
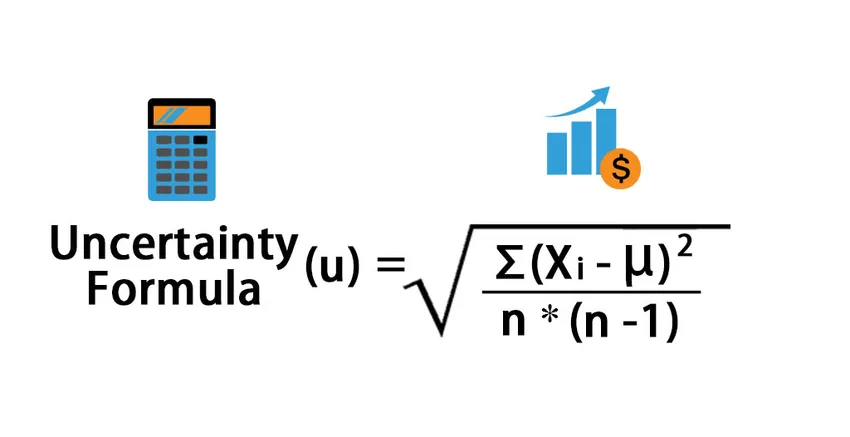
Onzekerheidsformule (inhoudsopgave)
- Formule
- Voorbeelden
Wat is onzekerheidsformule?
In statistisch taalgebruik wordt de term 'onzekerheid' geassocieerd met een meting waarbij het verwijst naar de verwachte variatie van de waarde, die is afgeleid van een gemiddelde van meerdere meetwaarden, van het werkelijke gemiddelde van de gegevensverzameling of meetwaarden. Met andere woorden, de onzekerheid kan worden beschouwd als de standaardafwijking van het gemiddelde van de gegevensverzameling. De formule voor onzekerheid kan worden afgeleid door de vierkanten van de afwijking van elke variabele van het gemiddelde op te tellen, vervolgens het resultaat te delen door het product van het aantal metingen en het aantal metingen min één en vervolgens de vierkantswortel van het resultaat te berekenen . Wiskundig wordt de onzekerheidsformule weergegeven als,
Uncertainty (u) = √ (∑ (x i – μ) 2 / (n * (n – 1)))
Waar,
- x i = i e lezing in de gegevensset
- μ = gemiddelde van de gegevensset
- n = Aantal metingen in de gegevensset
Voorbeelden van onzekerheidsformule (met Excel-sjabloon)
Laten we een voorbeeld nemen om de berekening van Onzekerheid op een betere manier te begrijpen.
U kunt deze Excel-sjabloon voor onzekerheidsformules hier downloaden - Excel-sjabloon voor onzekerheidsformulesOnzekerheidsformule - Voorbeeld # 1
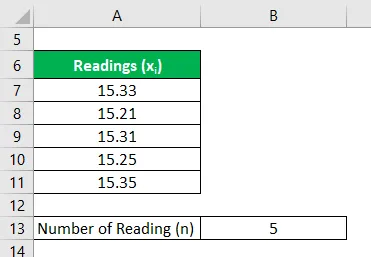
Laten we het voorbeeld nemen van een race van 100 m op een schoolevenement. De race werd getimed met vijf verschillende stopwatches en elke stopwatch registreerde een iets andere timing. De meetwaarden zijn 15, 33 seconden, 15, 21 seconden, 15, 31 seconden, 15, 25 seconden en 15, 35 seconden. Bereken de onzekerheid van de timing op basis van de gegeven informatie en presenteer de timing met een betrouwbaarheidsniveau van 68%.
Oplossing:
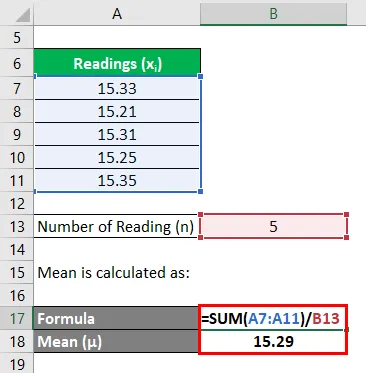
Gemiddelde wordt berekend als:
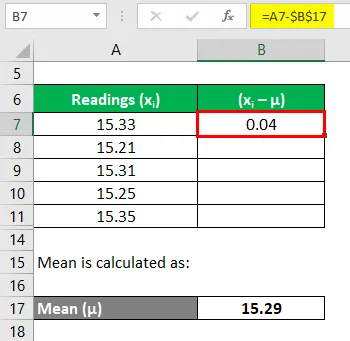
Nu moeten we de afwijkingen van elke meting berekenen
Vergelijk op dezelfde manier voor alle metingen
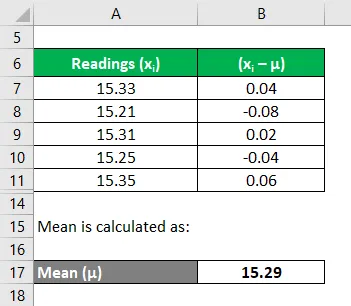
Bereken het kwadraat van de afwijkingen van elke meting
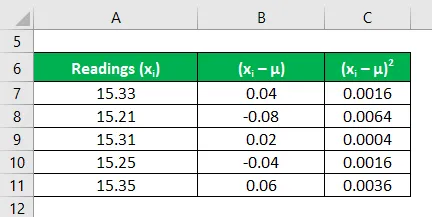
Onzekerheid wordt berekend met behulp van de onderstaande formule
Onzekerheid (u) = √ (∑ (x i - μ) 2 / (n * (n-1)))
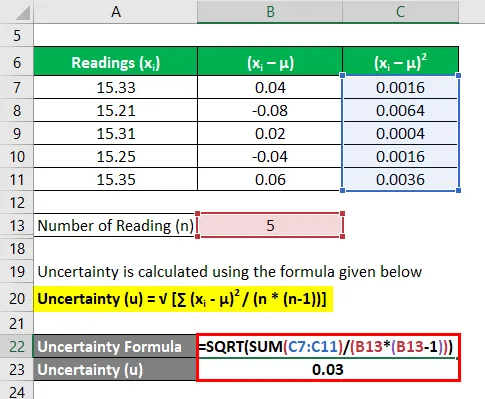
- Onzekerheid = 0, 03 seconden
Timing bij 68% betrouwbaarheidsniveau = μ ± 1 * u
- Meting bij 68% betrouwbaarheidsniveau = (15, 29 ± 1 * 0, 03) seconden
- Meting bij 68% betrouwbaarheidsniveau = (15, 29 ± 0, 03) seconden
Daarom is de onzekerheid van de gegevensset 0, 03 seconden en kan de timing worden weergegeven als (15, 29 ± 0, 03) seconden bij een betrouwbaarheidsniveau van 68%.
Onzekerheidsformule - Voorbeeld # 2
Laten we het voorbeeld nemen van John die heeft besloten zijn onroerend goed, dat een kaal land is, te verkopen. Hij wil het beschikbare gebied van het pand meten. Per aangewezen expert zijn er 5 metingen gedaan - 50, 33 acre, 50, 20 acre, 50, 51 acre, 50, 66 acre en 50, 40 acre. Druk de landmeting uit met een betrouwbaarheidsniveau van 95% en 99%.
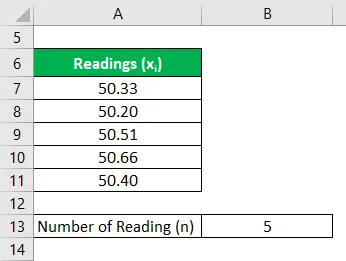
Oplossing:
Gemiddelde wordt berekend als:
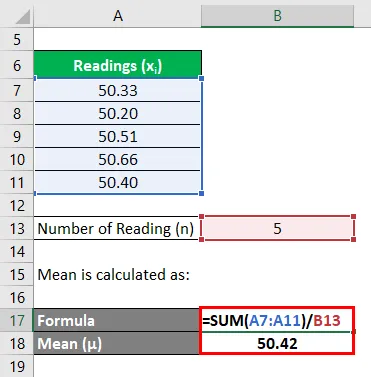
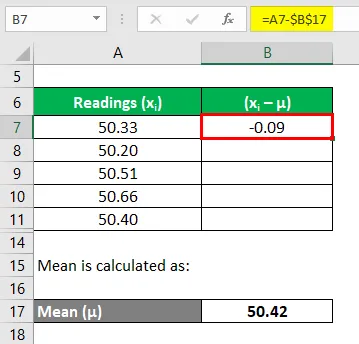
Nu moeten we de afwijkingen van elke meting berekenen
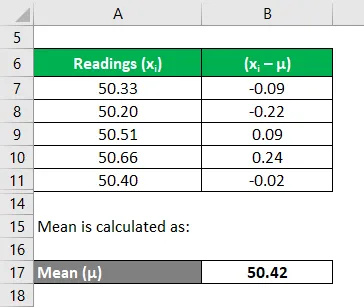
Vergelijk op dezelfde manier voor alle metingen
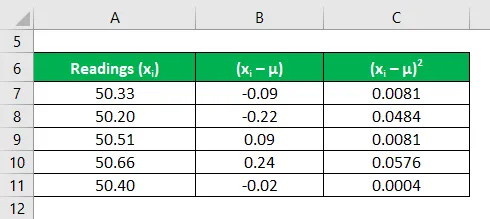
Bereken het kwadraat van de afwijkingen van elke meting
Onzekerheid wordt berekend met behulp van de onderstaande formule
Onzekerheid (u) = √ (∑ (x i - μ) 2 / (n * (n-1)))
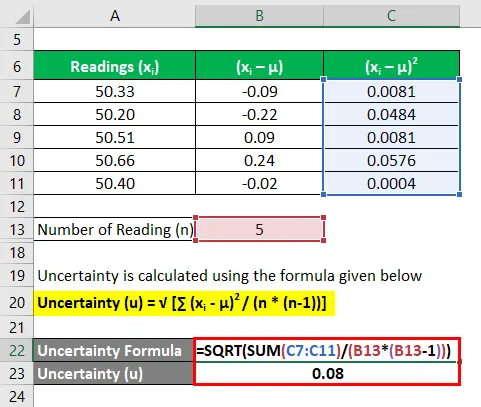
- Onzekerheid = 0, 08 acre
Meting bij een betrouwbaarheidsniveau van 95% = μ ± 2 * u
- Meting bij 95% betrouwbaarheidsniveau = (50, 42 ± 2 * 0, 08) acre
- Meting bij een betrouwbaarheidsniveau van 95% = (50, 42 ± 0, 16) acre
Meting bij 99% betrouwbaarheidsniveau = μ ± 3 * u
- Meting bij 99% betrouwbaarheidsniveau = (50, 42 ± 3 * 0, 08) acre
- Meting bij 99% betrouwbaarheidsniveau = (50, 42 ± 0, 24) acre
Daarom is de onzekerheid van de metingen 0, 08 acre en kan de meting worden weergegeven als (50, 42 ± 0, 16) acre en (50, 42 ± 0, 24) acre bij een betrouwbaarheidsniveau van 95% en 99%.
Uitleg
De formule voor onzekerheid kan worden afgeleid met behulp van de volgende stappen:
Stap 1: Selecteer eerst het experiment en de te meten variabele.
Stap 2: Verzamel vervolgens een voldoende aantal metingen voor het experiment door herhaalde metingen. De meetwaarden vormen de gegevensset en elke meetwaarde wordt aangegeven met x i .
Stap 3: Bepaal vervolgens het aantal metingen in de gegevensset, aangegeven met n.
Stap 4: Bereken vervolgens het gemiddelde van de meetwaarden door alle meetwaarden in de gegevensset samen te vatten en deel het resultaat door het aantal beschikbare meetwaarden in de gegevensset. Het gemiddelde wordt aangegeven met μ.
μ = ∑ x i / n
Stap 5: Bereken vervolgens de afwijking voor alle meetwaarden in de gegevensset, wat het verschil is tussen elke meetwaarde en het gemiddelde ie (x i - μ) .
Stap 6: Bereken vervolgens het kwadraat van alle afwijkingen dwz (x i - μ) 2 .
Stap 7: som vervolgens alle gekwadrateerde afwijkingen op, dwz ∑ (x i - μ) 2 .
Stap 8: Vervolgens wordt de bovenstaande som gedeeld door het product van een aantal metingen en een aantal metingen min één, dwz n * (n - 1) .
Stap 9: Ten slotte kan de formule voor onzekerheid worden afgeleid door de vierkantswortel van het bovenstaande resultaat te berekenen, zoals hieronder weergegeven.
Onzekerheid (u) = √ (∑ (x i - μ) 2 ) / (n * (n-1))
Relevantie en gebruik van onzekerheidsformule
Vanuit het perspectief van statistische experimenten is het concept van onzekerheid erg belangrijk omdat het een statisticus helpt om de variabiliteit in de meetwaarden te bepalen en de meting met een zeker betrouwbaarheidsniveau te schatten. De nauwkeurigheid van de onzekerheid is echter slechts zo goed als de metingen van de meter. Onzekerheid helpt bij het schatten van de beste benadering voor een meting.
Aanbevolen artikelen
Dit is een leidraad geweest voor de onzekerheidsformule. Hier bespreken we hoe de onzekerheid met behulp van de formule wordt berekend, samen met praktische voorbeelden en een downloadbare Excel-sjabloon. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Voorbeelden om de absolute waarde te berekenen
- Calculator voor marge van foutformule
- Hoe de contante waardefactor te berekenen met behulp van de formule?
- Handleiding voor de formule voor relatieve risicoreductie