
Inleiding tot achterwaartse eliminatie
Terwijl mens en machine op digitale evolutie afstevenen, zijn machines met verschillende technieken verantwoordelijk om niet alleen getraind te worden, maar ook slim getraind om te komen met betere herkenning van objecten uit de echte wereld. Een dergelijke techniek die eerder werd geïntroduceerd, genaamd "Achterwaartse eliminatie", die bedoeld was om onmisbare functies te begunstigen en tegelijkertijd nugatorische functies uit te roeien om betere optimalisatie in een machine uit te oefenen. De volledige vaardigheid van objectherkenning door Machine is evenredig aan welke functies het overweegt.
Functies die geen referentie hebben op de voorspelde output moeten uit de machine worden afgevoerd en het wordt afgesloten door achterwaartse eliminatie. Goed Precisie en tijdcomplexiteit van herkenning van elk echt woordobject door Machine zijn afhankelijk van het leerproces. Dus achteruit elimineren speelt zijn rigide rol voor de selectie van functies. Het rekent de mate van afhankelijkheid van kenmerken aan de afhankelijke variabele en vindt de betekenis van zijn thuishoren in het model. Om dit te accrediteren, controleert het het berekende tarief met een standaard significantieniveau (zeg 0, 06) en neemt het een beslissing voor de selectie van functies.
Waarom stoppen we achterwaartse eliminatie ?
Niet-essentiële en overbodige eigenschappen drijven de complexiteit van machinelogica aan. Het verslindt tijd en modelmiddelen onnodig. Dus de bovengenoemde techniek speelt een competente rol om het model te simpel te maken. Het algoritme cultiveert de beste versie van het model door de prestaties te optimaliseren en de benoemde vervangbare middelen in te korten.
Het beperkt de minst opvallende kenmerken van het model die ruis veroorzaken bij het bepalen van de regressielijn. Irrelevante objecteigenschappen kunnen leiden tot verkeerde classificatie en voorspelling. Irrelevante kenmerken van een entiteit kunnen een disbalans in het model vormen met betrekking tot andere belangrijke kenmerken van andere objecten. De achterwaartse eliminatie bevordert de aanpassing van het model aan het beste geval. Daarom wordt achterwaartse eliminatie aanbevolen voor gebruik in een model.
Hoe achterwaartse eliminatie toe te passen?
De achterwaartse eliminatie begint met alle kenmerkvariabelen en test deze met de afhankelijke variabele onder een geselecteerde aanpassing van het modelcriterium. Het begint die variabelen die de passende regressielijn verslechteren, uit te roeien. Herhaling van deze verwijdering totdat het model goed past. Hieronder zijn de stappen om de achterwaartse eliminatie te oefenen:
Stap 1: Kies het juiste significantieniveau om in het model van de machine te verblijven. (Neem S = 0, 06)
Stap 2: Voer alle beschikbare onafhankelijke variabelen toe aan het model met betrekking tot de afhankelijke variabele en computer de helling en onderscheppen om een regressielijn of paslijn te trekken.
Stap 3: Beweeg één voor één met alle onafhankelijke variabelen met de hoogste waarde (Take I) en ga verder met de volgende toast: -
a) Als ik> S, voer dan de 4e stap uit.
b) Anders wordt afgebroken en het model is perfect.
Stap 4: Verwijder die gekozen variabele en verhoog de verplaatsing.
Stap 5: Smeed het model opnieuw en bereken de helling en onderschepping van de paslijn opnieuw met resterende variabelen.
De bovengenoemde stappen zijn samengevat in de afwijzing van die kenmerken waarvan het significantieniveau hoger is dan de geselecteerde significantiewaarde (0, 06) om overclassificatie en overbenutting van middelen te vermijden die als hoge complexiteit werden waargenomen.
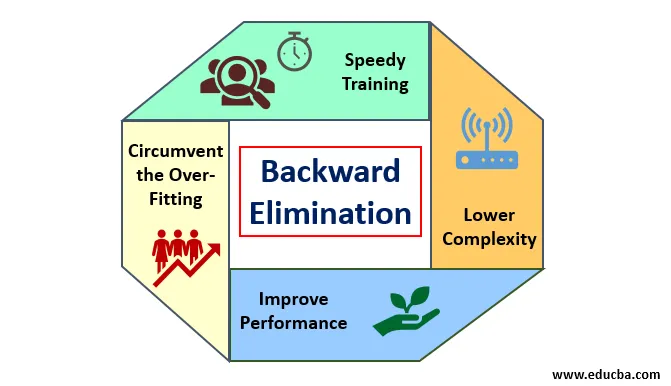
Voor- en nadelen van achterwaartse eliminatie
Hier zijn enkele verdiensten en minpunten van achterwaartse eliminatie die hieronder in detail worden gegeven:
1. verdiensten
De voordelen van achterwaartse eliminatie zijn als volgt:
- Snelle training: de machine wordt getraind met een set beschikbare functies van het patroon die in zeer korte tijd wordt uitgevoerd als niet-essentiële functies uit het model worden verwijderd. Snelle training van gegevensset komt alleen in beeld als het model te maken heeft met belangrijke functies en alle ruisvariabelen uitsluit. Het trekt een eenvoudige complexiteit voor training. Maar het model moet geen onderpassing ondergaan die optreedt vanwege een gebrek aan functies of onvoldoende monsters. De voorbeeldfunctie moet overvloedig aanwezig zijn in een model voor de beste classificatie. De tijd die nodig is om het model te trainen, moet minder zijn, terwijl de nauwkeurigheid van de classificatie behouden blijft en er geen variabele voor onder voorspelling is.
- Lagere complexiteit: de complexiteit van het model is toevallig hoog als het model de omvang van functies overweegt, waaronder ruis en niet-gerelateerde functies. Het model kost veel ruimte en tijd om zo'n reeks functies te verwerken. Dit kan de nauwkeurigheid van patroonherkenning verhogen, maar de snelheid kan ook ruis bevatten. Om van zo'n hoge complexiteit van het model af te komen, speelt het achterwaartse eliminatie-algoritme een vereiste rol door de ongewenste functies uit het model te verwijderen. Het vereenvoudigt de verwerkingslogica van het model. Slechts een paar essentiële functies zijn voldoende om een goede pasvorm te tekenen die tevreden is met een redelijke nauwkeurigheid.
- Prestaties verbeteren: de prestaties van het model zijn afhankelijk van vele aspecten. Het model ondergaat optimalisatie door achterwaartse eliminatie te gebruiken. De optimalisatie van het model is de optimalisatie van de dataset die wordt gebruikt voor het trainen van het model. De prestaties van het model zijn recht evenredig met de mate van optimalisatie die afhankelijk is van de frequentie van belangrijke gegevens. Het achterwaartse eliminatieproces is niet bedoeld om de wijziging van een laagfrequente predicator te starten. Maar het begint alleen met wijziging van hoogfrequente gegevens, omdat meestal de complexiteit van het model afhangt van dat deel.
- Omzeil de overaanpassing: de overaanpassingssituatie doet zich voor wanneer het model te veel datasets kreeg en classificatie of voorspelling wordt uitgevoerd waarbij sommige predicators het geluid van andere klassen kregen. In deze aanpassing zou het model een onverwacht hoge nauwkeurigheid moeten geven. In overpassing kan het model de variabele mogelijk niet classificeren vanwege verwarring die in logica is ontstaan vanwege te veel voorwaarden. De achterwaartse eliminatietechniek beperkt de vreemde functie om de situatie van overpassing te omzeilen.
2. Demerits
Minpunten van achterwaartse eliminatie zijn als volgt:
- In de achterwaartse eliminatiemethode kan men niet achterhalen welke predicator verantwoordelijk is voor de afwijzing van een andere predicator vanwege het bereiken van onbeduidendheid. Bijvoorbeeld, als predicator X een betekenis heeft die goed genoeg was om in een model te verblijven na het toevoegen van de Y-predicator. Maar de betekenis van X raakt verouderd wanneer een andere predikant Z in het model komt. Het achterwaartse eliminatie-algoritme is dus niet duidelijk over enige afhankelijkheid tussen twee voorspellers die zich voordoen in de "Voorwaartse selectietechniek".
- Nadat een functie uit een model is verwijderd door een algoritme voor achterwaartse eliminatie, kan die functie niet opnieuw worden geselecteerd. Kortom, achterwaartse eliminatie heeft geen flexibele aanpak om functies / voorspellers toe te voegen of te verwijderen.
- De normen om de significantiewaarde (0, 06) in het model te selecteren, zijn niet flexibel. De achterwaartse eliminatie heeft geen flexibele procedure om niet alleen de onbeduidende waarde te kiezen, maar ook te wijzigen, zoals vereist om de beste pasvorm te krijgen onder een adequate gegevensset.
Conclusie
De achterwaartse eliminatietechniek is gerealiseerd om de prestaties van het model te verbeteren en de complexiteit te optimaliseren. Het werd levendig gebruikt in meerdere regressies waarbij het model de uitgebreide dataset behandelt. Het is een gemakkelijke en eenvoudige benadering in vergelijking met voorwaartse selectie en kruisvalidatie waarin een overbelasting van optimalisatie is opgetreden. De achterwaartse eliminatietechniek initieert de eliminatie van kenmerken met een hogere significantiewaarde. Het hoofddoel is om het model minder complex te maken en een te nauw aansluitende situatie te verbieden.
Aanbevolen artikelen
Dit is een gids voor achterwaartse eliminatie. Hier bespreken we hoe we achterwaartse eliminatie kunnen toepassen, samen met de verdiensten en de minpunten. U kunt ook de volgende artikelen bekijken voor meer informatie-
- Machine leren van hyperparameter
- Clustering in machine learning
- Java Virtual Machine
- Machinaal leren zonder toezicht