die het is geschreven in Java-programmering. Het wordt geïmplementeerd door twee interfaces, namelijk eenvoudige API en complexe API. Ze worden aangeroepen vanuit de componentzoekopdracht. Drie soorten UDF's:
1. Regelmatige UDF
Het werkt op een tafel met een enkele rij. Het wordt gemaakt door een Java-klasse te maken en deze vervolgens in een .jar-bestand te verpakken. De volgende stap is om te verifiëren met een componentklaspad. en voer ze vervolgens eindelijk uit in een bijenkorfquery.
2. Door de gebruiker gedefinieerde aggregatiefunctie
Ze gebruiken geaggregeerde functies zoals avg / mean door vijf methoden te implementeren init (), iterate (), partial (), merge (), terminate ().
3. Door de gebruiker gedefinieerde tabel die functies genereert
Het werkt met een enkele rij in een tabel en resulteert in meerdere rijen.
Conclusie
Concluderend hebben we via dit artikel gedetailleerd leren werken in het component-platform met ingebouwde functies en door de gebruiker gedefinieerde functies. De meeste organisaties hebben programmeur en SQL-ontwikkelaar om aan het server-side proces te werken, maar een apache-bijenkorf is een krachtig hulpmiddel dat hen helpt om Hadoop-raamwerk te gebruiken zonder voorkennis over programma's en het verminderen van kaarten. Hive helpt nieuwe gebruikers om data-analyse zonder belemmeringen te starten en te verkennen.
Aanbevolen artikelen
Dit is een handleiding voor de Hive-functie. Hier bespreken we het Concept, twee verschillende soorten functies en subfuncties in Hive. U kunt ook onze andere voorgestelde artikelen doornemen voor meer informatie -
- Top String-functies in Hive
- Hive Interview Vragen
- Wat is RMAN Oracle?
- Wat is Waterfall Model?
- Inleiding tot Hive Architecture
- Bijenkorf sorteren op