

Inleiding tot beslissingsboomalgoritme
Wanneer we een probleem moeten oplossen dat een classificatie- of regressieprobleem is, is het beslissingsboomalgoritme een van de meest populaire algoritmen die worden gebruikt voor het bouwen van de classificatie- en regressiemodellen. Ze vallen onder de categorie van begeleid leren, dat wil zeggen gegevens die zijn gelabeld.
Wat is Decision Tree Algorithm?
Beslisboomalgoritme is een bewaakt machine-leeralgoritme waarbij gegevens op elke rij continu worden verdeeld op basis van bepaalde regels totdat het uiteindelijke resultaat wordt gegenereerd. Laten we een voorbeeld nemen, stel dat u een winkelcentrum opent en natuurlijk wilt dat het in de loop van de tijd in zaken groeit. Dus wat dat betreft, zou u terugkerende klanten plus nieuwe klanten in uw winkelcentrum nodig hebben. Hiervoor zou u verschillende zakelijke en marketingstrategieën voorbereiden, zoals het verzenden van e-mails naar potentiële klanten; aanbiedingen en deals maken, nieuwe klanten targeten, enz. Maar hoe weten we wie de potentiële klanten zijn? Met andere woorden, hoe classificeren we de categorie klanten? Zoals sommige klanten één keer in de week bezoeken en anderen graag één of twee keer in een maand bezoeken, of sommige bezoeken in een kwartier. Dus beslissingsbomen zijn zo'n classificatie-algoritme dat de resultaten in groepen classificeert totdat er geen overeenkomst meer is.
Op deze manier daalt de beslissingsboom in een boomstructuur. De belangrijkste componenten van een beslissingsboom zijn:
- Beslissingsknooppunten, waar de gegevens worden gesplitst of zeg, het is een plaats voor het kenmerk.
- Beslissingslink, die een regel vertegenwoordigt.
- Beslissingsbladeren, die de uiteindelijke resultaten zijn.

Werking van een beslissingsboomalgoritme
Er zijn veel stappen betrokken bij de werking van een beslissingsboom:
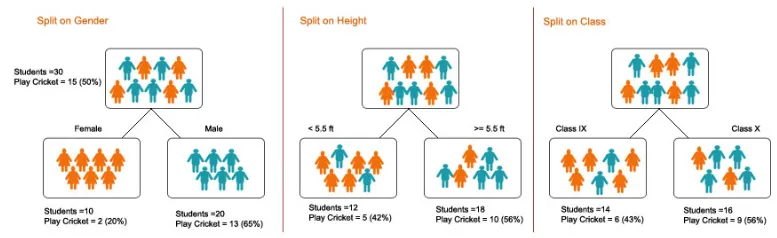
1. Splitsen - Het is het proces van het partitioneren van gegevens in subsets. Splitsen kan worden gedaan op verschillende factoren, zoals hieronder weergegeven, dwz op basis van geslacht, lengte of op basis van klasse.
2. Snoeien - Het is het proces van het inkorten van de takken van de beslissingsboom, waardoor de boomdiepte wordt beperkt
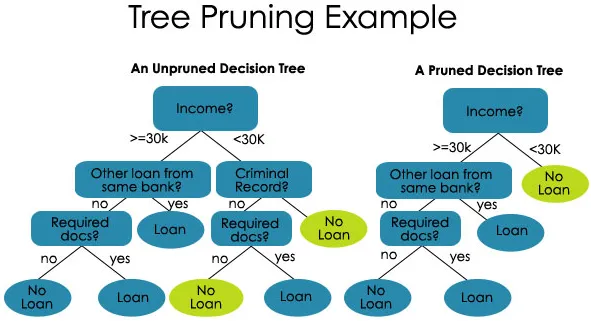
Snoeien is ook van twee soorten:
- Pre-snoeien - hier stoppen we met het laten groeien van de boom wanneer we geen statistisch significant verband vinden tussen de attributen en klasse op een bepaald knooppunt.
- Na het snoeien - Om te snoeien moeten we de prestaties van het testsetmodel valideren en vervolgens de takken afsnijden die het gevolg zijn van overmatig geluid van de trainingsset.
3. Boomselectie - De derde stap is het vinden van de kleinste boom die bij de gegevens past.
Voorbeelden en illustratie van het construeren van een beslissingsboom
Nu, zoals we de principes van een beslissingsboom hebben geleerd. Laten we dit begrijpen en illustreren met behulp van een voorbeeld.
Stel dat u op een bepaalde dag cricket wilt spelen (bijvoorbeeld op zaterdag). Welke factoren spelen een rol of het spel gaat plaatsvinden of niet?
Het is duidelijk dat de belangrijkste factor het klimaat is, geen andere factor heeft zoveel waarschijnlijkheid als zoveel klimaat voor de spelonderbreking.
We hebben de gegevens van de afgelopen 10 dagen verzameld die hieronder worden weergegeven:
| Dag | Weer | Temperatuur | Vochtigheid | Wind | Speel? |
| 1 | Bewolkt | Heet | hoog | Zwak | Ja |
| 2 | Zonnig | Heet | hoog | Zwak | Nee |
| 3 | Zonnig | mild | normaal | Sterk | Ja |
| 4 | Regenachtig | mild | hoog | Sterk | Nee |
| 5 | Bewolkt | mild | hoog | Sterk | Ja |
| 6 | Regenachtig | Koel | normaal | Sterk | Nee |
| 7 | Regenachtig | mild | hoog | Zwak | Ja |
| 8 | Zonnig | Heet | hoog | Sterk | Nee |
| 9 | Bewolkt | Heet | normaal | Zwak | Ja |
| 10 | Regenachtig | mild | hoog | Sterk | Nee |
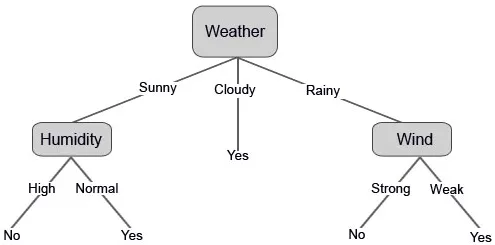
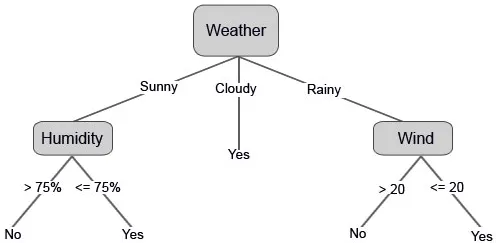
Laten we nu onze beslisboom samenstellen op basis van de gegevens die we hebben. We hebben de beslissingsboom dus in twee niveaus verdeeld, de eerste is gebaseerd op het kenmerk "Weer" en de tweede rij is gebaseerd op "Vochtigheid" en "Wind". De onderstaande afbeeldingen illustreren een geleerde beslissingsboom.
We kunnen ook enkele drempelwaarden instellen als de functies doorlopend zijn.
Wat is entropie in het beslissingsboomalgoritme?
In eenvoudige woorden, entropie is de maatstaf voor hoe ongeordend uw gegevens zijn. Hoewel je deze term misschien hebt gehoord in je lessen Wiskunde of Natuurkunde, is het hier hetzelfde.
De reden dat Entropy in de beslissingsboom wordt gebruikt, is omdat het uiteindelijke doel in de beslissingsboom is om vergelijkbare gegevensgroepen in vergelijkbare klassen te groeperen, dwz de gegevens op te ruimen.
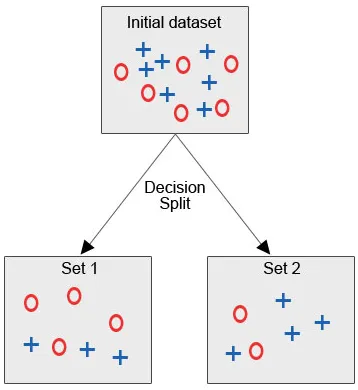
Laten we de onderstaande afbeelding bekijken, waar we de eerste gegevensset hebben en we zijn verplicht om beslissingsboomalgoritme toe te passen om de vergelijkbare gegevenspunten in één categorie te groeperen.
Na de splitsing van de beslissing, zoals we duidelijk kunnen zien, vallen de meeste rode cirkels onder een klasse, terwijl de meeste blauwe kruisen onder een andere klasse vallen. Daarom werd besloten de attributen te classificeren die op verschillende factoren konden worden gebaseerd.
Laten we nu proberen wat wiskunde hier te doen:
Laten we zeggen dat we “N” -sets van het item hebben en deze items in twee categorieën vallen, en nu om de gegevens op basis van labels te groeperen, introduceren we de ratio:
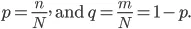
De entropie van onze set wordt gegeven door de volgende vergelijking:
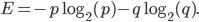
Laten we de grafiek voor de gegeven vergelijking bekijken:
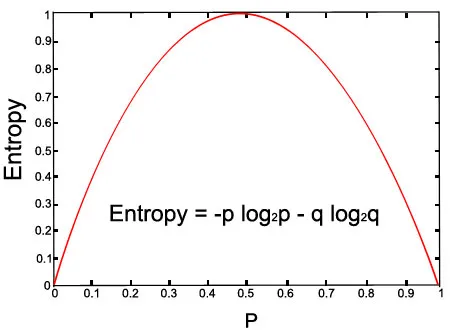
Bovenstaande afbeelding (met p = 0, 5 en q = 0, 5)
voordelen
1. Een beslissingsboom is eenvoudig te begrijpen en als deze eenmaal is begrepen, kunnen we deze construeren.
2. We kunnen een beslissingsboom implementeren op zowel numerieke als categorische gegevens.
3. Beslisboom is een robuust model gebleken met veelbelovende resultaten.
4. Ze zijn ook tijdbesparend met grote gegevens.
5. Het vereist minder inspanning voor de training van de gegevens.
nadelen
1. Instabiliteit - Alleen als de informatie nauwkeurig en nauwkeurig is, levert de beslissingsboom veelbelovende resultaten op. Zelfs als er een kleine wijziging in de invoergegevens is, kan dit grote wijzigingen in de structuur veroorzaken.
2. Complexiteit - Als de dataset enorm is met veel kolommen en rijen, is het een zeer complexe taak om een beslissingsboom met veel takken te ontwerpen.
3. Kosten - Soms blijft kosten ook een belangrijke factor, omdat wanneer iemand een complexe beslissingsboom moet bouwen, er geavanceerde kennis nodig is in kwantitatieve en statistische analyse.
Conclusie
In dit artikel hebben we geleerd over het beslissingsboomalgoritme en hoe we er een kunnen construeren. We zagen ook de grote rol die Entropy speelt in het beslissingsboomalgoritme en ten slotte zagen we de voor- en nadelen van de beslissingsboom.
Aanbevolen artikelen
Dit is een leidraad geweest voor Decision Tree Algorithm. Hier hebben we de rol besproken die wordt gespeeld door Entropy, Working, Voordelen en Nadelen. U kunt ook onze andere voorgestelde artikelen doornemen voor meer informatie -
- Belangrijke methoden voor datamining
- Wat is een webtoepassing?
- Gids voor Wat is Data Science?
- Sollicitatievragen voor Data Analyst
- Toepassing van beslissingsboom in datamining