
Inleiding tot zakken en boosten
Bagging en Boosting zijn de twee populaire Ensemble-methoden. Laten we dus, voordat we Bagging en Boosting begrijpen, een idee hebben van wat ensemble Learning is. Het is de techniek om meerdere leeralgoritmen te gebruiken om modellen met dezelfde gegevensset te trainen om een voorspelling in machine learning te verkrijgen. Nadat we de voorspelling van elk model hebben verkregen, gebruiken we technieken voor het middelen van modellen zoals gewogen gemiddelde, variantie of max. Stemmen om de definitieve voorspelling te krijgen. Deze methode heeft tot doel betere voorspellingen te verkrijgen dan het individuele model. Dit resulteert in een betere nauwkeurigheid en vermijdt overfitting en vermindert bias en co-variantie. Twee populaire ensemble-methoden zijn:
- Bagging (Bootstrap aggregeren)
- stimuleren
bagging:
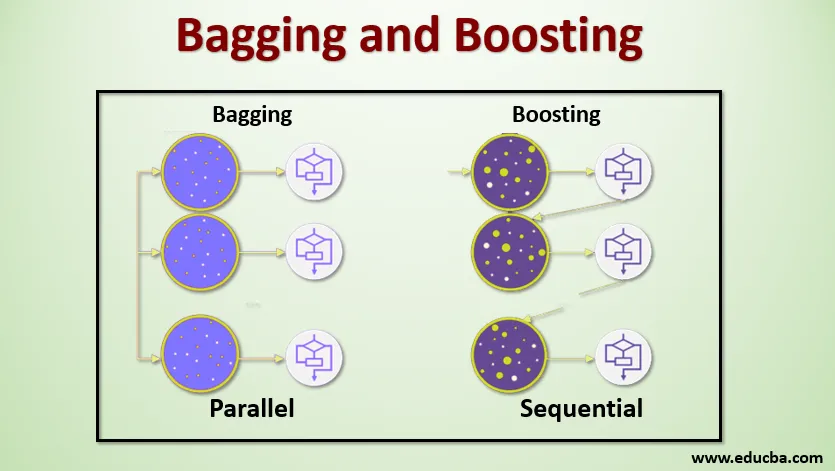
Bagging, ook wel Bootstrap Aggregating genoemd, wordt gebruikt om de nauwkeurigheid te verbeteren en het model te generaliseren door de variantie te verminderen, dwz door overfitting te voorkomen. Hierin nemen we meerdere subsets van de trainingsdataset. Voor elke subset nemen we een model met dezelfde leeralgoritmen zoals Beslisboom, Logistische regressie, enz. Om de uitvoer voor dezelfde set testgegevens te voorspellen. Als we eenmaal een voorspelling van elk model hebben, gebruiken we een techniek voor het middelen van het model om de uiteindelijke voorspellingsoutput te krijgen. Een van de beroemde technieken die in Bagging worden gebruikt, is Random Forest . In het Random forest gebruiken we meerdere beslissingsbomen.
Boosting :
Boosting wordt voornamelijk gebruikt om de bias en variantie in een begeleide leertechniek te verminderen. Het verwijst naar de familie van een algoritme dat zwakke leerlingen (basisleerling) omzet in sterke leerlingen. De zwakke leerling zijn de classificaties die slechts in geringe mate correct zijn met de feitelijke classificatie, terwijl de sterke leerlingen de classificaties zijn die goed zijn gecorreleerd met de daadwerkelijke classificatie. Enkele bekende technieken van Boosting zijn AdaBoost, GRADIENT BOOSTING, XgBOOST (Extreme Gradient Boosting). Dus nu weten we wat bagging en boosting zijn en wat hun rol is in Machine Learning.
Werken van zakken en boosten
Laten we nu eens kijken hoe bagging en boosting werkt:
bagging
Om de werking van Bagging te begrijpen, nemen we aan dat we een N-aantal modellen en een gegevensset D hebben. Waar m het aantal gegevens is en n het aantal functies in elke gegevens is. En we worden verondersteld binaire classificatie te doen. Eerst zullen we de dataset splitsen. Voorlopig splitsen we deze dataset op in training en testset. Laten we de trainingsdataset noemen, want waar is het totale aantal trainingsvoorbeelden.
Neem een voorbeeld van records uit de trainingsset en gebruik deze om het eerste model te trainen, zeg m1. Voor het volgende model, m2 neemt een nieuwe sample van de trainingsset en neemt een andere sample van de trainingsset. We zullen hetzelfde doen voor het N-aantal modellen. Omdat we de trainingsdataset opnieuw bemonsteren en er de monsters van nemen zonder iets uit de dataset te verwijderen, is het mogelijk dat we twee of meer trainingsgegevensrecords gemeenschappelijk hebben in meerdere monsters. Deze techniek om de trainingsgegevensset opnieuw te bemonsteren en het model aan het model te leveren, wordt rij-bemonstering met vervanging genoemd. Stel dat we elk model hebben getraind en nu de voorspelling op testgegevens willen zien. Omdat we werken aan binaire classificatie, kan de output 0 of 1 zijn. De testdataset wordt aan elk model doorgegeven en we krijgen een voorspelling van elk model. Laten we zeggen dat van N-modellen meer dan N / 2-modellen 1 voorspelden. Daarom kunnen we met de modelgemiddelde techniek zoals maximale stem zeggen dat de voorspelde output voor de testgegevens 1 is.
stimuleren
Bij het stimuleren nemen we records uit de dataset en geven deze achtereenvolgens door aan basale leerlingen, hier kunnen basale leerlingen elk model zijn. Stel dat we m aantal records in de dataset hebben. Vervolgens geven we een paar records door aan leerling BL1 en trainen we deze. Nadat de BL1 is getraind, geven we alle records uit de dataset door en kijken we hoe de Base-leerling werkt. Voor alle records die ten onrechte door de basisleerder zijn geclassificeerd, nemen we ze alleen en geven deze door aan andere basisleeraar, zeg BL2 en tegelijkertijd geven we de onjuiste records geclassificeerd door BL2 door aan training BL3. Dit gaat door tenzij en totdat we een specifiek aantal basismodellen voor leerling specificeren die we nodig hebben. Ten slotte combineren we de output van deze basisstudenten en creëren we een sterke leerling, waardoor de voorspellingskracht van het model wordt verbeterd. OK. Dus nu weten we hoe het Bagging en Boosting werkt.
Voor- en nadelen van bagging en boosting
Hieronder staan de belangrijkste voor- en nadelen.
Voordelen van zakken
- Het grootste voordeel van zakken is dat meerdere zwakke leerlingen beter kunnen werken dan een enkele sterke leerling.
- Het biedt stabiliteit en verhoogt de nauwkeurigheid van het machine learning-algoritme dat wordt gebruikt bij statistische classificatie en regressie.
- Het helpt bij het verminderen van variantie, dwz het voorkomt overfitting.
Nadelen van zakken
- Het kan leiden tot een hoge bias als het niet goed wordt gemodelleerd en kan dus leiden tot onderfitting.
- Omdat we meerdere modellen moeten gebruiken, wordt het rekenkundig duur en is het mogelijk niet geschikt in verschillende gevallen.
Voordelen van Boosting
- Het is een van de meest succesvolle technieken om de classificatieproblemen in twee klassen op te lossen.
- Het is goed in het omgaan met de ontbrekende gegevens.
Nadelen van Boosting
- Boosting is moeilijk realtime te implementeren vanwege de toegenomen complexiteit van het algoritme.
- Hoge flexibiliteit van deze technieken resulteert in een veelvoud van parameters dan een direct effect op het gedrag van het model.
Conclusie
Het belangrijkste is dat Bagging en Boosting een machine learning-paradigma zijn waarin we meerdere modellen gebruiken om hetzelfde probleem op te lossen en betere prestaties te krijgen. En als we zwakke leerlingen goed combineren, kunnen we een stabiel, nauwkeurig en robuust model verkrijgen. In dit artikel heb ik een basisoverzicht gegeven van Bagging en Boosting. In de komende artikelen leert u de verschillende technieken kennen die in beide worden gebruikt. Tot slot zal ik besluiten door u eraan te herinneren dat Bagging en Boosting tot de meest gebruikte technieken voor het leren van ensembles behoren. De echte kunst van het verbeteren van de prestaties ligt in uw begrip van wanneer u welk model moet gebruiken en hoe u de hyperparameters moet afstemmen.
Aanbevolen artikelen
Dit is een gids voor Bagging en Boosting. Hier bespreken we de introductie tot bagging en boosting en het werkt samen met voor- en nadelen. U kunt ook onze andere voorgestelde artikelen doornemen voor meer informatie -
- Inleiding tot ensemble-technieken
- Categorieën machine-algoritmen
- Gradient Boosting Algorithm met voorbeeldcode
- Wat is het boost-algoritme?
- Hoe beslissingsboom te maken?