

Inleiding tot datamining
Dit is een data mining-methode die wordt gebruikt om data-elementen in vergelijkbare groepen te plaatsen. Cluster is de procedure waarbij gegevensobjecten in subklassen worden verdeeld. Clusterkwaliteit is afhankelijk van de methode die we hebben gebruikt. Clustering wordt ook datasegmentatie genoemd omdat grote datagroepen worden gedeeld door hun overeenkomst.
Wat is clustering in datamining?
Clustering is het groeperen van specifieke objecten op basis van hun kenmerken en hun overeenkomsten. Wat datamining betreft, verdeelt deze methodiek de gegevens die het best geschikt zijn voor de gewenste analyse met behulp van een speciaal join-algoritme. Met deze analyse kan een object geen deel uitmaken van of strikt deel uitmaken van een cluster, wat de harde partitie van dit type wordt genoemd. Soepele partities suggereren echter dat elk object in dezelfde mate tot een cluster behoort. Meer specifieke divisies kunnen worden gemaakt, zoals objecten van meerdere clusters, een enkele cluster kan worden gedwongen om deel te nemen of zelfs hiërarchische bomen kunnen in groepsrelaties worden geconstrueerd. Dit bestandssysteem kan op verschillende manieren worden opgezet op basis van verschillende modellen. Deze onderscheidende algoritmen zijn van toepassing op elk model en onderscheiden zowel hun eigenschappen als hun resultaten. Een goed clusteringalgoritme is in staat om het cluster onafhankelijk van de clustervorm te identificeren. Er zijn 3 basisfasen van clusteringalgoritme die hieronder worden weergegeven
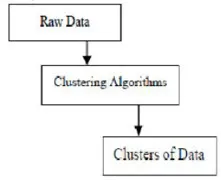
Clustering van algoritmen in datamining
Afhankelijk van de recent beschreven clustermodellen, kunnen veel clusters worden gebruikt om informatie in een set gegevens op te delen. Het moet gezegd worden dat elke methode zijn eigen voor- en nadelen heeft. De selectie van een algoritme is afhankelijk van de eigenschappen en de aard van de gegevensset.
Clustermethoden voor datamining kunnen worden weergegeven zoals hieronder
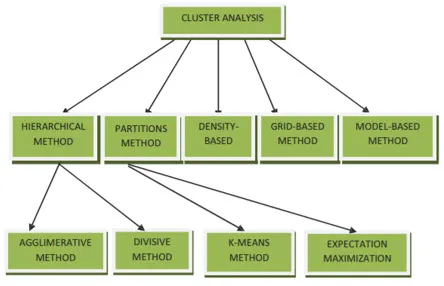
- Op partities gebaseerde methode
- Op dichtheid gebaseerde methode
- Centroid-gebaseerde methode
- Hiërarchische methode
- Op raster gebaseerde methode
- Modelgebaseerde methode
1. Partitionering gebaseerde methode
Het partitie-algoritme verdeelt gegevens in vele subsets.
Laten we aannemen dat het partitioneringsalgoritme een partitie van gegevens bouwt omdat k en n zijn objecten aanwezig zijn in de database. Daarom wordt elke partitie weergegeven als k ≤ n.
Dit geeft een idee dat de classificatie van de gegevens in k groepen is, die hieronder kunnen worden getoond
Figuur 1 toont originele punten in clustering

Figuur 2 toont partitieclustering na toepassing van een algoritme
Dit geeft aan dat elke groep ten minste één object heeft en dat elk object tot exact één groep moet behoren.
2. Op dichtheid gebaseerde methode
Deze algoritmen produceren clusters op een bepaalde locatie op basis van de hoge dichtheid van deelnemers aan de gegevensset. Het verzamelt enig bereikbegrip voor groepsleden in clusters tot een dichtheidsstandaardniveau. Dergelijke processen kunnen minder presteren bij het detecteren van de oppervlakten van de groep.
3. Centroid-gebaseerde methode
Naar bijna elk cluster wordt verwezen door een vector van waarden in dit type os-groeperingstechniek. In vergelijking met andere clusters maakt elk object deel uit van de cluster met een minimaal waardeverschil. Het aantal clusters moet vooraf worden gedefinieerd en dit is het grootste algoritmeprobleem van dit type. Deze methodologie komt het dichtst bij het onderwerp identificatie en wordt veel gebruikt voor optimalisatieproblemen.
4. Hiërarchische methode
De methode maakt een hiërarchische ontleding van een gegeven set gegevensobjecten. Op basis van hoe de hiërarchische ontbinding wordt gevormd, kunnen we hiërarchische methoden classificeren. Deze methode wordt als volgt gegeven
- Agglomeratieve aanpak
- Deelingsaanpak
Agglomerative Approach is ook bekend als Button-up Approach. Hier beginnen we met elk object dat een afzonderlijke groep vormt. Het blijft objecten of groepen dicht bij elkaar fuseren
Divisive Approach staat ook bekend als de Top-Down Approach. We beginnen met alle objecten in dezelfde cluster. Deze methode is star, dat wil zeggen dat deze nooit meer ongedaan kan worden gemaakt zodra een fusie of deling is voltooid
5. Op raster gebaseerde methode
Op rasters gebaseerde methoden werken in de objectruimte in plaats van de gegevens in een raster te verdelen. Raster is verdeeld op basis van kenmerken van de gegevens. Door deze methode te gebruiken, zijn niet-numerieke gegevens eenvoudig te beheren. Gegevensvolgorde heeft geen invloed op de verdeling van het raster. Een belangrijk voordeel van een op raster gebaseerd model, biedt een hogere uitvoeringssnelheid.
Voordelen van hiërarchische clustering zijn als volgt
- Het is van toepassing op elk kenmerktype.
- Het biedt flexibiliteit met betrekking tot het niveau van granulariteit.
6. Modelgebaseerde methode
Deze methode maakt gebruik van een verondersteld model op basis van kansverdeling. Door de dichtheidsfunctie te clusteren, lokaliseert deze methode de clusters. Het geeft de ruimtelijke verdeling van de datapunten weer.
Toepassing van clustering in datamining
Clustering kan op veel gebieden helpen, zoals in de biologie, planten en dieren die zijn geclassificeerd op basis van hun eigenschappen en in marketing. Clustering helpt klanten van een bepaald klantenbestand met vergelijkbaar gedrag te identificeren. In veel toepassingen, zoals marktonderzoek, patroonherkenning, gegevens- en beeldverwerking, wordt de clusteranalyse in grote aantallen gebruikt. Clustering kan adverteerders in hun klantenbestand ook helpen om verschillende groepen te vinden. En hun klantengroepen kunnen worden bepaald door patronen te kopen. In de biologie wordt het gebruikt voor het bepalen van taxonomieën van planten en dieren, voor het categoriseren van genen met vergelijkbare functionaliteit en voor inzicht in populatie-inherente structuren. In een aardobservatiedatabase maakt clustering het ook gemakkelijker om gebieden van vergelijkbaar gebruik in het land te vinden. Het helpt om groepen huizen en appartementen te identificeren op type, waarde en bestemming van huizen. Het clusteren van documenten op internet is ook nuttig voor het ontdekken van informatie. De clusteranalyse is een hulpmiddel om inzicht te krijgen in de verdeling van gegevens om de kenmerken van elk cluster als een datamining-functie te observeren.
Conclusie
Clustering is belangrijk in datamining en de analyse ervan. In dit artikel hebben we gezien hoe clustering kan worden gedaan door verschillende clusteringalgoritmen en de toepassing ervan in het echte leven toe te passen.
Aanbevolen artikel
Dit is een gids geweest voor Wat is clustering in datamining. Hier hebben we de concepten, definitie, functies, toepassing van Clustering in Data Mining besproken. U kunt ook onze andere voorgestelde artikelen doornemen voor meer informatie -
- Wat is gegevensverwerking?
- Hoe word ik een data-analist?
- Wat is SQL-injectie?
- Definitie van wat is SQL Server?
- Overzicht van datamining-architectuur
- Clustering in machine learning
- Hiërarchisch clusteringalgoritme
- Hiërarchische clustering | Agglomerative & Divisive Clustering