
Wat is Cassandra?
Cassandra is een NoSQL-database die peer-to-peer gedistribueerde database is. Het draait op een cluster met homogene knooppunten. Het is zo gemaakt dat het grote hoeveelheden gegevens kan verwerken. Bij het verwerken van deze gegevens moet het ook een hoge capaciteit kunnen bieden. Cassandra biedt de hele tijd hoog als het gaat om lees- en schrijfbewerkingen. De architectuur van Cassandra cluster heeft geen meesters, slaven of specifieke leiders. Op deze manier zorgt het ervoor dat er geen enkel punt van mislukking is. Laten we de architectuur in detail bekijken.
Cassandra-architectuur
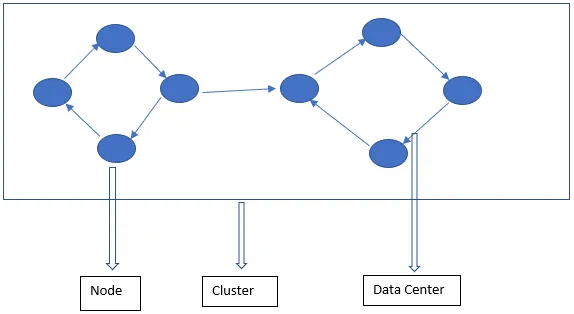
De Cassandra-architectuur bestaat voornamelijk uit Node, Cluster en Data Center. Naast deze zijn er ook andere componenten. Cassandra is een rij opgeslagen database. Hiermee kunnen geautoriseerde gebruikers verbinding maken met elk knooppunt in elk datacenter met behulp van de CQL.
Belangrijkste structuren in Cassandra
Dit zijn de volgende belangrijke structuren in Cassandra:
- Knooppunt - Hier worden de gegevens opgeslagen. Het is het meest elementaire onderdeel van Cassandra. Het kan worden gezien als een enkele server in een rack. Het zorgt ervoor dat er geen enkel punt van mislukking is.
- Datacenter - Een datacenter is een verzameling knooppunten. Dit kan een fysieke of een virtuele zijn. Afhankelijk van de werklast worden datacenters verdeeld en gekozen. De replicatiefactor wordt bepaald op basis van het datacenter. Afhankelijk van deze replicatiefactor kunnen gegevens naar verschillende datacenters worden geschreven.
- Cluster - Cluster bestaat uit een of meer datacenters. Clusters overspannen meestal op verschillende fysieke locaties.
Naast deze zijn de andere componenten die een rol spelen in Cassandra zoals hieronder.
1. Commit-logboek
De gegevens die worden vastgelegd voor het behoud van de duurzaamheid van gegevens worden opgeslagen in het vastleggingslogboek. De gegevens worden verplaatst naar een gesorteerde stringtabel (hierna uitgelegd). Zodra deze beweging is voltooid, kan het vastleggingslogboek worden gearchiveerd, verwijderd of gerecycled.
2. SS-tabel
Deze tabel, zoals vermeld in het vorige punt, slaat de log- of geheugentabellen op regelmatige tijdstippen op. Het is een onveranderlijk gegevensbestand. SS-tabellen kunnen gegevens vaak op een opeenvolgende manier opslaan. Ze voegen gegevens toe en onderhouden informatie voor elke Cassandra-tabel.
3. CQL-tabel
De Cassandra-querytabel is een verzameling geordende kolommen die een rij uit deze tabel kunnen halen. Er zijn kolommen in deze tabel opgeslagen waar gegevens kunnen worden opgehaald met behulp van de primaire sleutel.
4. Bloeifilter
Het is een eenvoudig soort cache waarin niet-deterministische algoritmen zijn opgeslagen om te testen. Het controleert of een element lid is van de set of niet. Deze filters zijn meestal toegankelijk na elke query die wordt uitgevoerd.
Belangrijkste componenten om Cassandra te configureren
Er zijn de volgende componenten in Cassandra:
1. Roddel
- Zoals de naam al doet vermoeden, moet er communicatie tussen collega's zijn om de locatie en de status van informatie over alle knooppunten te ontdekken en te delen.
- Deze informatie moet lokaal blijven staan, zodat elk knooppunt de informatie kan gebruiken zodra een knooppunt opnieuw moet worden opgestart. Knooppunten ontdekken informatie over andere knooppunten door informatie uit te wisselen.
- Dit kan voor maximaal drie knooppunten. De informatie wordt niet gedeeld met elk knooppunt dat aanwezig is in het cluster of datacenter. De informatie wordt gedeeld met een paar knooppunten, maar uiteindelijk loopt de statusinformatie door het cluster.
2. Partitie
- De partitioner beslist welk knooppunt de eerste replica van alle gegevens moet ontvangen. Het is ook verantwoordelijk voor de distributie van deze replica's.
- Het zal bepalen welk knooppunt welke replicatie in het cluster moet hebben. Elke rij met gegevens moet uniek worden geïdentificeerd. Dit kan worden gedaan door gebruik te maken van een primaire sleutel of partitiesleutel.
- De partitioner is een hash-functie die helpt bij het verkrijgen van een token van een primaire sleutel van een rij. Aan elk knooppunt is een num_token-waarde toegewezen die kan worden ingesteld als de partitioner.
- De tokenwaarde die wordt gegenereerd, helpt bij het bepalen welk knooppunt de replica van de rijen ontvangt.
3. Replicatiefactor
- Deze factor bepaalt het totale aantal replica's dat aanwezig is in het cluster. Als de replicatiefactor 1 is, is er slechts één kopie van elke rij op één knooppunt.
- Evenzo, als de replicatiefactor twee is, blijven er twee kopieën behouden waarbij elke kopie op een ander knooppunt aanwezig is. Zoals eerder vermeld, is er geen master-slave-architectuur in Cassandra, elk exemplaar is belangrijk.
- De replicatiefactor wordt gedefinieerd voor elk datacenter. Deze factor moet groter zijn dan één maar niet meer dan het aantal aanwezige knooppunten in het cluster.
4. Snitch
- De replicatiestrategie die helpt bij het verkrijgen van de plaats waar replica's moeten worden geplaatst voor een groep machines in het datacenter en het rack staat bekend als Snitch.
- Er is een dynamische laag die helpt bij monitoring en prestaties en helpt bij het kiezen van de beste replica waaruit gegevens kunnen worden gelezen. Snitches moeten alleen worden geconfigureerd wanneer een cluster wordt gemaakt.
- Voor de meeste implementaties zijn standaardwaarden ingeschakeld. De configuratiewijzigingen kunnen worden aangebracht in het bestand Cassandra.yml, waar de dynamische drempelwaarde voor elke knoop aanwezig is.
5. Merkle-boom
- Er kunnen verschillen zijn in gegevensblokken. Om de verschillen gemakkelijk te vinden, is de Merkle-boom een hasj-boom die hierbij helpt.
- De bladknooppunten van de hashboom bevatten hashes van afzonderlijke gegevensblokken en bovenliggende knooppunten hebben de informatie of ze slaan ook de hashes van hun kinderen op.
- Door deze techniek te gebruiken, is het gemakkelijker om verschillen te vinden tussen de aanwezige knooppunten.
6. Mem-tabel
- Deze tabel bevat informatie over het cachegeheugen waarvan de gegevens nog niet zijn leeggemaakt en zich in het geheugen bevinden.
Conclusie
Cassandra is een NoSQL-database die nuttig is voor het verwerken van grote hoeveelheden gegevens. Het heeft geen typische master-slave-architectuur en daarom zijn alle knooppunten even belangrijk. De knooppunten hebben replica's in het cluster volgens de replicatiefactor. Dit zorgt voor de consistentie en duurzaamheid van de gegevens. Met al deze functies is het duidelijk dat Cassandra erg handig is voor big data. Cassandra is dus duurzaam, snel en gedistribueerd en betrouwbaar.
Aanbevolen artikelen
Dit is een gids voor Cassandra Architecture. Hier bespreken we de introductie, de Cassandra-architectuur, de sleutelstructuur en de belangrijkste componenten van Cassandra. U kunt ook onze andere voorgestelde artikelen doornemen -
- Overzicht van Kubernetes-architectuur
- Wat is big data-architectuur?
- Functies toegevoegd aan AutoCAD Architecture
- Cloud computing-architectuur