

Inleiding tot Spark-opdrachten
Apache Spark is een framework dat bovenop Hadoop is gebouwd voor snelle berekeningen. Het breidt het concept MapReduce uit in het cluster-gebaseerde scenario om een taak efficiënt uit te voeren. Spark Command is geschreven in Scala.
Hadoop kan op de volgende manieren door Spark worden gebruikt (zie hieronder):
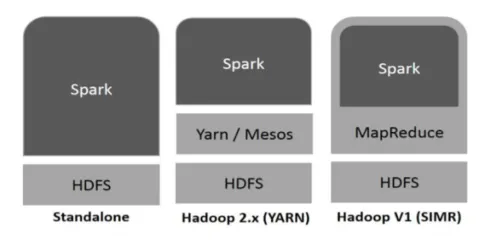
Figuur 1
https://www.tutorialspoint.com/
- Standalone: Spark direct ingezet op Hadoop. Spark-taken lopen parallel op Hadoop en Spark.
- Hadoop YARN: Spark draait op garen zonder dat een pre-installatie nodig is.
- Spark in MapReduce (SIMR): Spark in MapReduce wordt gebruikt om de spark-taak te starten, naast de zelfstandige implementatie. Met SIMR kan men Spark starten en zijn shell gebruiken zonder enige beheerdersrechten.
Componenten van Spark:
- Apache Spark Core
- Spark SQL
- Vonken streamen
- MLIB
- Graphx
Resilient Distributed Datasets (RDD) wordt beschouwd als de fundamentele gegevensstructuur van Spark-opdrachten. RDD is onveranderlijk en alleen-lezen van aard. Alle soorten berekeningen in vonkopdrachten worden gedaan door transformaties en acties op RDD's.
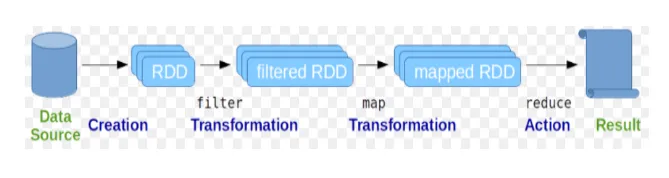
Figuur 2
Google afbeelding
Spark shell biedt een medium voor gebruikers om te communiceren met zijn functionaliteiten. Spark-opdrachten hebben veel verschillende opdrachten die kunnen worden gebruikt om gegevens op de interactieve shell te verwerken.
Basisvonkopdrachten
Laten we eens kijken naar enkele van de Basic Spark-opdrachten die hieronder worden gegeven: -
-
Om de Spark shell te starten:

Fig 3
-
Bestand lezen van lokaal systeem:

Hier is "sc" de vonkcontext. Aangezien "data.txt" in de basismap staat, wordt het als volgt gelezen, anders moet het volledige pad worden opgegeven.
-
Maak RDD via parallellisatie

NewData is nu de RDD.
-
Tel items in RDD

-
Verzamelen
Met deze functie wordt alle RDD-inhoud teruggestuurd naar het stuurprogramma. Dit is handig bij het opsporen van fouten in verschillende stappen van het schrijfprogramma.
-
Lees eerst 3 items van RDD

-
Bewaar uitgevoerde / verwerkte gegevens in het tekstbestand

Hier is de map "output" het huidige pad.
Tussentijdse vonkopdrachten
1. Filter op RDD
Laten we een nieuwe RDD maken voor items die “ja” bevatten.

Transformatiefilter moet worden aangeroepen op bestaande RDD om te filteren op het woord "ja", waardoor een nieuwe RDD wordt gecreëerd met de nieuwe lijst met items.
2. Kettingbediening

Hier werkten filtertransformatie en telactie samen. Dit wordt kettingbediening genoemd.
3. Lees het eerste item van RDD

4. Tel RDD-partities
Zoals we weten, bestaat RDD uit meerdere partities, het is nodig om het nee te tellen. van partities. Omdat het helpt bij het afstemmen en probleemoplossing tijdens het werken met Spark-opdrachten.

Standaard minimum. pf-partitie is 2.
5. doe mee
Deze functie voegt twee tabellen samen (het tabelelement is paarsgewijs) op basis van de gemeenschappelijke sleutel. Bij paarsgewijze RDD is het eerste element de sleutel en het tweede element de waarde.
6. Cache een bestand
Caching is een optimalisatietechniek. RD opslaan in de cache betekent dat RDD zich in het geheugen bevindt en alle toekomstige berekeningen worden uitgevoerd op die RDD in het geheugen. Het bespaart de leestijd van de schijf en verbetert de prestaties. Kortom, het verkort de toegangstijd tot de gegevens.

Gegevens worden echter niet in de cache opgeslagen als u de bovenstaande functie uitvoert. Dit kan worden bewezen door de webpagina te bezoeken:
http: // localhost: 4040 / opslag
RDD wordt in de cache opgeslagen zodra de actie is voltooid. Bijvoorbeeld:

Nog een functie die vergelijkbaar is met cache () is persist (). Persist biedt gebruikers de flexibiliteit om het argument te geven, waardoor gegevens in het cachegeheugen kunnen worden opgeslagen in het geheugen, op een schijf of in een ander geheugen. Volharden zonder enig argument werkt hetzelfde als cache ().
Geavanceerde vonkopdrachten
Laten we eens kijken naar enkele van de geavanceerde Spark-opdrachten die hieronder worden gegeven: -
-
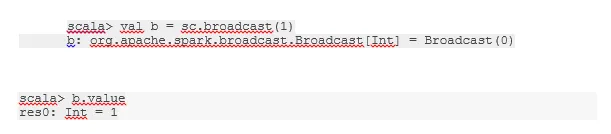
Zend een variabele uit
Met de uitzendvariabele kan de programmeur de enige variabele in de cache op elke machine in het cluster blijven lezen, in plaats van een kopie van die variabele met taken te verzenden. Dit helpt bij het verlagen van de communicatiekosten.
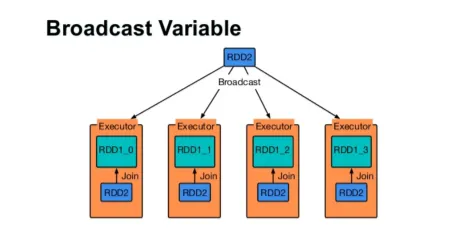
Fig 4
Google afbeelding
Kortom, er zijn drie hoofdkenmerken van de variabele Broadcasted:
- Onveranderlijk
- Past in het geheugen
- Verdeeld over cluster
-
accumulatoren
Accumulatoren zijn de variabelen die worden toegevoegd aan bijbehorende bewerkingen. Er zijn veel toepassingen voor accumulatoren zoals tellers, bedragen, enz.

De naam van de accumulator in de code is ook te zien in Spark UI.
-
Kaart
De kaartfunctie helpt bij het herhalen van elke regel in RDD. De functie die in de kaart wordt gebruikt, wordt op elk element in RDD toegepast.
Als we bijvoorbeeld in RDD (1, 2, 3, 4, 6) “rdd.map (x => x + 2)” toepassen, krijgen we het resultaat als (3, 4, 5, 6, 8).
-
Flatmap
Flatmap werkt vergelijkbaar met de kaart, maar map retourneert slechts één element, terwijl flatmap de lijst met elementen kan retourneren. Vandaar dat het splitsen van zinnen in woorden een flatmap nodig heeft.
-
Coalesce
Deze functie helpt het schudden van gegevens te voorkomen. Dit wordt toegepast in de bestaande partitie zodat minder gegevens worden geschud. Op deze manier kunnen we het gebruik van knooppunten in het cluster beperken.
Tips en trucs om vonkopdrachten te gebruiken
Hieronder staan de verschillende tips en trucs van Spark-opdrachten: -
- Beginners van Spark kunnen Spark-shell gebruiken. Omdat Spark-opdrachten op Scala zijn gebouwd, is het zeker geweldig om scala spark shell te gebruiken. Python spark shell is echter ook beschikbaar, dus zelfs dat iets dat je kunt gebruiken, die goed thuis zijn in python.
- Spark shell heeft veel opties om de bronnen van het cluster te beheren. Onderstaand commando kan je daarbij helpen:

- In Spark is het gebruikelijk om met lange datasets te werken. Maar er gaat iets mis als er slechte invoer wordt gemaakt. Het is altijd een goed idee om slechte rijen te verwijderen met behulp van de filterfunctie van Spark. De goede input zal een geweldige go zijn.
- Spark kiest zelf een goede partitie voor uw gegevens. Maar het is altijd een goede gewoonte om partities in de gaten te houden voordat je aan je werk begint. Het uitproberen van verschillende partities helpt je bij het parallellisme van je werk.
Conclusie - Spark Commands:
Spark commando is een revolutionaire en veelzijdige big data-engine, die kan werken voor batchverwerking, real-time verwerking, caching van gegevens enz. Spark heeft een rijke set Machine Learning-bibliotheken waarmee gegevenswetenschappers en analytische organisaties sterke, interactieve en snelle toepassingen.
Aanbevolen artikelen
Dit is een gids geweest voor Spark-opdrachten. Hier hebben we de basis- en geavanceerde Spark-opdrachten en enkele onmiddellijke Spark-opdrachten besproken. U kunt ook het volgende artikel bekijken voor meer informatie -
- Adobe Photoshop-opdrachten
- Belangrijke VBA-opdrachten
- Tableau-opdrachten
- Cheatsheet SQL (opdrachten, gratis tips en trucs)
- Soorten joins in Spark SQL (voorbeelden)
- Vonkonderdelen | Overzicht en top 6 componenten