

Overzicht van soorten clustering
Laten we, voordat we typen van clustering leren, begrijpen wat Clustering is en waarom het nu zo belangrijk is in de machine learning-industrie.
Wat is clustering? Clustering is een proces waarbij het algoritme de datapunten in een bepaald aantal groepen verdeelt op basis van het principe dat vergelijkbare datapunten dicht bij elkaar blijven en in dezelfde groep vallen.
Waarom is het nu zo belangrijk? Laten we begrijpen dat door bijvoorbeeld een voorbeeld te zien, er een online kledingwinkel is en zij hun klanten beter willen begrijpen, zodat zij hun advertentiestrategie effectiever kunnen maken. Het is voor hen niet mogelijk om een uniek soort strategie voor elke klant te hebben, in plaats daarvan kunnen ze de klanten in een bepaald aantal groepen verdelen (op basis van hun eerdere aankopen) en een afzonderlijke strategie van afzonderlijke groepen hebben. Dit maakt het bedrijf effectiever, dit is de reden waarom clustering nu belangrijk is in de industrie.
Soorten clustering
In het algemeen zijn methoden van clusteringstechnieken in twee soorten ingedeeld, het zijn harde methoden en zachte methoden. In de harde clusteringmethode behoort elk gegevenspunt of elke observatie tot slechts één cluster. In de soft clustering-methode zal elk gegevenspunt niet volledig tot één cluster behoren, maar kan het lid zijn van meer dan één cluster, het heeft een set lidmaatschapscoëfficiënten die overeenkomen met de waarschijnlijkheid dat het zich in een gegeven cluster bevindt.
Momenteel zijn er verschillende soorten clustermethoden in gebruik, laten we in dit artikel enkele van de belangrijkste zien, zoals hiërarchische clustering, partitionering clustering, fuzzy clustering, op dichtheid gebaseerde clustering en op distributiemodel gebaseerde clustering. Laten we nu elk van deze bespreken met een voorbeeld:
1. Partitioneren Clustering
Partitioneren Clustering is een type clusteringstechniek, die de gegevensset in een bepaald aantal groepen verdeelt. (Bijvoorbeeld de waarde van K in KNN en deze wordt bepaald voordat we het model trainen). Het kan ook worden genoemd als een centroid-gebaseerde methode. In deze benadering wordt clustercentrum (zwaartepunt) zodanig gevormd dat de afstand van gegevenspunten in dat cluster minimaal is wanneer berekend met andere clustercentroïden. Een meest populair voorbeeld van dit algoritme is het KNN-algoritme. Dit is hoe een algoritme voor het partitioneren van clusters eruit ziet
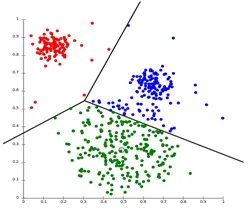
2. Hiërarchische clustering
Hiërarchische clustering is een type clusteringstechniek, die die gegevensverzameling verdeelt in een aantal clusters, waarbij de gebruiker niet het aantal te genereren clusters opgeeft voordat het model wordt getraind. Dit type clusteringstechniek staat ook bekend als op connectiviteit gebaseerde methoden. In deze methode wordt een eenvoudige verdeling van de gegevensset niet uitgevoerd, terwijl het ons de hiërarchie van de clusters biedt die na een bepaalde afstand met elkaar samengaan. Nadat de hiërarchische clustering op de gegevensset is uitgevoerd, is het resultaat een boomgebaseerde weergave van gegevenspunten (Dendogram), die zijn verdeeld in clusters. Dit is hoe een hiërarchische clustering eruit ziet nadat de training is voltooid
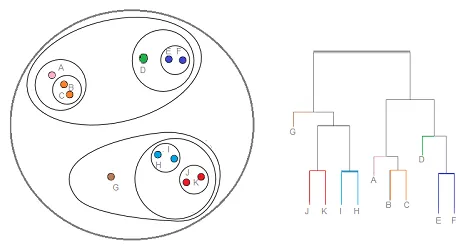
Bronlink: hiërarchische clustering
Bij het partitioneren van clustering en hiërarchische clustering is een belangrijk verschil dat we kunnen opmerken bij het partitioneren van clustering. We specificeren vooraf de waarde van het aantal clusters waarin de gegevensset moet worden verdeeld en we specificeren deze waarde niet vooraf in hiërarchische clustering. .
3. Op dichtheid gebaseerde clustering
In deze clustering zullen techniekclusters worden gevormd door segregatie van verschillende dichtheidsgebieden op basis van verschillende dichtheden in de gegevensplot. Density-Based Spatial Clustering and Application with Noise (DBSCAN) is het meest gebruikte algoritme in dit type techniek. Het belangrijkste idee achter dit algoritme is dat er voor elk punt in het cluster een minimaal aantal punten moet zijn dat in de buurt van een bepaalde straal ligt. Tot dusverre in de hierboven besproken clusteringstechnieken, als u grondig observeert, kunnen we één gemeenschappelijk ding opmerken in alle technieken die de vorm hebben van gevormde clusters zijn bolvormig of ovaal of concaaf gevormd. DBSCAN kan clusters in verschillende vormen vormen, dit type algoritme is het meest geschikt wanneer de dataset ruis of uitbijters bevat. Dit is hoe een op dichtheid gebaseerd ruimtelijk clusteringalgoritme eruit ziet nadat de training is voltooid.
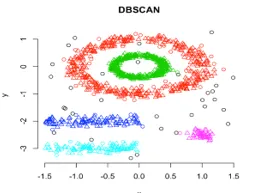
Bron link: op dichtheid gebaseerde clustering
4. Distributie Modelgebaseerde clustering
In dit type clustering worden techniekclusters gevormd door te identificeren door de waarschijnlijkheid dat alle gegevenspunten in de cluster uit dezelfde distributie komen (Normaal, Gaussiaans). Het meest populaire algoritme in dit type techniek is Expectation-Maximization (EM) clustering met behulp van Gaussian Mixture Models (GMM).
Normale clusteringstechnieken zoals hiërarchische clustering en partitionering clustering zijn niet gebaseerd op formele modellen, KNN bij het partitioneren van clustering levert verschillende resultaten op met verschillende K-waarden. Omdat KNN en KMN als gemiddeld beschouwen voor het clustercentrum, is het in sommige gevallen niet het meest geschikt voor Gaussiaanse mengsels. We veronderstellen dat datapunten Gaussisch verdeeld zijn. Op deze manier hebben we twee parameters om de vorm van het gemiddelde van de clusters en de standaarddeviatie te beschrijven. Op deze manier wordt voor elk cluster een Gauss-verdeling toegewezen, om de optimale waarden van deze parameters (gemiddelde en standaarddeviatie) te verkrijgen, wordt een optimalisatie-algoritme genaamd Verwachtingsmaximalisatie gebruikt. Zo ziet EM - GMM er na de training uit.
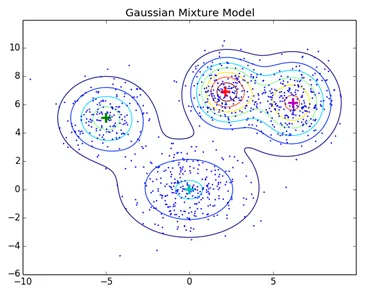
Bronlink: distributie Modelgebaseerde clustering
5. Fuzzy Clustering
Behoort tot een tak van zachte methode clusteringstechnieken, terwijl alle bovengenoemde clusteringstechnieken tot harde methode clusteringstechnieken behoren. Bij dit type clusteringstechniek wijzen punten dicht bij het midden, misschien een deel van het andere cluster in hogere mate dan punten aan de rand van hetzelfde cluster. De kans dat een punt bij een bepaald cluster hoort, is een waarde die tussen 0 en 1 ligt. Het meest populaire algoritme in dit type techniek is FCM (Fuzzy C-betekent Algorithm) Hier wordt het zwaartepunt van een cluster berekend als het gemiddelde van alle punten, gewogen door hun waarschijnlijkheid tot het cluster te behoren.
Conclusie - Soorten clustering
Dit zijn enkele van de verschillende clusteringstechnieken die momenteel worden gebruikt en in dit artikel hebben we één populair algoritme behandeld in elke clusteringstechniek. We moeten het type technologie kiezen dat we gebruiken, op basis van onze dataset en vereisten waaraan we moeten voldoen.
Aanbevolen artikelen
Dit is een gids voor soorten clustering geweest. Hier bespreken we verschillende soorten clustering met hun voorbeelden. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Hiërarchisch clusteringalgoritme
- Clustering in machine learning
- Soorten algoritmen voor machine learning
- Soorten gegevensanalysetechnieken
- Hoe hiërarchie te gebruiken en te verwijderen in Tableau?
- Volledige gids voor soorten gegevensanalyse