
Introductie van tekstwinning
Tekstwinning - In de context van vandaag is tekst het meest gebruikelijke middel waarmee informatie wordt uitgewisseld. Maar het begrijpen van de betekenis van de tekst is helemaal geen gemakkelijke taak. We hebben een goede tool voor business intelligence nodig die de informatie op een eenvoudige manier helpt te begrijpen.
Wat is tekstwinning
Text Mining is ook bekend als Text Analytics. Het is het proces van het begrijpen van informatie uit een reeks teksten. Text Mining is ontworpen om het bedrijf te helpen waardevolle kennis te vinden uit op tekst gebaseerde inhoud. Deze inhoud kan de vorm hebben van een Word-document, e-mail of berichten op sociale media.
Text Mining is het gebruik van geautomatiseerde methoden om de beschikbare kennis in de tekstdocumenten te begrijpen.
Text Mining kan ook worden gebruikt om de computer gestructureerde of ongestructureerde gegevens te laten begrijpen. Kwalitatieve gegevens of ongestructureerde gegevens zijn gegevens die niet in aantallen kunnen worden gemeten. Deze gegevens bevatten meestal informatie zoals kleur, textuur en tekst. Kwantitatieve gegevens of gestructureerde gegevens zijn gegevens die gemakkelijk kunnen worden gemeten.
Text mining is een interdisciplinair veld dat het ophalen van informatie, datamining, machine learning, statistieken en andere omvat. Text Mining is een iets ander veld dan datamining.
Voordelen van Text Mining
Het gebruik van Text Mining heeft veel voordelen. Ze worden hieronder vermeld
- Het bespaart tijd en middelen en presteert efficiënter dan menselijke hersenen.
- Het helpt om meningen in de loop van de tijd te volgen
- Text Mining helpt om de documenten samen te vatten
- Tekstanalyse helpt om concepten uit tekst te extraheren en op een eenvoudigere manier te presenteren
- De tekst die is geïndexeerd met behulp van Text mining, kan worden gebruikt in voorspellende analyses
- U kunt elke vocabulaire aansluiten om de terminologie in uw interessegebied te gebruiken
Gebruik van tekstwinning
- De namen van verschillende entiteiten en relaties tussen de tekst kunnen eenvoudig worden gevonden met behulp van verschillende technieken.
- Het helpt om patronen te extraheren uit een grote hoeveelheid ongestructureerde gegevens
- Systematisch literatuuronderzoek - het kan gaan voor diepgaand onderzoek van tekst, sleutelthema's ontdekken en de herhaalde termen of tekst en de populaire onderwerpen gedurende een bepaalde periode benadrukken.
- Hypothese testen - Door middel van text mining kan een bepaalde hypothese worden getest om te zien of het document de hypothese bevestigt of ontkent. Meestal wordt eerst een gevestigde overtuiging over het document getest.
Effectief oplossingen voor zakelijke problemen ontwikkelen. Leer bedrijfsvereisten te definiëren, analyseren en documenteren. Onderzoek bedrijfsactiviteiten om ze efficiënter te maken.
Het belang van tekstwinning
- Text Mining maakt betere en slimme besluitvorming mogelijk
- Het helpt bij het oplossen van kennisontdekkingsproblemen in verschillende bedrijfsgebieden
- Door middel van text mining kunt u de gegevens eenvoudig op vele manieren visualiseren, zoals html-tabellen, grafieken, grafieken en andere
- Het is een geweldige productiviteitstool. Het geeft betere resultaten sneller dan enig ander hulpmiddel.
- Text mining tool wordt gebruikt door zowel grote als kleinschalige organisaties die kennisgedreven organisaties zijn.
Toepassingen van Text Mining
-
Analyse van open antwoorden op enquêtes
Open enquêtevragen helpen de respondenten om zonder beperkingen hun mening of mening te geven. Dit zal helpen om meer te weten te komen over de meningen van klanten dan te vertrouwen op gestructureerde vragenlijsten. Text mining kan worden gebruikt om dergelijke informatie in de vorm van tekst te analyseren.
-
Automatische verwerking van berichten, e-mails
Tekstwinning wordt ook hoofdzakelijk gebruikt om de tekst te classificeren. Text Mining kan worden gebruikt om onnodige e-mail te filteren met behulp van bepaalde woorden of woordgroepen. Dergelijke e-mails zullen dergelijke e-mails automatisch als spam verwijderen. Een dergelijk automatisch systeem voor het classificeren en filteren van geselecteerde e-mails en het verzenden van de overeenkomstige afdeling gebeurt met behulp van het Text Mining-systeem. Text Mining stuurt ook een waarschuwing naar de e-mailgebruiker om de e-mails met dergelijke aanstootgevende woorden of inhoud te verwijderen.
-
Analyse van garantie- of verzekeringsclaims
In de meeste bedrijfsorganisaties wordt informatie voornamelijk in de vorm van tekst verzameld. In een ziekenhuis kunnen de patiëntinterviews bijvoorbeeld kort in tekstvorm worden verteld en de rapporten zijn ook in de vorm van tekst. Deze notities worden nu elektronisch per dag verzameld, zodat ze gemakkelijk kunnen worden overgezet naar algoritmen voor tekstmining. Deze gegevens kunnen vervolgens worden gebruikt om de werkelijke situatie te diagnosticeren.
-
Concurrenten onderzoeken door hun websites te crawlen
Een ander belangrijk toepassingsgebied van Text Mining is het verwerken van de inhoud van webpagina's in een bepaald domein. Op deze manier vindt het text mining-systeem automatisch een lijst met termen die op de site worden gebruikt. Op deze manier kan men de belangrijkste termen vinden die op de website worden gebruikt. Op deze manier kan men de capaciteiten van de concurrenten kennen die u kunnen helpen om zaken efficiënt te leveren.
De andere toepassingen van Text Mining omvatten het volgende
- Bedrijfsinformatie
- E Ontdekking
- Bio-informatica
- Records management
- Nationale veiligheid of inlichtingen werken
- Social Media Monitoring
Technieken die worden gebruikt in tekstwinning
Er zijn vijf basistechnologieën gebruikt in het Text Mining-systeem. Ze worden hieronder in detail besproken
-
Informatie-extractie
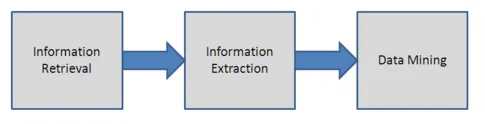
Dit wordt gebruikt om de ongestructureerde tekst te analyseren door de belangrijke woorden te vinden en de onderlinge relaties te vinden. In deze techniek wordt het proces van patroonvergelijking gebruikt om de volgorde in tekst te achterhalen. Het helpt bij het transformeren van de ongestructureerde tekst in gestructureerde vorm. De informatie-extractietechniek omvat taalverwerkingsmodules. Dit wordt meestal gebruikt wanneer er een grote hoeveelheid gegevens is. Het proces van informatie-extractie wordt uitgelegd in de onderstaande afbeelding.
-
categorisatie
Categorisatietechniek classificeert het tekstdocument onder een of meer categorieën. Het is gebaseerd op voorbeelden van input-output om de classificatie uit te voeren. Het categorisatieproces omvat voorbewerking, indexering, dimensionale reductie en classificatie. De tekst kan worden gecategoriseerd met behulp van technieken zoals Naive Bayesian classifier, Decision tree, Dichtstbijzijnde Neighbor-classifier en Support Vendor Machines.
-
clustering
Clustermethode wordt gebruikt om tekstdocumenten met vergelijkbare inhoud te groeperen. Het heeft partities die clusters worden genoemd en elke partitie zal een aantal documenten met vergelijkbare inhoud hebben. Clustering zorgt ervoor dat geen enkel document wordt weggelaten uit de zoekopdracht en het leidt alle documenten af die vergelijkbare inhoud hebben. K-middelen is de vaak gebruikte clusteringstechniek. Deze techniek vergelijkt ook elk cluster en zoekt uit hoe goed het document met elkaar is verbonden. Bedrijven gebruiken deze techniek om een database met duizenden vergelijkbare documenten te maken.
-
visualisatie
Visualisatietechniek wordt gebruikt om het proces van het vinden van relevante informatie te vereenvoudigen. Deze techniek gebruikt tekstvlaggen om documenten of een groep documenten weer te geven en gebruikt kleuren om de compactheid aan te geven. Visualisatietechniek helpt tekstuele informatie op een aantrekkelijkere manier weer te geven. De onderstaande afbeelding geeft de visualisatietechniek weer
-
Summarization
Een samenvattingstechniek helpt de lengte van het document te verkorten en de details van de documenten kort samen te vatten. Het laat het document voor de gebruikers werken en begrijpt de inhoud in één oogopslag. De samenvatting vervangt de volledige set documenten. Het vat een groot tekstdocument gemakkelijk en snel samen. Mensen nemen meer tijd om het document te lezen en vervolgens samen te vatten, maar deze techniek maakt het erg snel. Het helpt om belangrijke punten in een document te markeren. Samenvatting van het proces wordt weergegeven in de onderstaande afbeelding.
Methoden en modellen die worden gebruikt bij tekstwinning
Op basis van het ophalen van informatie heeft Text Mining vier hoofdmethoden
-
Op termijn gebaseerde methode (TBM)
Term in een document betekent een woord dat een semantische betekenis heeft. Bij deze methode wordt de volledige set documenten geanalyseerd op basis van de looptijd. Een belangrijk nadeel van deze methode is het probleem van synoniemen en polysemie. Synoniem is waar meerdere woorden dezelfde betekenis hebben. Polysemie is waar een enkel woord meer betekenissen heeft.
-
Phrase Based Method (PBM)
In deze methode wordt het document geanalyseerd op basis van de zinnen die minder duidelijk zijn voor meer betekenissen en discriminerend. De nadelen van deze methode omvatten
- Ze hebben inferieure statistische eigenschappen ten opzichte van termen
- Ze hebben een lage frequentie van voorkomen
- Ze hebben een groot aantal luidruchtige zinnen
-
Concept Based Method (CBM)
In deze methode wordt het document geanalyseerd op basis van zin en documentniveau. In deze methode zijn er drie hoofdcomponenten. Het eerste onderdeel onderzoekt het betekenisvolle deel van de zinnen. De tweede component produceert een conceptuele ontologische grafiek om de structuren te verklaren. De derde component extraheert topconcepten op basis van de eerste twee componenten. Deze methode kan onderscheid maken tussen de belangrijke en onbelangrijke woorden.
-
Patroontaxonomiemethode (PTM)
In deze methode wordt het document geanalyseerd op basis van de patronen. Patronen in een document kunnen worden ontdekt met behulp van dataminingtechnieken zoals associatieregel mining, sequentiële patroon mining, frequent item set mining en gesloten patroon mining. Deze methode gebruikt twee processen - patroonimplementatie en patroonevolutie. Deze methode heeft bewezen beter te presteren dan alle andere modellen of methoden.
Hoe werkt Text Mining
Nu had je moeten begrijpen dat text mining het mogelijk maakt om de tekst beter te begrijpen dan wat dan ook. Text Mining-systeem maakt een uitwisseling van woorden uit ongestructureerde gegevens in numerieke waarden. Text mining helpt patronen en relaties te identificeren die binnen een grote hoeveelheid tekst bestaan. Text mining maakt vaak gebruik van computationele algoritmen om tekstuele informatie te lezen en te analyseren. Zonder text mining zal het moeilijk zijn om de tekst gemakkelijk en snel te begrijpen. Tekst kan op een meer systematische en uitgebreide manier worden gedolven en de informatie over het bedrijf kan automatisch worden vastgelegd. De stappen in het tekstmijnproces worden hieronder weergegeven.
-
Stap 1: Informatie ophalen
Dit is de eerste stap in het proces van datamining. Deze stap omvat de hulp van een zoekmachine om de verzameling tekst te achterhalen die ook wel corpus van teksten wordt genoemd en die mogelijk moet worden geconverteerd. Deze teksten moeten ook worden samengebracht in een bepaald formaat dat nuttig zal zijn voor de gebruikers om te begrijpen. Gewoonlijk is XML de standaard voor text mining
-
Stap 2: Natuurlijke taalverwerking
Met deze stap kan het systeem grammaticale analyse van een zin uitvoeren om de tekst te lezen. Het analyseert ook de tekst in structuren.
-
Stap 3: Informatie-extractie
Dit is de tweede fase waarin de betekenis van een bepaalde tekstmarkering wordt bepaald. In deze fase wordt een metagegevens over de tekst toegevoegd aan de database. Het omvat ook het toevoegen van namen of locaties aan de tekst. Met deze stap kan de zoekmachine de informatie ophalen en de relaties tussen de teksten achterhalen met behulp van hun metagegevens.
-
Stap 4: Datamining
De laatste fase is datamining met behulp van verschillende tools. Deze stap vindt de overeenkomsten tussen de informatie met dezelfde betekenis die anders moeilijk te vinden zal zijn. Text Mining is een hulpmiddel dat het onderzoeksproces stimuleert en helpt bij het testen van de vragen.
Text Mining bevat de volgende lijst met elementen
- Categorisatie van tekst
- Tekstclustering
- Concept / entiteit extractie
- Korrelige taxonomieën
- Sentiment analyse
- Samenvatting van het document
- Modellering van entiteitsrelaties
Uitdagingen voor tekstwinning
De belangrijkste uitdaging voor het Text Mining-systeem is de natuurlijke taal. De natuurlijke taal wordt geconfronteerd met het probleem van dubbelzinnigheid. Ambiguïteit betekent één term met verschillende betekenissen, waarbij één zin op verschillende manieren wordt geïnterpreteerd en als gevolg daarvan verschillende betekenissen worden verkregen.
Een andere beperking is dat bij het gebruik van het informatiesysteem het semantische analyse vereist. Hierdoor wordt de volledige tekst niet gepresenteerd, maar slechts een beperkt deel van de tekst aan de gebruikers. Maar tegenwoordig is er behoefte aan meer tekstbegrip.
Text Mining heeft ook beperkingen met betrekking tot auteursrechtwetgeving. Er zijn veel beperkingen in text mining van een document. Meestal omvat het de rechten van de auteursrechthouders. De meeste teksten worden niet als open source gevonden en in dergelijke gevallen zijn machtigingen vereist van de respectieve auteurs, uitgevers en andere verbonden partijen.
Nog een beperking is dat text mining geen nieuwe feiten oplevert en het is geen eindproces.
Conclusie
Tekstmining of tekstanalyse is een bloeiende technologie, maar de resultaten en diepgang van de analyse variëren van bedrijf tot bedrijf. Een organisatie kan text mining gebruiken om kennis op te doen over inhoudspecifieke waarden.