

Inleiding tot bijenkorfopdrachten
Hive commando is een datawarehouse-infrastructuurtool die bovenop Hadoop staat om Big data samen te vatten. Het verwerkt gestructureerde gegevens. Het maakt het opvragen en analyseren van gegevens eenvoudiger. Hive-opdracht wordt ook wel 'schema bij lezen' genoemd. Hive verifieert gegevens niet wanneer deze worden geladen, verificatie vindt alleen plaats wanneer een query wordt uitgegeven. Deze eigenschap van Hive maakt het snel voor het eerste laden. Het is als het kopiëren of eenvoudig verplaatsen van een bestand zonder beperkingen of controles. De korf werd voor het eerst ontwikkeld door Facebook. Apache Software Foundation heeft het later overgenomen en verder ontwikkeld.
Dit zijn de componenten van het Hive-commando:
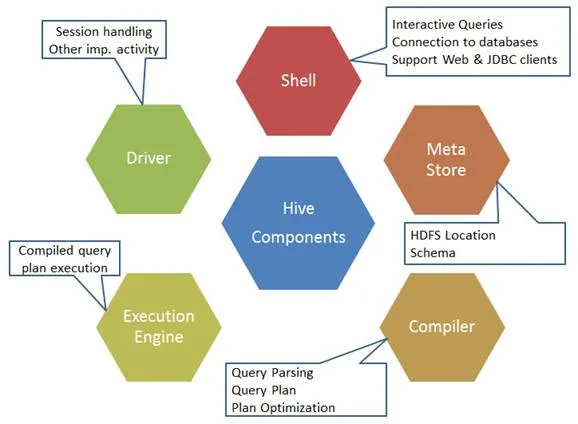
Fig 1. Componenten van Hive
https://www.developer.com/
Dit zijn de onderstaande functies van Hive:
- Hive-winkels zijn onbewerkte en verwerkte datasets in Hadoop.
- Het is ontworpen voor OnLine Transaction Processing (OLTP). OLTP zijn de systemen die hoogvolumegegevens in zeer kortere tijd mogelijk maken zonder afhankelijk te zijn van de enkele server.
- Het is snel, schaalbaar en betrouwbaar.
- De hier opgegeven SQL-type zoektaal wordt HiveQL of HQL genoemd. Dit maakt ETL-taken en andere analyses eenvoudiger.
Fig 2. Bijenkorfeigenschappen
Bronnen afbeeldingen: - Google
Er zijn ook enkele beperkingen van het Hive-commando, die hieronder worden vermeld:
- Hive ondersteunt geen subquery's.
- Hive ondersteunt zeker overschrijven, maar helaas ondersteunt het geen verwijdering en updates.
- Hive is niet ontworpen voor OLTP, maar wordt er wel voor gebruikt.
Om de interactieve shell van de Hive binnen te gaan:
$ HIVE_HOME / bin / bijenkorf
Basic Hive Commando's
-
creëren
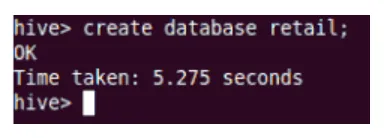
Hiermee wordt de nieuwe database in Hive gemaakt.
-
Laten vallen
De drop zal een tabel uit Hive verwijderen
-
Wijzigen
De opdracht Alter helpt u bij het hernoemen van de tabel of tabelkolommen.
Bijvoorbeeld:
bijenkorf> ALTER TABLE werknemer RENAME NAAR medewerker1;
-
Tonen
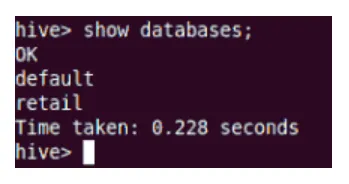
Show commando toont alle databases die zich in Hive bevinden.
-
Beschrijven
De opdracht Beschrijven helpt u bij de informatie over het schema van de tabel.
Tussentijdse bijenkorfopdrachten
Hive verdeelt een tabel in verschillende partities op basis van kolommen. Met behulp van deze partities wordt het eenvoudiger om gegevens op te vragen. Deze partities worden verder onderverdeeld in emmers, om query efficiënt op gegevens uit te voeren.
Met andere woorden, emmers verspreiden gegevens in de set clusters door de hash-code van de sleutel te berekenen die in de query wordt vermeld.
-
Partitie toevoegen
Het toevoegen van partities kan worden bereikt door de tabel te wijzigen. Stel dat u tabel "EMP" hebt, met velden zoals ID, Naam, Salaris, Afd., Aanwijzing en yoj.
bijenkorf> werknemer ALTER TABLE
> PARTITIE TOEVOEGEN (jaar = '2012')
locatie '/ 2012 / part2012';
-
Partitie hernoemen
component> ALTER TABLE werknemer PARTITIE (jaar = '1203')
NAAM VAN DE PARTITIE (Yoj = '1203');
-
Drop Partition
bijenkorf> ALTER TABLE werknemer DROP (ALS BESTAAT)
> PARTITIE (jaar = '1203');
-
Relationele operators
Relationele operatoren bestaan uit een bepaalde set operatoren, die helpt bij het ophalen van relevante informatie.
Bijvoorbeeld: Zeg dat uw "EMP" -tabel er als volgt uitziet:
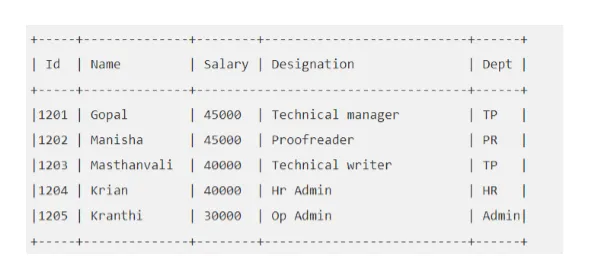
Laten we de Hive-query uitvoeren die ons de werknemer oplevert wiens salaris hoger is dan 30000.
bijenkorf> SELECT * UIT EMP WAAR Salaris> = 40000;
-
Rekenkundige operatoren
Dit zijn operatoren die helpen bij het uitvoeren van rekenkundige bewerkingen op de operanden en die op hun beurt altijd typen getallen retourneren.
Bijvoorbeeld: Om twee nummers toe te voegen, zoals 22 & 33
bijenkorf> SELECT 22 + 33 TOEVOEGEN VAN temp;
-
Logische operator
Deze operatoren moeten logische bewerkingen uitvoeren, die in ruil daarvoor altijd Waar / Onwaar retourneren.
bijenkorf> SELECT * UIT EMP WAAR Salaris> 40000 && Dept = TP;
Geavanceerde bijenkorfopdrachten
-
Visie
Het weergaveconcept in Hive is vergelijkbaar met SQL. De weergave kan worden gemaakt op het moment dat een SELECT-instructie wordt uitgevoerd.
Voorbeeld:
bijenkorf> CREATE VIEW EMP_30000 AS
SELECTEER * VAN EMP
WAAR salaris> 30000;
-
Gegevens laden in tabel
Hive> Laad data lokaal inpath '/home/hduser/Desktop/AllStates.csv' in tabelstaten;
Hier is "Staten" de reeds gemaakte tabel in Hive.
https://www.tutorialspoint.com/hive/
Hive heeft een aantal ingebouwde functies die u helpen uw resultaat op een betere manier op te halen.
Zoals rond, vloer, BIGINT etc.
-
toetreden
De clausule Join kan helpen bij het samenvoegen van twee tabellen op basis van dezelfde kolomnaam.
Voorbeeld:
component> SELECT c.ID, c.NAME, c.AGE, o.AMOUNT
VAN KLANTEN c WORD LID VAN BESTELLINGEN o
AAN (c.ID = o.CUSTOMER_ID);
Alle soorten joins worden ondersteund door Hive: linker buitenste join, rechter buitenste join, volledige buitenste join.
Tips en trucs om bijenkorfopdrachten te gebruiken
Hive maakt gegevensverwerking zo eenvoudig, duidelijk en uitbreidbaar, dat gebruikers minder aandacht besteden aan het optimaliseren van de Hive-zoekopdrachten. Maar aandacht besteden aan enkele dingen tijdens het schrijven van Hive-query, zal zeker veel succes brengen bij het beheren van de werklast en het besparen van geld. Hieronder volgen enkele tips hierover:
- Partities en emmers: Hive is een big data-tool, die op grote datasets kan zoeken. Het schrijven van de query zonder het domein te begrijpen kan echter grote partities in Hive veroorzaken.
Als de gebruiker op de hoogte is van de gegevensset, kunnen relevante en veelgebruikte kolommen in dezelfde partitie worden gegroepeerd. Dit helpt bij het sneller en inefficiënter uitvoeren van de query.
Uiteindelijk is het nee. van mapper- en I / O-bewerkingen worden ook verminderd.
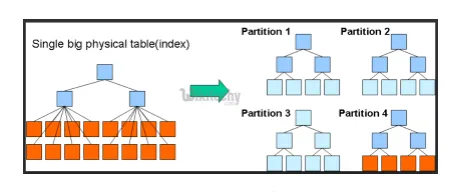
Fig 3. Partitioneren
Bronnen afbeeldingen: Google afbeelding
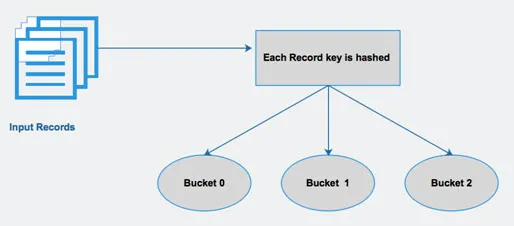
Fig 4 Bucketing
Bronnen afbeeldingen: - Google afbeelding
- Parallelle uitvoering: Hive voert de query in meerdere fasen uit. In sommige gevallen kunnen deze fasen afhankelijk zijn van andere fasen, en daarom kan er niet aan de slag worden gedaan als de vorige fase is voltooid. Onafhankelijke taken kunnen echter parallel worden uitgevoerd om de totale uitvoeringstijd te besparen. Om de parallelle run in Hive in te schakelen:
set hive.exec.parallel = true;
Dit zal dus het clustergebruik verbeteren.
- Blokkeren van steekproeven: door steekproeven van gegevens uit een tabel kunnen zoekopdrachten op gegevens worden onderzocht.
Ondanks het verzet, willen we de dataset liever willekeurig samplen. Block sampling wordt geleverd met verschillende krachtige syntaxis, die helpt bij het bemonsteren van de gegevens op een verschillende manier.
Bemonstering kan worden gebruikt om ca. info uit dataset zoals de gemiddelde afstand tussen oorsprong en bestemming.
Het opvragen van 1% van big data zal bijna het perfecte antwoord geven. Verkenning wordt veel eenvoudiger en effectiever.
Conclusie - Hive-opdrachten
Hive is een abstractie op een hoger niveau bovenop HDFS, die flexibele querytaal biedt. Het helpt bij het opvragen en verwerken van gegevens op een eenvoudiger manier.
Hive kan worden samengeknuppeld met andere Big data-elementen, om de functionaliteit ervan volledig te benutten.
Aanbevolen artikelen
Dit is een gids voor Hive Commands geweest. Hier hebben we basis- en geavanceerde Hive-opdrachten en enkele onmiddellijke Hive-opdrachten besproken. U kunt ook het volgende artikel bekijken voor meer informatie -
- Hive Interview Vragen
- Hive VS Hue - Top 6 nuttige vergelijkingen
- Tableau-opdrachten
- Adobe Photoshop-opdrachten
- ORDER BY-functie gebruiken in Hive
- Download en installeer Hive stap voor stap