

Inleiding tot diep leren
Deep Learning is een van de machine learning-technieken waarmee we computers leren / trainen om te doen wat mensen doen. Bijvoorbeeld, autorijden - diep leren speelt een sleutelrol in de autotechnologie zonder bestuurder door hen in staat te stellen verschillende verkeersborden, verkeersborden, voetgangersborden enz. Te identificeren. Andere belangrijke gebieden van diep leren zijn stembesturing in thuissystemen, mobiele telefoons, draadloze luidsprekers, Alexa, smart TV's enz. Diep leren voor beginners gaat meestal over meerdere abstractieniveaus en representaties waarmee computermodel leert om classificatie van afbeeldingen, geluiden en tekst uit te voeren enz. Diep leermodellen bereiken in sommige modellen betere nauwkeurigheid en prestaties dan mensen. . Over het algemeen worden deze computermodellen getraind door een grote set gegevens die is gelabeld en niet-geëtiketteerd om objecten en neurale netwerken te identificeren die meerdere lagen in elk netwerk hebben.
Wat is diep leren?
Ik zal hieronder uitleggen wat diep leren is in lekentermen: In het algemeen zullen we de hele tijd twee taken bewust of onbewust doen, dwz categoriseren wat we door onze zintuigen voelden (zoals een warme, koude mok enz.) En voorspelling, bijvoorbeeld, voorspelt de toekomstige temperatuur op basis van de vorige temperatuurgegevens. We doen categorisatie- en voorspellingstaken voor verschillende evenementen of taken in ons dagelijks leven, zoals hieronder:
- Het vasthouden van een kopje thee / water / koffie enz. Die warm of koud kan zijn.
- E-mailindeling zoals spam / geen spam.
- Daglicht categorisatie zoals dag of nacht.
- Planning op lange termijn van de toekomst op basis van onze huidige positie en dingen die we hebben - wordt voorspelling genoemd.
- Elk wezen in de wereld zal deze taken in zijn leven uitvoeren, bijvoorbeeld, denk eraan dat dieren zoals kraai een plaats zullen categoriseren om zijn nest te bouwen of niet, een bij zal beslissen over enkele factoren wanneer en waar honing te krijgen, vleermuis zal 's nachts komen en slaapt 's morgens op basis van dag en nacht categorisatie.
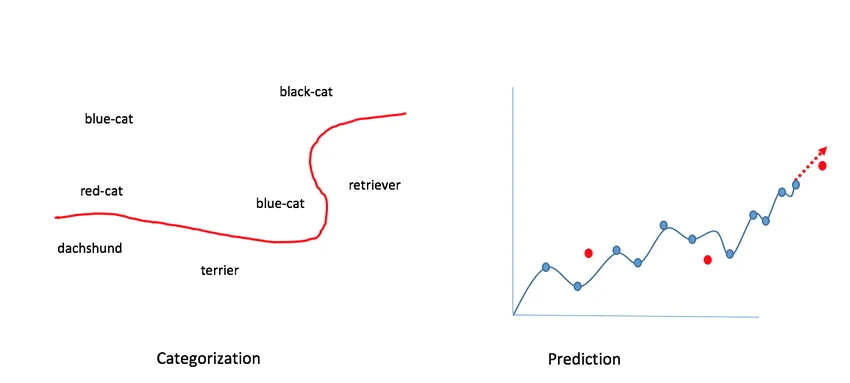
Laten we deze taken categoriseren en voorspelling visualiseren en ze zullen op elkaar lijken zoals in de onderstaande afbeelding. Voor categorisatie doen we categorisatie tussen katten en honden door een lijn te trekken door gegevenspunten en in geval van voorspelling trekken we een lijn door gegevenspunten naar voorspellen wanneer het zal toenemen en afnemen.
1) Indeling
- Over het algemeen om te categoriseren tussen katten en honden, of mannen en vrouwen, trekken we geen lijn in onze hersenen en de positie van honden en katten is willekeurig ter illustratie en het is onnodig om te zeggen hoe we categoriseren tussen katten en honden in onze hersenen zijn veel complexer dan een rode lijn trekken zoals hierboven.
- We zullen categoriseren tussen twee dingen op basis van vormen, grootte, hoogte, uiterlijk enz. En soms zal het moeilijk zijn om te categoriseren met deze functies, zoals een kleine hond met woede en pasgeboren kat, dus het is geen duidelijke categorisatie in katten en honden.
- Zodra we in staat zijn om te categoriseren tussen katten en honden als we kinderen zijn, kunnen we elke hond of kat categoriseren, zelfs als we het nog niet eerder hebben gezien.
2) Voorspelling
- Voor voorspelling op basis van de lijn trekken we gegevenspunten door, als we kunnen voorspellen waar deze het meest waarschijnlijk naar boven of naar beneden gaat.
- De curve is ook een voorspelling voor het passen van nieuwe gegevenspunten binnen het bereik van bestaande gegevenspunten, dwz hoe dicht het nieuwe gegevenspunt bij de curve ligt.
- De gegevenspunten die in de bovenstaande afbeelding (rechterkant) rood zijn, zijn voorbeelden van zowel binnen als buiten het bereik van bestaande gegevenspunten en de curve probeert beide te voorspellen.
Ten slotte worden beide taken, categorisatie en voorspelling op hetzelfde punt beëindigd, dwz een curvy lijn trekken uit gegevenspunten. Als we in staat zijn om het computermodel te trainen om de bochtige lijn te tekenen op basis van gegevenspunten die we klaar zijn, kunnen we dit uitbreiden om het in verschillende modellen toe te passen, zoals het tekenen van een bochtige lijn in driedimensionale vlakken enzovoort. Het bovenstaande kan worden bereikt door een model te trainen met een grote hoeveelheid gelabelde en niet-geëtiketteerde gegevens die deep learning wordt genoemd.
Voorbeelden van diepgaand leren:
Zoals we weten, zijn deep learning en machine learning subsets van kunstmatige intelligentie, maar deep learning-technologie vertegenwoordigt de volgende evolutie van machine learning. Omdat machine learning zal werken op basis van algoritmen en programma's ontwikkeld door mensen, terwijl deep learning leert via een neuraal netwerkmodel dat op dezelfde manier werkt als mensen en waarmee machine of computer de gegevens op een vergelijkbare manier kan analyseren als mensen. Dit wordt mogelijk als we de neurale netwerkmodellen trainen met een enorme hoeveelheid gegevens, omdat gegevens de brandstof of het voedsel vormen voor neurale netwerkmodellen. Hieronder staan enkele voorbeelden van diep leren in de echte wereld.
-
Computer visie:
Computer vision behandelt algoritmen voor computers om de wereld te begrijpen met behulp van beeld- en videogegevens en taken zoals beeldherkenning, beeldclassificatie, objectdetectie, beeldsegmentatie, beeldherstel, enz.
-
Spraak- en natuurlijke taalverwerking:
Natuurlijke taalverwerking gaat over algoritmen die computers in menselijke taal kunnen begrijpen, interpreteren en manipuleren. NLP-algoritmen werken met tekst- en audiogegevens en zetten deze om in audio- of tekstuitvoer. Met NLP kunnen we taken uitvoeren zoals sentimentanalyse, spraakherkenning, taalovergang en natuurlijke taalgeneratie etc.
-
Autonome voertuigen:
Diepgaande leermodellen worden getraind met een enorme hoeveelheid gegevens voor het identificeren van straatnaamborden; sommige modellen zijn gespecialiseerd in het identificeren van voetgangers, het identificeren van mensen enz. voor auto's zonder bestuurder tijdens het rijden.
-
Tekst genereren:
Door gebruik te maken van diepgaande leermodellen die getraind zijn door taal, grammatica en soorten teksten etc. kunnen worden gebruikt om een nieuwe tekst te maken met correcte spelling en grammatica van Wikipedia naar Shakespeare.
-
Afbeelding filteren:
Door diepgaande leermodellen te gebruiken, zoals het toevoegen van kleur aan zwart-witafbeeldingen, kan dit worden gedaan door diepgaande leermodellen die meer tijd kosten als we dit handmatig doen.
Conclusie
Ten slotte is het een overzicht van deep learning-technologie, de toepassingen ervan in de echte wereld. Ik hoop dat je na het lezen van dit artikel goed begrijpt wat diep leren is. Zoals we vandaag weten, is beeldherkenning door machines die door diep leren zijn getraind in sommige gevallen beter dan mensen, dat wil zeggen bij het identificeren van kanker in bloed en tumoren in MRI-scans en Google's alphaGo heeft het spel geleerd en getraind voor zijn 'Go'-match door zijn neurale netwerk te trainen door er steeds weer tegen te spelen.
Aanbevolen artikelen
Dit is een gids geweest voor Wat is diep leren. Hier hebben we de basisconcepten en voorbeelden van diep leren besproken. U kunt ook de volgende artikelen bekijken:
- Carrières in Deep Learnings
- 13 Nuttige Deep Learning-interviewvragen
- Begeleid leren versus diep leren
- Neurale netwerken versus diep leren
- Topvergelijking van diep leren versus machinaal leren