
Wat is SVM-algoritme?
SVM staat voor Support Vector Machine. SVM is een bewaakt machine learning-algoritme dat vaak wordt gebruikt voor classificatie- en regressie-uitdagingen. Veelvoorkomende toepassingen van het SVM-algoritme zijn Intrusion Detection System, Handwriting Recognition, Protein Structure Prediction, Detecting Steganography in digital images, etc.
In het SVM-algoritme wordt elk punt weergegeven als een gegevensitem binnen de n-dimensionale ruimte, waarbij de waarde van elk kenmerk de waarde is van een specifieke coördinaat.
Na het plotten is classificatie uitgevoerd door het vinden van een hype-vliegtuig dat twee klassen onderscheidt. Zie onderstaande afbeelding om dit concept te begrijpen.
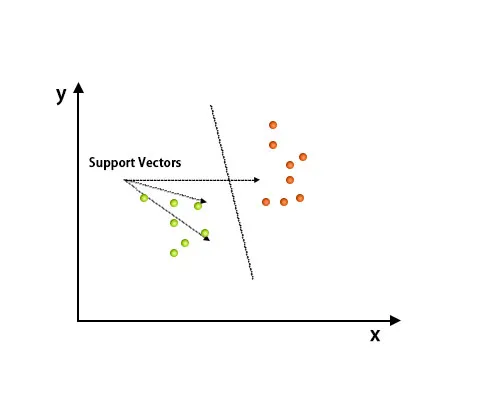
Ondersteuning Vector Machine-algoritme wordt voornamelijk gebruikt om classificatieproblemen op te lossen. Ondersteuningsvectoren zijn niets anders dan de coördinaten van elk gegevensitem. Ondersteuning Vector Machine is een grens die twee klassen onderscheidt met behulp van hyper-plane.
Hoe werkt het SVM-algoritme?
In de bovenstaande sectie hebben we de differentiatie van twee klassen met behulp van hypervlak besproken. Nu gaan we kijken hoe dit SVM-algoritme eigenlijk werkt.
Scenario 1: identificeer het juiste hypervlak
Hier hebben we drie hypervlakken genomen, namelijk A, B en C. Nu moeten we het juiste hypervlak identificeren om ster en cirkel te classificeren.
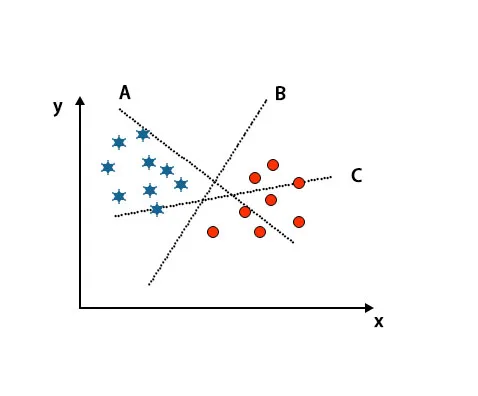
Om het juiste hypervlak te identificeren, moeten we de duimregel kennen. Selecteer hypervlak dat twee klassen onderscheidt. In de bovengenoemde afbeelding onderscheidt hypervlak B twee klassen zeer goed.
Scenario 2: identificeer het juiste hypervlak
Hier hebben we drie hypervlakken genomen, namelijk A, B en C. Deze drie hypervlakken maken al heel goed onderscheid tussen klassen.
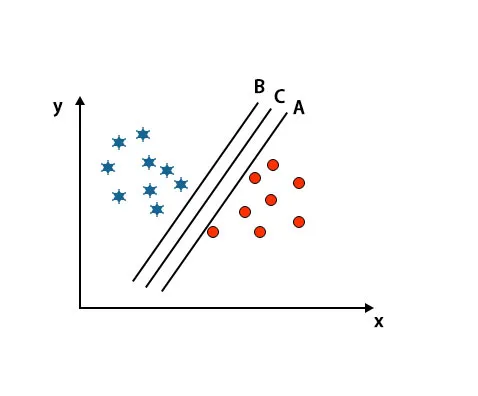
In dit scenario vergroten we de afstand tussen de dichtstbijzijnde gegevenspunten om het juiste hypervlak te identificeren. Deze afstand is niets anders dan een marge. Zie onderstaande afbeelding.
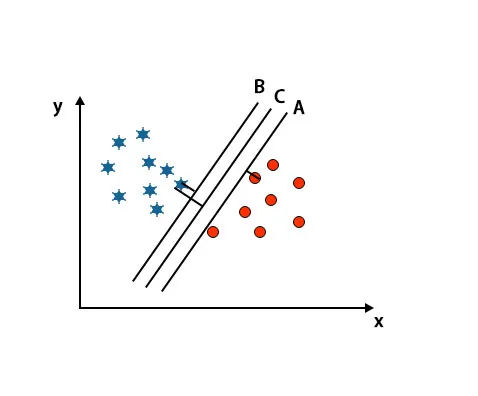
In de bovengenoemde afbeelding is de marge van hypervlak C groter dan het hypervlak A en hypervlak B. Dus in dit scenario is C het juiste hypervlak. Als we het hyperplane met een minimale marge kiezen, kan dit leiden tot verkeerde classificatie. Daarom hebben we gekozen voor hyperplane C met maximale marge vanwege robuustheid.
Scenario 3: identificeer het juiste hypervlak
Opmerking: Volg dezelfde regels als vermeld in de vorige secties om het hypervlak te identificeren.
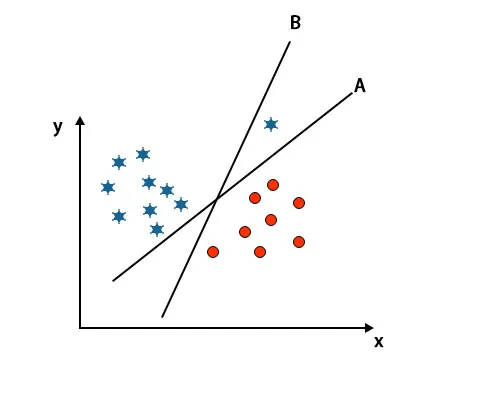
Zoals u in de bovengenoemde afbeelding kunt zien, is de marge van hypervlak B groter dan de marge van hypervlak A, daarom zullen sommigen hypervlak B als een recht selecteren. Maar in het SVM-algoritme selecteert het dat hypervlak dat klassen nauwkeurig classificeert voordat de marge wordt gemaximaliseerd. In dit scenario is hypervlak A allemaal nauwkeurig geclassificeerd en is er een fout met de classificatie van hypervlak B. Daarom is A het juiste hypervlak.
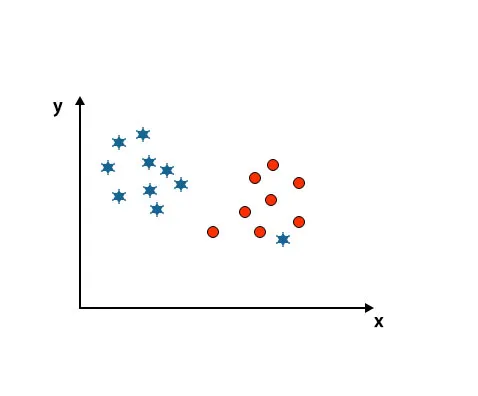
Scenario 4: Classificeer twee klassen
Zoals u kunt zien in de onderstaande afbeelding, zijn we niet in staat om twee klassen te differentiëren met behulp van een rechte lijn, omdat de ene ster als uitbijter ligt in de andere cirkelklasse.
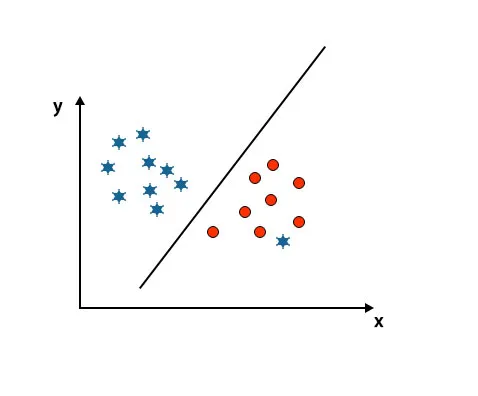
Hier zit een ster in een andere klasse. Voor sterrenklasse is deze ster de uitbijter. Vanwege de robuustheidseigenschap van het SVM-algoritme, zal het het juiste hyperplane vinden met een hogere marge en een uitbijter negeren.
Scenario 5: Fijn hypervlak om klassen te differentiëren
Tot nu toe hebben we lineair hypervlak gekeken. In de onderstaande afbeelding hebben we geen lineair hypervlak tussen klassen.
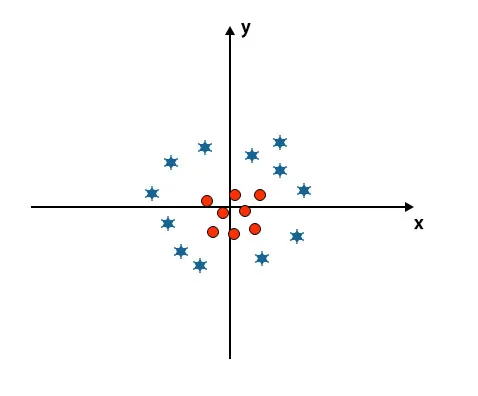
Om deze klassen te classificeren, introduceert SVM enkele extra functies. In dit scenario gaan we deze nieuwe functie z = x 2 + y 2 gebruiken.
Hiermee worden alle gegevenspunten op de x- en z-as uitgezet.

Notitie
- Alle waarden op de z-as moeten positief zijn omdat z gelijk is aan de som van x kwadraat en y kwadraat.
- In de bovengenoemde plot zijn rode cirkels gesloten voor de oorsprong van de x-as en de y-as, waardoor de waarde van z naar beneden gaat en de ster precies het tegenovergestelde van de cirkel is, het is weg van de oorsprong van de x-as en y-as, waardoor de waarde van z naar hoog wordt geleid.
In het SVM-algoritme is het eenvoudig om te classificeren met behulp van een lineair hyperplane tussen twee klassen. Maar de vraag rijst hier of we deze functie van SVM moeten toevoegen om het hypervlak te identificeren. Dus het antwoord is nee, om dit probleem op te lossen heeft SVM een techniek die algemeen bekend staat als een kerneltruc.
Kerneltruc is de functie die gegevens omzet in een geschikte vorm. Er zijn verschillende soorten kernelfuncties die in het SVM-algoritme worden gebruikt, namelijk Polynomiaal, lineair, niet-lineair, Radiale basisfunctie, enz. Hier wordt met behulp van kerneltruc de lage dimensionale invoerruimte omgezet in een hoger-dimensionale ruimte.
Als we naar het hypervlak kijken, de oorsprong van de as en de y-as, ziet het eruit als een cirkel. Zie onderstaande afbeelding.
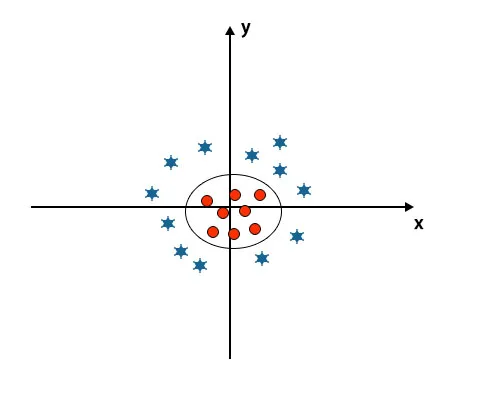
Voordelen van SVM Algorithm
- Zelfs als invoergegevens niet-lineair en niet-scheidbaar zijn, genereren SVM's nauwkeurige classificatieresultaten vanwege de robuustheid.
- In de beslissingsfunctie gebruikt het een subset van trainingspunten die ondersteuningsvectoren worden genoemd en is daarom geheugenefficiënt.
- Het is nuttig om elk complex probleem met een geschikte kernelfunctie op te lossen.
- In de praktijk zijn SVM-modellen algemeen, met minder risico op overfitting in SVM.
- SVM's werken geweldig voor tekstclassificatie en bij het vinden van het beste lineaire scheidingsteken.
Nadelen van SVM Algorithm
- Het werken met grote datasets duurt lang.
- Het is moeilijk om het uiteindelijke model en de individuele impact te begrijpen.
Conclusie
Het is begeleid om vectormachine-algoritme te ondersteunen, wat een machine learning-algoritme is. In dit artikel hebben we in detail besproken wat het SVM-algoritme is, hoe het werkt en de voordelen.
Aanbevolen artikelen
Dit is een gids voor SVM-algoritme geweest. Hier bespreken we het werken met een scenario, voor- en nadelen van SVM Algorithm. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Datamining-algoritmen
- Dataminingstechnieken
- Wat is machinaal leren?
- Hulpmiddelen voor machine leren
- Voorbeelden van C ++ algoritme