
Inleiding tot AWS Data Pipeline
Gegevens groeien exponentieel met de dag en worden moeilijk te beheren in vergelijking met het verleden. We hebben hulpmiddelen en diensten nodig om onze gegevens efficiënt en goedkoper te beheren, daar komt de AWS-datapijplijn in gedachten. Het gaat niet alleen om het opslaan van gegevens, maar u moet de gegevens op dezelfde plek analyseren, verwerken en transformeren in de gewenste vorm, dit alles kan worden bereikt met AWS Data Pipeline.
Noodzaak van datapijplijn
Laten we proberen de behoefte aan datapijplijn te begrijpen met het voorbeeld:
Voorbeeld 1
We hebben een website die afbeeldingen en gifs weergeeft op basis van zoekopdrachten of filters van gebruikers. Onze primaire focus ligt op het aanbieden van inhoud. Er zijn bepaalde doelen te bereiken die zijn: -
- De levering van inhoud verbeteren: bedienen wat gebruikers efficiënt en snel genoeg willen.
- Beheer de applicatie efficiënt: opslag van gebruikersgegevens en websitelogboeken voor latere analytische doeleinden.
- Verbeter de bedrijfsvoering: met behulp van de opgeslagen gegevens en analyses neemt u de beslissing om uw bedrijf te verbeteren tegen lagere kosten.
Voorbeeld 2
Er zijn bepaalde knelpunten die moeten worden aangepakt om de doelen te bereiken:
- De enorme hoeveelheid gegevens in verschillende formaten en op verschillende plaatsen, waardoor het verwerken, opslaan en migreren van gegevens een complexe taak is.
Verschillende componenten voor gegevensopslag voor verschillende soorten gegevens:
- Mogelijke realtime gegevens voor de geregistreerde gebruikers: Dynamo DB .
- Webserverlogboeken voor potentiële gebruikers: Amazon S3 .
- Demografische gegevens en inloggegevens: Amazon RDS.
- Sensorgegevens & dataset van derden: Amazon S3.
Oplossingen
- Haalbare oplossing: we kunnen zien dat we te maken hebben met verschillende soorten tools om gegevens om te zetten van ongestructureerd naar gestructureerd voor analyse. Hier moeten we verschillende tools gebruiken om gegevens op te slaan en opnieuw om verwerkte gegevens te converteren, analyseren en op te slaan. Geen kostenbesparende oplossing.
- Optimale oplossing: gebruik een gegevenspijplijn die verwerking, visualisatie en migratie afhandelt. Datapijplijn kan nuttig zijn bij de migratie van gegevens van verschillende plaatsen, ook voor het analyseren van gegevens en verwerking namens u op dezelfde locatie.
Wat is de AWS-gegevenspijplijn?
AWS Data Pipeline is in feite een webservice aangeboden door Amazon die u helpt uw gegevens op een schaalbare en betrouwbare manier te transformeren, verwerken en analyseren en verwerkte gegevens op te slaan in S3, DynamoDb of uw lokale database.
- Met AWS Data Pipeline hebt u eenvoudig toegang tot gegevens uit verschillende bronnen.
- Transformeer en verwerk die gegevens op schaal.
- Breng resultaten efficiënt over naar andere services zoals S3, DynamoDb-tabel of on-premises datastore.
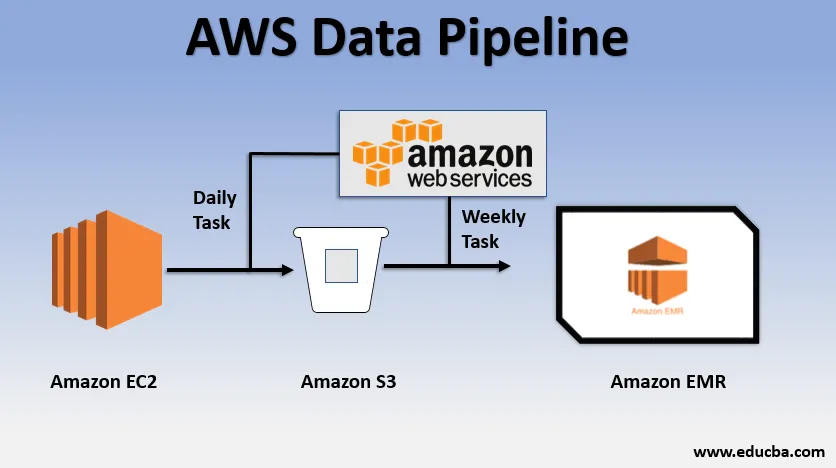
Basisgebruik Voorbeeld van de datapijplijn
- We zouden een website via EC2 kunnen implementeren die elke dag logboeken genereert.
- Een eenvoudige dagelijkse taak kan logbestanden van E2 worden gekopieerd en naar de S3-bucket worden bereikt.
- Een wekelijkse taak zou kunnen zijn om de gegevens te verwerken en gegevensanalyse te starten via Amazon EMR om wekelijkse rapporten te genereren op basis van alle verzamelde gegevens.
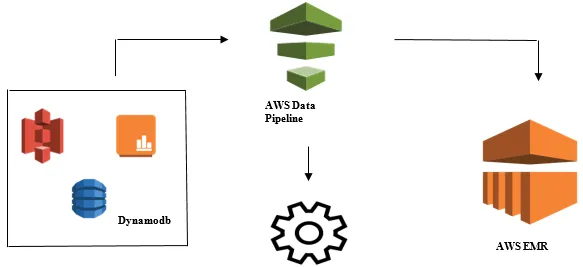
Data-analyse starten met AWS Data Pipeline
- Gegevens verzamelen uit verschillende gegevensbronnen zoals - S3, Dynamodb, On-premises, sensorgegevens, enz.
- Transformatie, verwerking en analyse uitvoeren op AWS EMR om wekelijkse rapporten te genereren.
- Wekelijks rapport opgeslagen in Redshift, S3 of on-premise database.
Voordelen van AWS Data Pipeline
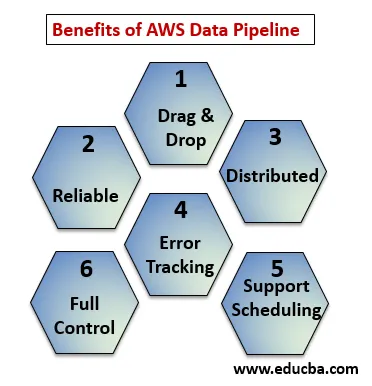
Hieronder de punten verklaren de voordelen van AWS Data Pipeline:
- Drag and Drop-console die gemakkelijk te begrijpen en te gebruiken is.
- Gedistribueerde en betrouwbare infrastructuur: datapijpleidingen werken op schaalbare services en zijn betrouwbaar als een fout of taak mislukt, het kan opnieuw worden ingesteld.
- Ondersteunt planning en foutopsporing: u kunt uw taken plannen en bijhouden wat mislukt en succesvol is geworden.
- Gedistribueerd: kan parallel op meerdere machines of op een lineaire manier worden uitgevoerd.
- Volledige controle over rekenbronnen zoals EC2, EMR-clusters.
AWS-componenten voor gegevensleidingen
Hieronder staan de componenten van de AWS Data Pipeline:
1. Definitie van pijpleidingen
Zet uw bedrijfslogica om in de AWS Data Pipeline.
- Gegevensknooppunten : bevat de naam, locatie en indeling van de gegevensbron (S3, dynamodb, on-premises)
- Activiteiten : Verplaats, transformeer of voer zoekopdrachten uit op uw gegevens.
- Schema : Plan uw dagelijkse of wekelijkse activiteiten.
- Voorwaarde : voorwaarden zoals het starten van de planner controleren de beschikbaarheid van gegevens bij de bron.
- Bronnen : Bereken bronnen EC2, EMR.
- Acties : update over datapijplijn, meldingen verzenden, alarm activeren.
2. Pijpleidingen
Hier plant en voert u de taken uit om gedefinieerde activiteiten uit te voeren.
- Pijplijncomponenten : pijplijncomponenten zijn hetzelfde als de componenten van de pijplijndefinitie.
- Instanties: tijdens het uitvoeren van taken compileert AWS alle componenten om bepaalde bruikbare instanties te maken. Dergelijke instanties hebben alle informatie over specifieke taken.
- Pogingen: we hebben al besproken hoe betrouwbaar de datapijplijn is met zijn retry-mechanismen. Hier stelt u in hoe vaak u de taak opnieuw wilt proberen als deze mislukt.
3. Taakagent
Vraagt of peilt naar taken uit de AWS Data Pipeline en voert die taken vervolgens uit.
Prijzen van AWS-datapijplijnen
Hieronder beschrijven de punten de prijzen van de AWS Data-pijplijn:
1. Gratis niveau
U kunt gratis aan de slag met AWS Data Pipeline als onderdeel van de AWS gratis gebruikslaag. Nieuwe aanmeldklanten krijgen elke maand een aantal gratis voordelen voor een jaar:
- 3 Voorwaarden voor lage frequentie die zonder kosten op AWS draait.
- 5 Activiteiten van laagfrequent draaien op AWS zonder kosten.
2. Lage frequentie
Lage frequentie is bedoeld om één keer per dag of minder te worden uitgevoerd. Datapijplijn volgt dezelfde factureringsstrategie als andere AWS-webservices, dwz gefactureerd op basis van uw gebruik. Het wordt gefactureerd op hoe vaak uw taken, activiteiten en randvoorwaarden elke dag worden uitgevoerd en waar ze worden uitgevoerd (AWS of on-premises). Hoogfrequente activiteiten zijn gepland om meer dan eens per dag te worden uitgevoerd.
Voorbeeld: we kunnen een activiteit plannen die elk uur wordt uitgevoerd en de websitelogboeken verwerken, of dit kan elke 12 uur zijn. Terwijl laagfrequente activiteiten die activiteiten zijn die eenmaal per dag of minder worden uitgevoerd als niet aan de voorwaarden is voldaan. Inactieve pijpleidingen hebben de status INACTIVE, PENDING en FINISHED.
3. Prijsbepaling van AWS-gegevenspijplijn Regio gewijs weergegeven
Regio # 1: US East (N.Virginia), US West (Oregon), Asia Pacific (Sydney), EU (Ierland)
| Hoge frequentie | Lage frequentie | |
| Activiteiten of randvoorwaarden die over AWS lopen | $ 1, 00 per maand | $ 0, 06 per maand |
| Activiteiten of randvoorwaarden die ter plaatse worden uitgevoerd | $ 2, 50 per maand | $ 1, 50 per maand |
| Inactieve pijpleidingen: $ 1, 00 per maand |
Regio # 2: Azië-Pacific (Tokio)
| Hoge frequentie | Lage frequentie | |
| Activiteiten of randvoorwaarden die over AWS lopen | $ 0, 9524 per maand | $ 0, 5715 per maand |
| Activiteiten of randvoorwaarden die ter plaatse worden uitgevoerd | $ 2, 381 per maand | $ 1, 4286 per maand |
| Inactieve pijpleidingen: $ 0, 9524 per maand |
De pijplijn die een dagelijkse taak, dat wil zeggen een laagfrequente activiteit op AWS om gegevens van DynamoDB-tabel naar Amazon S3 te verplaatsen, kost $ 0, 60 per maand. Als we EC2 toevoegen om een rapport op basis van Amazon S3-gegevens te produceren, zouden de totale pijplijnkosten $ 1, 20 per maand bedragen. Als we deze activiteit om de 6 uur uitvoeren, kost het $ 2, 00 per maand, omdat het dan een hoogfrequente activiteit zou zijn.
Conclusie
AWS Data Pipeline is een zeer handige oplossing voor het beheren van de exponentieel groeiende gegevens tegen goedkopere kosten. Het is zeer betrouwbaar en schaalbaar volgens uw gebruik. Voor elke zakelijke behoefte waar het gaat om een grote hoeveelheid gegevens, is AWS Data Pipeline een zeer goede keuze om al onze zakelijke doelen te bereiken.
Aanbevolen artikelen
Dit is een handleiding voor de AWS Data Pipeline. Hier bespreken we de behoeften van de datapijplijn, wat is AWS-datapijplijn, zijn component en prijsdetails. U kunt ook onze andere gerelateerde artikelen doornemen voor meer informatie -
- AWS EBS
- AWS-databases
- Wat is AWS EC2?
- Voordelen van datavisualisatie
- Top 7 concurrenten van AWS met functies
- Leer de lijst met functies van Amazon Web Services