
Inleiding tot gegevensanalysetechnieken
In de 21e eeuw is gegevensanalyse een van de meest gebruikte woorden in elk domein. Laten we vandaag dus kijken wat iedereen bedoelt met gegevensanalyse en enkele belangrijke technieken bij gegevensanalyse. Gegevensanalyse is het proces van het inspecteren, opschonen, transformeren en modelleren van gegevens met de bedoeling nuttige informatie te ontdekken die de besluitvorming kan verbeteren. In 2019 zei de econoom: '' s Werelds meest waardevolle bezit is niet langer olie, maar DATA '. Gegevensanalyse is nauw verbonden met gegevensvisualisatie. Op basis van de hoeveelheid gegevens die industrieën elke minuut genereren en op basis van hun behoefte zijn er verschillende technieken ontstaan. Laten we eens kijken wat ze zijn in de volgende sectie. In dit onderwerp gaan we meer te weten over soorten technieken voor gegevensanalyse.
Belangrijke soorten gegevensanalysetechnieken
Technieken voor gegevensanalyse zijn grofweg ingedeeld in twee typen die ze zijn
- Methoden op basis van wiskundige en statistische benaderingen
- Methoden gebaseerd op kunstmatige intelligentie en machine learning
Wiskundige en statistische benaderingen
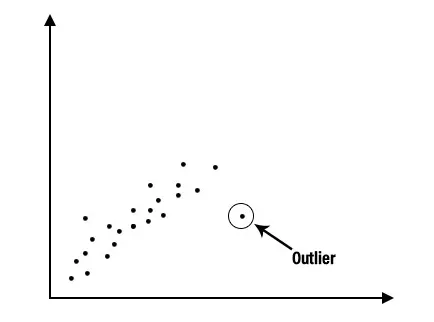
1. Beschrijvende analyse: Beschrijvende analyse is een belangrijke eerste stap voor het uitvoeren van statistische analyse. Het geeft ons een idee van de verdeling van gegevens, helpt bij het detecteren van uitbijters en stelt ons in staat om associaties tussen variabelen te identificeren, waardoor de gegevens worden voorbereid voor verdere statistische analyse. Beschrijvende analyse van een enorme gegevensset kan eenvoudig worden gemaakt door deze in twee categorieën op te splitsen, het zijn beschrijvende analyses voor elke individuele variabele en beschrijvende analyse voor combinaties van variabelen.
2. Regressieanalyse: Regressieanalyse is een van de dominante technieken voor gegevensanalyse die momenteel in de industrie wordt gebruikt. In dit soort techniek kunnen we de relatie zien tussen twee of meer interessante variabelen en in de kern bestuderen ze allemaal de invloed van een of meer onafhankelijke variabelen op de afhankelijke variabele. Om te zien of er een relatie is tussen de variabelen of niet, moeten we eerst de gegevens in een grafiek plotten en het zal duidelijk zijn of er een relatie is. Beschouw bijvoorbeeld de onderstaande grafiek als een duidelijk begrip.
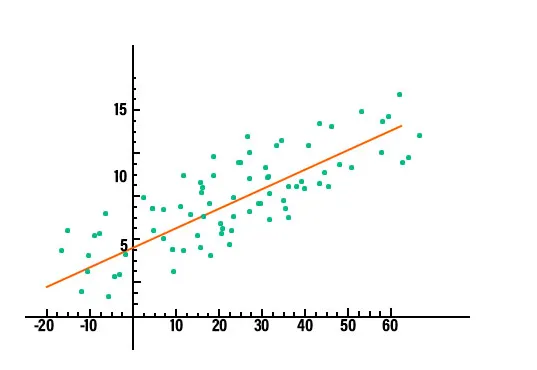
In datamining wordt deze techniek gebruikt om de waarden van een variabele, in die specifieke dataset, te voorspellen. Er zijn verschillende soorten regressiemodellen in gebruik. Een paar daarvan zijn lineaire regressie, logistieke regressie en meervoudige regressie.
3. Dispersieanalyse: Dispersie is de mate waarin een verdeling wordt uitgerekt of samengedrukt. In de wiskundige benadering kan de spreiding op twee manieren worden gedefinieerd, fundamenteel het verschil in waarden onderling en ten tweede het verschil tussen de gemiddelde waarde. Als het verschil tussen de waarde en het gemiddelde erg laag is, kunnen we zeggen dat de spreiding in dit geval minder is. En enkele van de gebruikelijke maten voor dispersie zijn variantie, standaardafwijking en interkwartielbereik.
4. Factoranalyse: Factoranalyse is een soort gegevensanalysetechniek die helpt bij het vinden van de onderliggende structuur in een reeks variabelen. Het helpt bij het vinden van onafhankelijke variabelen in de gegevensset die de patronen en modellen van relaties beschrijft. Het is de eerste stap op weg naar cluster- en classificatieprocedures. Factoranalyse is ook gerelateerd aan Principal Component Analysis (PCA), maar beide zijn niet identiek, we kunnen PCA noemen als de meer basale versie van verkennende factoranalyse
5. Tijdreeksen: Tijdreeksenanalyse is een gegevensanalysetechniek die zich bezighoudt met tijdreeksengegevens of trendanalyses. Laten we nu begrijpen wat tijdreeksgegevens zijn? Tijdreeksgegevens zijn gegevens in een reeks van bepaalde tijdsintervallen of perioden. Als we wetenschappelijk zien, worden de meeste metingen in de loop van de tijd uitgevoerd.
Methoden op basis van machine learning en kunstmatige intelligentie
1. Beslisbomen: beslissingsboomanalyse is een grafische weergave, vergelijkbaar met een boomachtige structuur waarin de problemen bij de besluitvorming kunnen worden gezien in de vorm van een stroomdiagram, elk met vertakkingen voor alternatieve antwoorden. Beslisbomen zijn van het top-down benaderingstype, met de eerste beslissingsknoop bovenaan, op basis van het antwoord bij de eerste beslissingsknoop zal het in takken worden verdeeld en het zal doorgaan totdat de boom bij een definitieve beslissing aankomt. De takken die niet meer verdelen worden bladeren genoemd.
2. Neurale netwerken: neurale netwerken zijn een reeks algoritmen die zijn ontworpen om het menselijk brein na te bootsen. Het staat ook bekend als het "netwerk van kunstmatige neuronen". De toepassingen van neuraal netwerk in datamining zijn zeer breed. Ze hebben een hoog acceptatievermogen voor lawaaierige gegevens en hoge nauwkeurigheidsresultaten. Op basis van de noodzaak worden momenteel vele soorten neurale netwerken gebruikt, enkele daarvan zijn terugkerende neurale netwerken en convolutionele neurale netwerken. Convolutionele neurale netwerken worden meestal gebruikt in beeldverwerking, natuurlijke taalverwerking en aanbevelingssystemen. Terugkerende neurale netwerken worden voornamelijk gebruikt voor handschrift en spraakherkenning.
3. Evolutionaire algoritmen: Evolutionaire algoritmen gebruiken de mechanismen geïnspireerd door recombinatie en selectie. Dit soort algoritmen zijn onafhankelijk van het domein en kunnen grote gegevenssets verkennen, patronen en oplossingen ontdekken. Ze zijn ongevoelig voor ruis in vergelijking met andere datatechnieken.
4. Fuzzy logic: het is een benadering in computergebruik op basis van "Mate van waarheid" in plaats van de algemene "Booleaanse logica" (waarheid / onwaar of 0/1). Zoals hierboven besproken in beslissingsbomen bij beslissingsknoop hebben we ofwel ja of nee als antwoord, wat als we een situatie hebben waarin we geen absoluut ja of absoluut nee kunnen beslissen? In deze gevallen speelt fuzzy logic een belangrijke rol. Het is een diverse waardevolle logica waarin de waarheidswaarde kan liggen tussen volledig waar en volledig onwaar, dat wil zeggen dat het elke echte waarde tussen 0 en 1 kan aannemen. Fuzzy-logica is van toepassing wanneer er een aanzienlijke hoeveelheid ruis in de waarden zit.
Conclusie
De lastige vraag waarmee alle bedrijven of bedrijven worden geconfronteerd, is welk type data-analysetechniek het beste voor hen is? We kunnen geen enkele techniek definiëren als de beste. In plaats daarvan kunnen we meerdere technieken proberen en kijken welke het beste bij onze gegevensset past en deze gebruiken. De bovengenoemde technieken zijn enkele van de belangrijke technieken die momenteel in de industrie worden gebruikt.
Aanbevolen artikelen
Dit is een gids voor soorten gegevensanalysetechnieken Hier bespreken we de soorten gegevensanalysetechnieken die momenteel in de industrie worden gebruikt. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Data Science Tools
- Data Science Platform
- Data Science Carrière
- Big Data-technologieën
- Clustering in machine learning
- Fuzzy Logic System | Wanneer te gebruiken, architectuur
- Volledige gids voor de implementatie van neurale netwerken
- Wat is gegevensanalyse?
- Maak beslisboom met voordelen
- Gids voor verschillende soorten gegevensanalyse