
Inleiding tot Hive Group door
Groeperen op zoals de naam al doet vermoeden, het record wordt gegroepeerd dat aan bepaalde criteria voldoet. In dit artikel zullen we de groep van HIVE bekijken. In legacy RDBMS zoals MySQL, SQL, etc, groeperen is een van de oudste clausules die worden gebruikt. Nu heeft het zijn plaats op een vergelijkbare manier gevonden in bestandsgebaseerde gegevensopslag, bekend als HIVE.
We weten dat de Hive veel oudere RDBMS heeft overtroffen bij het verwerken van enorme gegevens zonder dat er een cent wordt uitgegeven aan leveranciers om de databases en servers te onderhouden. We moeten alleen HDFS configureren om bijenkorf te verwerken. Over het algemeen gaan we naar tabellen, omdat de eindgebruiker vanuit zijn structuur kan interpreteren en deze kan opvragen omdat bestanden voor hen onhandig zijn. Maar we moesten dit doen door de leveranciers te betalen om servers te leveren en onze gegevens in de vorm van tabellen te onderhouden. Dus Hive biedt het kosteneffectieve mechanisme waarbij het voordeel haalt van op bestanden gebaseerde systemen (de manier waarop de component zijn gegevens opslaat) en tabellen (tabelstructuur waar de eindgebruikers naar kunnen zoeken).
Groeperen op
Groeperen op basis van de gedefinieerde kolommen uit de componenttabel om de gegevens te groeperen. Overweeg bijvoorbeeld dat je een tabel hebt met de censusgegevens van elke stad van alle staten waar plaatsnaam en staatnaam een van de kolommen is. Als we nu in de query groeperen op staten, worden alle gegevens uit verschillende steden van een bepaalde staat gegroepeerd en kunt u de gegevens nu beter visualiseren voordat de groep werd toegepast.
Syntaxis van Hive Group door
De algemene syntaxis van de group by-clausule is als volgt:
SELECT (ALL | DISTINCT) select_expr, select_expr, …
FROM table_reference
(WHERE where_condition) (GROUP BY col_list) (HAVING having_condition) (ORDER BY col_list)) (LIMIT number);
of voor eenvoudiger vragen,
from Group By
Select department, count(*) from the university.college Group By department;
Hier verwijst de afdeling naar een van de kolommen van de hogeschooltabel die aanwezig is in de universitaire database en de waarde ervan is verschillend in afdelingen zoals kunst, wiskunde, engineering, enz. Laten we nu eens een voorbeeld bekijken om groep door te demonstreren.
Ik heb een voorbeeldtabel deck_of_cards gemaakt om de groep aan te tonen. De instructie create create is als volgt:
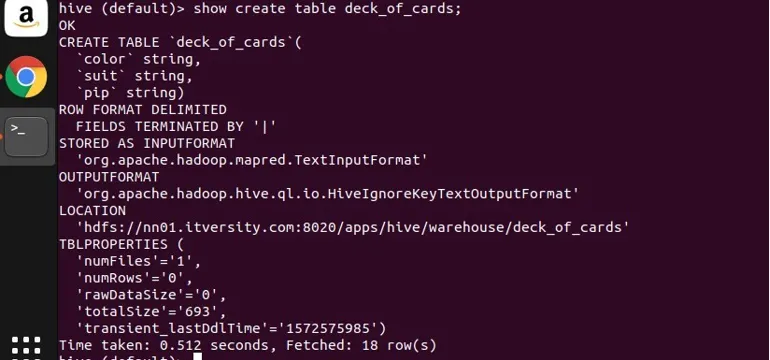
je kunt van bovenaf zien dat het drie tekenreekskolommen kleur, kleur en pip heeft. Laat me een vraag schrijven om de gegevens op kleur te groeperen en het aantal te krijgen.
select color, count(*) from deck_of_cards group by color;
Hive neemt in principe de bovenstaande query om het te converteren naar het map-reduce programma door overeenkomstige Java-code en jar-bestand te genereren en voert het vervolgens uit. Dit proces kan wat tijd kosten, maar het kan zeker de big data verwerken in vergelijking met traditionele RDBMS. Zie de onderstaande schermafbeelding met het gedetailleerde logboek voor het uitvoeren van de bovenstaande query.
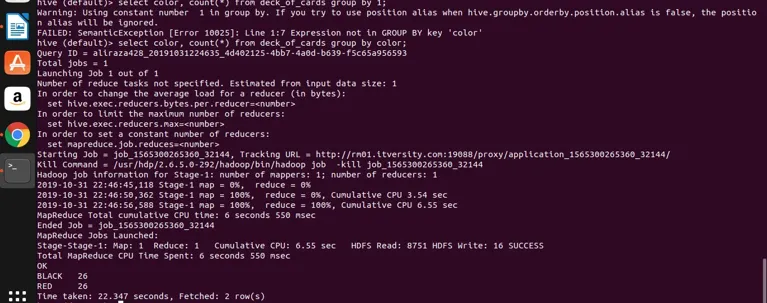
je kunt zien dat ZWART 26 is en ROOD 26 is.
laten we nu de groepering op twee kolommen toepassen (kleur en kleur en groepstelling krijgen) en het resultaat hieronder bekijken.
Select color, suit, count(*) from deck_of_cards group by color, suit
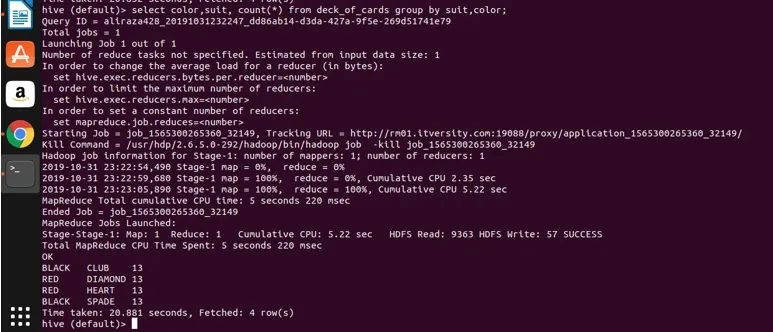
Kortom, er zijn vier verschillende groepen boven Club, Spade met een zwarte kleur en Diamond en een hart met een rode kleur.
Het resultaat van groep opslaan op oorzaak in een andere tabel
Hive biedt ook, net als elke andere RDBMS, de mogelijkheid om de gegevens in te voegen met tabelinstructies. Laten we eens kijken naar het opslaan van het resultaat van een geselecteerde uitdrukking met behulp van een groep in een andere tabel. Laat me de bovenstaande query zelf gebruiken waar ik twee kolommen in groep heb gebruikt door.
create table cards_group_by
as
select color, suit, count(*) from deck_of_cards
group by color, suit;
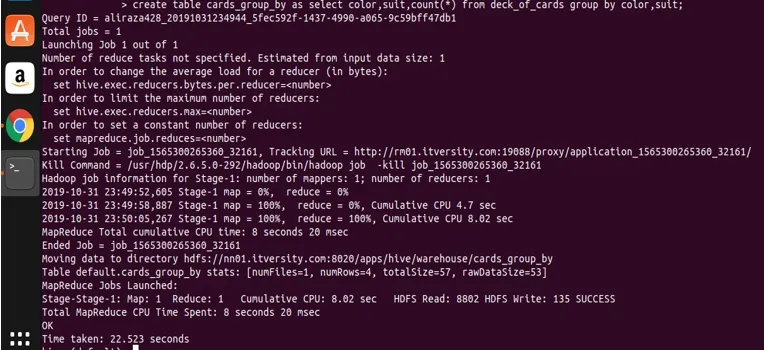
laten we nu een query uitvoeren op de gemaakte tabel om de gegevens te bekijken en te valideren.

Laten we nu het resultaat van de groep beperken door een clausule te gebruiken. Zoals getoond in de generieke syntaxis kunnen we beperkingen op de groep toepassen door het gebruik van. Hier gebruik ik de tabel ordser_items en de structuur is als volgt uit de beschrijf-instructie.
hive (retail_db_ali)> describe order_items;
OK
order_item_id int
order_item_order_id int
order_item_product_id int
order_item_quantity tinyint
order_item_subtotal float
order_item_product_price float
Time taken: 0.387 seconds, Fetched: 6 row(s)
select order_item_id, order_item_order_id from order_items group by order_item_id, order_item_order_id having order_item_order_id=5;
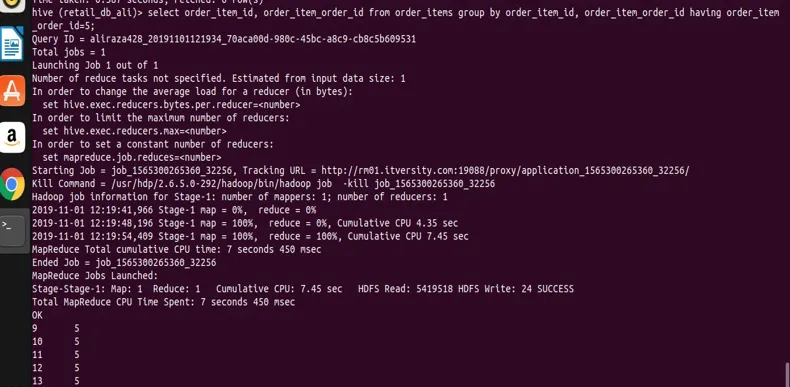
u kunt aan het resultaat de screenshot zien dat we alleen records hebben met order_item_order_id waarde 5.
Groeperen op samen met Case Statement
Laten we nu eens kijken naar beetje complexe zoekopdrachten met de CASE-instructies bij de groep by. We passen dit toe op de tabel order_items. We zullen hieronder zien dat we de niet-aggregerende kolommen kunnen categoriseren waarop we de groep niet rechtstreeks op clausule kunnen toepassen.
Select
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end
as order_profits,
count(*) from order_items
group by
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end;
laten we het uitvoeren in de bijenkorf voor resultaten
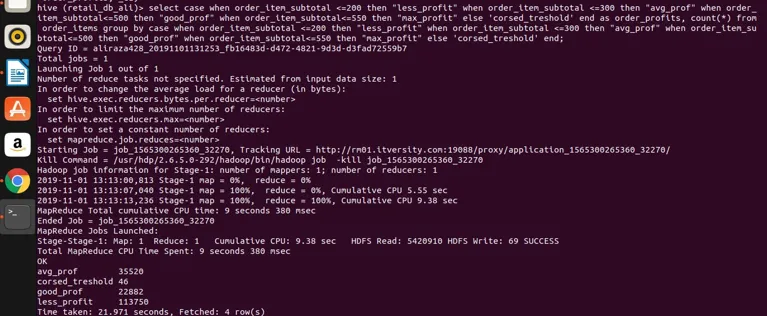
Conclusie - Hive Group By
dus we kunnen zien dat we het order_item_subtotaal in vier verschillende categorieën hebben gegroepeerd (als u opmerkt dat order_item_subtotal een niet-aggregerende kolom is en dat directe groep er niet op kan worden toegepast) en we hebben ze gegroepeerd en hebben hun tellingen ook voor de waarden die voldoen aan het bereik zoals gedefinieerd in de select-expressie. Hier is de eenvoudige regel als de kolom niet-aggregeert en onze select-expressie complex is, wat er ook in de select-expressie is dat ook in de group by clause-expressie aanwezig moet zijn. We hebben dus gezien hoe een beroemde clausule RDBMS-clausule door ook zonder beperkingen op de component kan worden toegepast. Het kan worden toegepast op eenvoudige geselecteerde uitdrukkingen. Combineer en filter expressies, voeg expressies en complexe CASE-expressies samen.
Aanbevolen artikelen
Dit is een gids voor Hive Group By. Hier bespreken we de groep door, syntaxis, voorbeelden van de bijenkorfgroep met verschillende voorwaarden en implementatie. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Sluit zich aan bij Hive
- Wat is een bijenkorf?
- Bijenkorf architectuur
- Bijenkorffunctie
- Bijenkorf sorteren op
- Bijenkorfinstallatie
- Top 6 soorten joins in MySQL met voorbeelden