

Wat is Big Data en Hadoop?
Gegevens groeien elke dag exponentieel en met dergelijke groeiende gegevens komt de noodzaak om die gegevens te gebruiken. Zoals vroeger hadden we floppy drives om gegevens op te slaan en de gegevensoverdracht was ook traag, maar tegenwoordig zijn deze onvoldoende en wordt cloudopslag gebruikt omdat we terabytes aan gegevens hebben. In de wereld van vandaag hebben we sociale media die het meest bijdragen aan datagroei. Het bestaat uit het gedrag, de mindset en verschillende andere aspecten van mensen. Er wordt gezegd dat in elke minuut 300 uur video wordt geüpload op YouTube, meer dan 20 miljoen foto's worden geüpload in Facebook en vele anderen. Bovendien is er geen goede structuur van de gegevens die worden geüpload, wat de grootste uitdaging is voor het verwerken van die gegevens.
Omdat enorme gegevens met hoge snelheid worden gegenereerd, konden traditionele RDBMS-systemen dergelijke snelle groei niet aan. Bovendien zijn ze ook niet in staat om ongestructureerde gegevens te verwerken. Het werd erg moeilijk om zo'n enorme hoeveelheid heterogene gegevens snel te verwerken en deze gegevens met een hoge verwerkingssnelheid te verwerken. Zo ontstond de behoefte aan een dergelijk systeem dat in staat is om grote datasets efficiënt te verwerken. Daarom is Hadoop ontstaan om het scenario op te lossen. HDFS is het onderdeel van Hadoop dat het opslagprobleem van de grote gegevensset heeft aangepakt met behulp van gedistribueerde opslag, terwijl YARN het onderdeel is dat het verwerkingsprobleem heeft aangepakt en de verwerkingstijd drastisch heeft verlaagd.
Hadoop is een open-source softwareframework voor het opslaan en verwerken van grote gegevenssets met behulp van een gedistribueerd groot cluster van grondstoffenhardware. Het werd ontwikkeld door Doug Cutting en Michael J. Cafarella en onder licentie van Apache. Het is geschreven met behulp van Java en is ontwikkeld op basis van het papier geschreven door Google op het MapReduce-systeem en het past concepten van functioneel programmeren toe. Het is betrouwbaar, economisch flexibel en schaalbaar.
De kerncomponenten van Hadoop
De kerncomponenten van Hadoop zijn als volgt
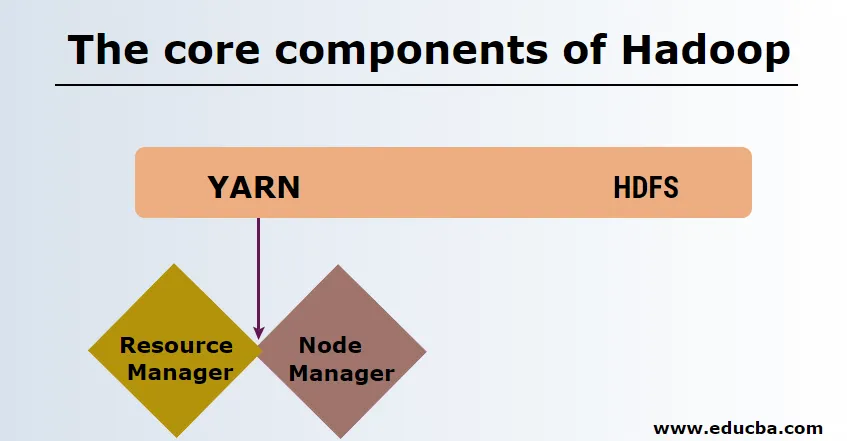
-
HDFS
HDFS of Hadoop Distributed File System hebben Namenode en dataknooppunt. Namenode is het hoofdknooppunt dat de hoofddaemon uitvoert en het beheert de gegevensknooppunten en houdt alle bewerkingen bij. Datanodes zijn de slaves waar de gegevens daadwerkelijk worden opgeslagen.
-
GAREN
YARN bestaat uit twee hoofdcomponenten:
1. ResourceManager: het draait op het hoofdknooppunt en beheert alle bronnen en plant alle toepassingen. Het heeft Scheduler & ApplicationManager.
2. NodeManager: het draait op elk slave-knooppunt en is verantwoordelijk voor het beheer van containers en het toezicht op het gebruik van bronnen.
Verschillende componenten van Hadoop
Er zijn verschillende componenten van Hadoop zoals het varken, bijenkorf, sqoop, goot, mahout, oozie, dierenverzorger, HBase, enz.
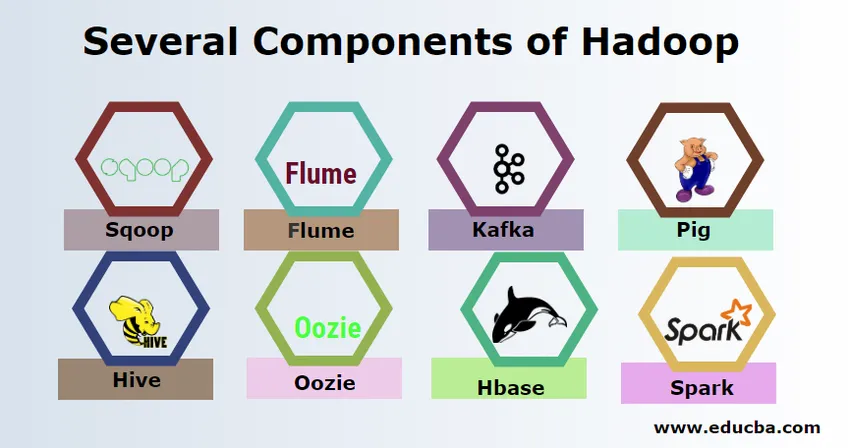
- Sqoop - Het wordt gebruikt om gegevens van RDBMS naar Hadoop te importeren en exporteren en vice versa.
- Flume - Het wordt gebruikt om realtime gegevens naar Hadoop te halen.
- Kafka - Het is een berichtensysteem dat wordt gebruikt om realtime gegevens naar Hadoop te routeren.
- Pig - Het wordt gebruikt als een scripttaal voor gegevensverwerking.
- Bijenkorf - Het is een datawarehousing-framework dat is gebouwd op HDFS zodat gebruikers die vertrouwd zijn met SQL query's kunnen uitvoeren om de gegevens te verkrijgen. Deze vragen worden HiveQL genoemd.
- Oozie - Het wordt gebruikt om de workflow van taken te plannen om op gespecificeerde gebeurtenissen of tijd te worden uitgevoerd.
- Hbase - Het is de no SQL-database die wordt aangeboden als onderdeel van Apache Hadoop.
- Spark - Het wordt gebruikt om in-memory-verwerking uit te voeren die veel sneller is dan de Hadoop-kaart vermindert.
Hadoop-providers
Er zijn veel bedrijven die Hadoop-distributies aanbieden. Hieronder zijn de paar beste providers voor Hadoop:
- Cloudera
- Hortonworks
- MapR
Er zijn weinig vereisten om Hadoop te leren. Voorafgaande ervaring in Java en scripttaal is noodzakelijk. Hoewel Hadoop al zijn eigen programmeertalen op hoog niveau heeft, zoals varken en bijenkorf, die de backend-code genereert voor verdere verwerking, is het toch mogelijk om een eigen programma voor het verkleinen van de kaart te maken in elke programmeertaal zoals Ruby, Python, Perl en zelfs C-programmering.
Bigdata en Hadoop zijn erg in trek in de hedendaagse markt. Dit gaat de komende dagen nog meer toenemen. Veel organisaties zijn al naar Hadoop verhuisd en degenen die dat nog niet zijn gaan binnenkort verhuizen. Er is een actueel rapport waarin staat dat grote bedrijven zijn gaan investeren in big data-analyse. Big data marketing voorspelling is altijd in de opwaartse trend en het is helemaal niet van korte duur. Afgezien van al deze functies bieden de banen in Hadoop en big data altijd een hoog loon in vergelijking met andere technologieën.
Top Big Data- en Hadoop-bedrijven
Hieronder staan een paar topbedrijven die het meeste aantal Hadoop-middelen in dienst hebben.
- Yahoo
- Amazone
- Royal Bank of Scotland
- British Airways
- Expedia
- Walmart
Er zijn veel bedrijven die big data-applicaties gebruiken. Dit zijn:
-
Nokia
Het maakt gebruik van Cloudera- en Hadoop-componenten zoals HDFS, HBase, Sqoop, Scribe voor de toepassing. Het gebruikte gebruikersgegevens effectief om de gebruikerservaring te begrijpen en te verbeteren. Het maakt gebruik van gegevensverwerking en complexe analyses voor het bouwen van de kaart met voorspellend verkeer en gelaagde hoogtemodellen.
-
SAS
Het heeft samengewerkt met Hadoop om datawetenschappers te helpen beter inzicht te krijgen door een omgeving te bieden die visuele en interactieve ervaring biedt en zo helpt bij het verkennen van nieuwe trends. De analytische programma's halen betekenisvolle inzichten uit gegevens en de in-memory-technologie helpt snellere gegevenstoegang.
Er zijn ook veel andere bedrijven die big data-platforms gebruiken voor verschillende analyses. Dit zijn vluchtgegevensanalyse van black box in de luchtvaartindustrie, de verschillende analyses in aandelenmarkten, enz.
Voordelen van Haddop
Hieronder staan enkele voordelen van Hadoop
- Schaalbaar - In tegenstelling tot traditionele RDBMS is het een zeer schaalbaar platform omdat het grote datasets kan opslaan in gedistribueerde clusters via parallel werkende hardware.
- Kostenbesparend - De kosten waren te hoog voor RDBMS om gegevens op te slaan die in Hadoop zijn vrijgegeven.
- Snel en flexibel - het biedt gegevens die snel toegankelijk zijn via het gedistribueerde bestandssysteem. Het biedt ook om zakelijke inzichten af te leiden uit semi-gestructureerde en ongestructureerde gegevens.
- Fouttolerant - Telkens wanneer gegevens naar een knooppunt worden verzonden, worden dezelfde gegevens gerepliceerd naar andere knooppunten die toegankelijk zijn in geval van een storing in het eerste knooppunt.
Conclusie - wat is Big Data en Hadoop
Gegevens groeien voortdurend en daarom is er altijd behoefte aan big data en Hadoop om deze gegevens te begrijpen. Om deze reden zullen professionals met Hadoop-vaardigheden de komende dagen altijd ruime kansen vinden en een onmisbare troef zijn voor een organisatie die het bedrijf en hun carrière stimuleert.
Aanbevolen artikelen
Dit is een leidraad geweest voor wat Big Data en Hadoop is. Hier hebben we de basisconcepten en componenten van Big Data en Hadoop besproken. U kunt ook het volgende artikel bekijken voor meer informatie -
- Big Data Analytics-voorbeelden
- Gebruik van Hadoop
- Gids voor datavisualisatie
- Wat is big data-analyse?