
Inleiding tot ensemble-technieken
Ensemble leren is een techniek in machine learning waarbij verschillende basismodellen worden gebruikt en hun output wordt gecombineerd om een geoptimaliseerd model te produceren. Dit type machine learning-algoritme helpt bij het verbeteren van de algehele prestaties van het model. Hier is het basismodel dat het meest wordt gebruikt de beslissingsboomclassificator. Een beslissingsboom werkt in principe op verschillende regels en biedt een voorspellende output, waarbij de regels de knooppunten zijn en hun beslissingen hun kinderen zijn en de bladknooppunten de uiteindelijke beslissing vormen. Zoals getoond in het voorbeeld van een beslissingsboom.
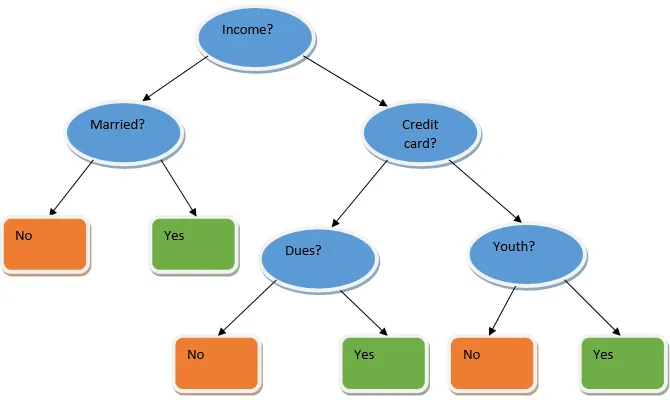
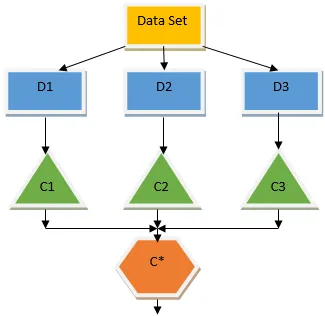
Bovenstaande beslissingsboom gaat in principe over of een persoon / klant een lening kan krijgen of niet. Een van de regels om in aanmerking te komen voor een lening ja is dat als (inkomen = Ja && Married = Nee) Lening = Ja, dus dit is hoe een beslissingsboomclassificator werkt. We zullen deze classificaties als een meervoudig basismodel opnemen en hun output combineren om één optimaal voorspellend model te bouwen. Figuur 1.b toont het algemene beeld van een algoritme voor het leren van ensembles.
Soorten ensembles-technieken
Verschillende soorten ensembles, maar onze belangrijkste focus zal liggen op de onderstaande twee soorten:
- bagging
- stimuleren
Deze methoden helpen bij het verminderen van de variantie en bias in een machine learning-model. Laten we nu proberen te begrijpen wat bias en variantie is. Bias is een fout die optreedt als gevolg van onjuiste veronderstellingen in ons algoritme; een hoge bias geeft aan dat ons model te simpel / onderfit is. Variantie is de fout die wordt veroorzaakt door de gevoeligheid van het model voor zeer kleine schommelingen in de gegevensset; een grote variantie geeft aan dat ons model zeer complex / overfit is. Een ideaal ML-model moet een juiste balans hebben tussen bias en variantie.
Bootstrap aggregeren / inpakken
Zakken is een ensemble-techniek die helpt bij het verminderen van variantie in ons model en dus overfitting voorkomt. Bagging is een voorbeeld van het algoritme voor parallel leren. Zakken werken op basis van twee principes.
- Bootstrapping: van de originele gegevensset worden verschillende vervangende steekproefpopulaties in overweging genomen.
- Aggregeren: de resultaten van alle classificaties berekenen en een enkele output bieden, hiervoor gebruikt het meerderheidstemming in het geval van classificatie en het gemiddelde in het geval van het regressieprobleem. Een van de beroemde algoritmen voor machine learning die het concept van zakken gebruiken, is een willekeurig bos.
Willekeurig bos
In willekeurig bos uit de willekeurige steekproef die uit de populatie is genomen met vervanging en een subset van functies is geselecteerd uit de set van alle functies die een beslissingsboom is gebouwd. Uit deze subsets met functies wordt de functie die het beste gesplitst is geselecteerd als de root voor de beslissingsboom. De functiesubset moet tegen elke prijs willekeurig worden gekozen, anders produceren we alleen gecorreleerde lokken en wordt de variantie van het model niet verbeterd.
Nu hebben we ons model gebouwd met de monsters genomen uit de populatie, de vraag is hoe kunnen we het model valideren? Omdat we overwegen de monsters te vervangen, zullen alle monsters niet in overweging worden genomen en zullen sommige ervan niet in een zak worden opgenomen. Deze worden uit zakmonsters genoemd. We kunnen ons model valideren met deze OOB-monsters (uit de zak). De belangrijke parameters die in een willekeurig bos moeten worden overwogen, zijn het aantal monsters en het aantal bomen. Laten we 'm' beschouwen als de subset van functies en 'p' is de volledige set functies, nu is het als een duimregel altijd ideaal om te kiezen
- m as√en een minimale knooppuntgrootte als 1 voor een classificatieprobleem.
- m als P / 3 en minimale knooppuntgrootte 5 voor een regressieprobleem.
De m en p moeten worden behandeld als afstemmingsparameters wanneer we met een praktisch probleem omgaan. De training kan worden beëindigd zodra de OOB-fout zich stabiliseert. Een nadeel van het willekeurige forest is dat wanneer we 100 functies in onze gegevensset hebben en slechts een paar functies belangrijk zijn, dit algoritme slecht zal presteren.
stimuleren
Boosting is een sequentieel leeralgoritme dat helpt bij het verminderen van vertekening in ons model en variantie in sommige gevallen van begeleid leren. Het helpt ook bij het omzetten van zwakke leerlingen in sterke leerlingen. Boosting werkt volgens het principe van het plaatsen van de zwakke leerlingen achter elkaar en het wijst een gewicht toe aan elk gegevenspunt na elke ronde; meer gewicht wordt toegekend aan het verkeerd geclassificeerde gegevenspunt in de vorige ronde. Deze opeenvolgende gewogen methode voor het trainen van onze gegevensset is het belangrijkste verschil met dat van zakken.
Fig.3.a toont de algemene benadering bij het stimuleren
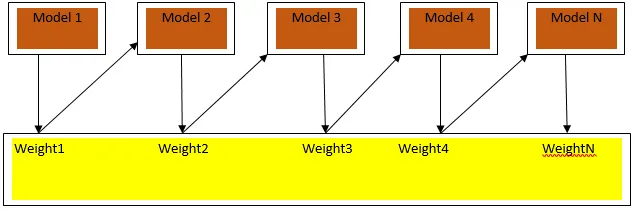
De definitieve voorspellingen worden gecombineerd op basis van een gewogen meerderheid in het geval van classificatie en een gewogen som in het geval van regressie. Het meest gebruikte boost-algoritme is adaptive boosting (Adaboost).
Adaptieve boosting
De stappen in het Adaboost-algoritme zijn als volgt:
- Voor de gegeven n datapunten definiëren we het doelwit classy en initialiseren alle gewichten op 1 / n.
- We passen de classificaties aan de gegevensset aan en we kiezen de classificatie met de minst gewogen classificatiefout
- We wijzen gewichten voor de classificator toe met een duimregel op basis van nauwkeurigheid, als de nauwkeurigheid meer dan 50% is, is het gewicht positief en vice versa.
- We werken de gewichten van de classificaties aan het einde van de iteratie; we werken meer gewicht voor het verkeerd geclassificeerde punt bij, zodat we het in de volgende iteratie correct classificeren.
- Na alle iteratie krijgen we het uiteindelijke voorspellingsresultaat op basis van het meerderheidstemmen / gewogen gemiddelde.
Adaboosting werkt efficiënt met zwakke (minder complexe) leerlingen en met classificaties met een hoge bias. De grote voordelen van Adaboosting zijn dat het snel is, er zijn geen afstemmingsparameters vergelijkbaar met het geval van zakken en we doen geen aannames over zwakke leerlingen. Deze techniek levert geen nauwkeurig resultaat op wanneer
- Er zijn meer uitbijters in onze gegevens.
- De gegevensset is onvoldoende.
- De zwakke leerlingen zijn zeer complex.
Ze zijn ook gevoelig voor lawaai. De beslissingsbomen die worden geproduceerd als gevolg van boosting zullen een beperkte diepte en hoge nauwkeurigheid hebben.
Conclusie
Leertechnieken voor ensembles worden veel gebruikt om de modelnauwkeurigheid te verbeteren; we moeten beslissen welke techniek we moeten gebruiken op basis van onze gegevensset. Maar deze technieken hebben niet de voorkeur in sommige gevallen waar interpreteerbaarheid van belang is, omdat we interpreteerbaarheid verliezen ten koste van prestatieverbetering. Deze hebben een enorme betekenis in de gezondheidszorg, waar een kleine verbetering van de prestaties zeer waardevol is.
Aanbevolen artikelen
Dit is een handleiding voor ensemble-technieken. Hier bespreken we de introductie en twee hoofdtypen ensemble-technieken. U kunt ook onze andere gerelateerde artikelen doornemen voor meer informatie-
- Steganografie technieken
- Technieken voor machinaal leren
- Technieken voor teambuilding
- Data Science-algoritmen
- Meest gebruikte technieken van ensemble leren