

Gesplitste sollicitatievragen en antwoorden - Inleiding
Dus je hebt eindelijk je droombaan in Splunk gevonden, maar je vraagt je af hoe je het Splunk Interview kunt kraken en wat de waarschijnlijke Splunk Interview-vragen voor 2018 kunnen zijn. Elk interview is anders en de reikwijdte van een baan is ook anders. Met dit in gedachten hebben we de meest voorkomende Splunk-interviewvragen en -antwoorden voor 2018 ontworpen om u te helpen succes te behalen in uw interview.Hieronder staan de meest bruikbare Splunk-interviewvragen en -antwoorden. Deze Topvragen zijn als volgt verdeeld in twee delen:
Deel 1 - Gesplitste sollicitatievragen (basis)
Dit eerste deel behandelt basisvragen en antwoorden over Splunk-interviews.
1. Wat is Splunk? Waarom wordt Splunk gebruikt voor het analyseren van machinegegevens?
Antwoord:
Een van de meest gebruikte analysetools die er is, is Microsoft Excel en het nadeel hiervan is dat Excel slechts tot 1048576 rijen kan laden en dat de machinegegevens over het algemeen enorm zijn. Splunk is handig in de omgang met machinaal gegenereerde gegevens (big data), de gegevens van servers, apparaten of netwerken kunnen eenvoudig in Splunk worden geladen en kunnen worden geanalyseerd om te controleren op eventuele zichtbaarheid van bedreigingen, compliance, beveiliging enz. Het kan ook worden gebruikt voor applicatiebewaking.
2.Leg uit hoe Splunk werkt
Antwoord:
Dit zijn de veelgestelde Splunk-interviewvragen die in een interview worden gesteld. Gegevens worden in Splunk geladen met behulp van de expediteur die fungeert als een interface tussen de Splunk-omgeving en de buitenwereld, waarna deze gegevens worden doorgestuurd naar een indexeerder waar de gegevens lokaal of in een cloud worden opgeslagen. De indexer indexeert de machinegegevens en slaat deze op de server op. Zoekkop is de GUI die wordt verstrekt door Splunk voor het zoeken en analyseren (zoeken, visualiseren, analyseren en uitvoeren van verschillende andere functies) van de gegevens.
Implementatieserver beheert alle componenten van Splunk zoals indexer, forwarder en zoekkop in Splunk-omgeving. 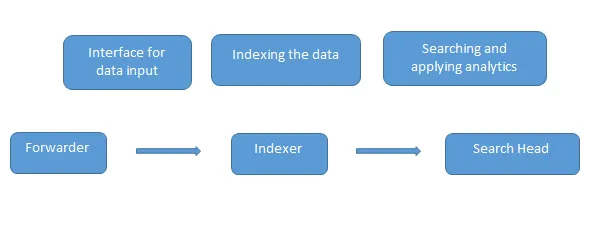
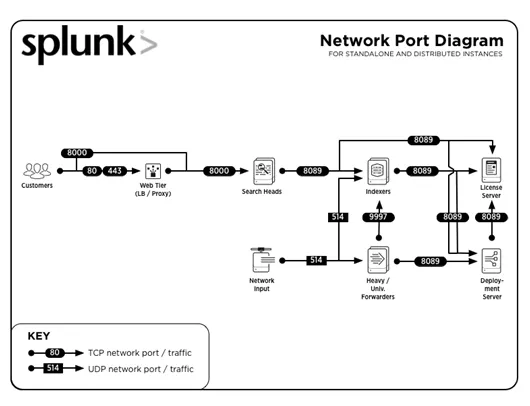
3. Wat zijn algemene poortnummers die door Splunk worden gebruikt?
Antwoord :
Veelgebruikte poortnummers waarop services worden uitgevoerd (standaard) zijn:
| Onderhoud | Poortnummer |
| Management / REST API | 8089 |
| Zoekkop / Indexer | 8000 |
| Zoek hoofd | 8065, 8191 |
| Indexer cluster peer knooppunt / Zoek hoofd clusterlid | 9887 |
| Indexer | 9997 |
| Indexer / Forwarder | 514 |
Laten we doorgaan naar de volgende Splunk-interviewvragen.
4. Waarom alleen Splunk gebruiken?
Antwoord:
Er zijn veel alternatieven voor Splunk die er veel concurrentie aan geven, sommige zijn hieronder:
• ELK / Logstash (open source)
Elasticsearch wordt gebruikt om te zoeken zoals de zoekkop in Splunk, Logstash is voor gegevensverzameling die vergelijkbaar is met de expediteur die wordt gebruikt in Splunk, en Kibana wordt gebruikt voor gegevensvisualisatie (zoekkop doet hetzelfde in Splunk)
• Graylog (open source met commerciële versie)
Graylog is nog een ander hulpmiddel dat vorig jaar werd genoemd met de release 1.0. Vergelijkbaar met ELK-stack heeft Graylog ook verschillende componenten die Elasticsearch als kerncomponent gebruiken, maar de gegevens worden opgeslagen in Mongo DB en gebruiken Apache Kafka. Het heeft twee versies, een kernversie die gratis beschikbaar is en de enterprise-versie met functies zoals archiveren.
• Sumo Logic (cloudservice)
Dus wat Splunk het beste van allemaal maakt, is dat Splunk wordt geleverd als een enkel pakket van de gegevensverzamelaar, opslag en de ingebouwde analysetool. Splunk is ook schaalbaar en biedt ondersteuning / professionele hulp voor de enterprise-editie.
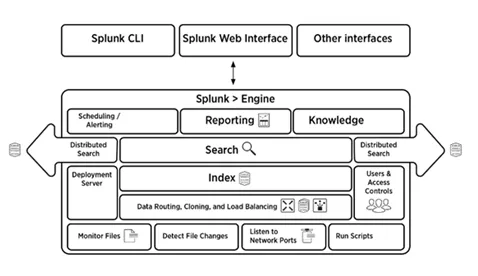
5. Leg in het kort de Splunk-architectuur uit
Antwoord:
De onderstaande afbeelding geeft een kort overzicht van de Splunk-architectuur en de componenten ervan.
Deel 2 - Gesplitste interviewvragen (geavanceerd)
Laten we nu eens kijken naar de geavanceerde Splunk-interviewvragen.
6. Wat zijn de componenten van Splunk-architectuur?
Antwoord:
Er zijn vier componenten in de Splunk-architectuur. Zij zijn:
- Indexer: indexeert machinegegevens
- Forwarder: stuurt logboeken door naar index
- Zoekkop: biedt een GUI voor het zoeken
- Implementatieserver: beheert de Splunk-componenten (indexer, forwarder en zoekkop) in een gedistribueerde omgeving
7. Geef een paar use cases van Knowledge Objects.
Antwoord :
Dit zijn de veelgestelde Splunk-interviewvragen in een interview. Kennisobjecten kunnen in veel domeinen worden gebruikt. Enkele voorbeelden zijn:
Applicatiebewaking: dit kan worden gebruikt om applicaties in realtime te bewaken met geconfigureerde waarschuwingen die de beheerders / gebruikers op de hoogte stellen wanneer een applicatie crasht.
Fysieke beveiliging: in het geval van een overstroming / vulkanische enz. Kunnen de gegevens worden gebruikt om inzichten te verkrijgen als uw organisatie met dergelijke gegevens te maken heeft.
Netwerkbeveiliging: u kunt een veilige omgeving creëren door het IP-adres van onbekende apparaten op een zwarte lijst te zetten, waardoor datalekken in elke organisatie worden beperkt.
Werknemersbeheer: Werknemersuitval is een van de uitdagingen waarmee elke organisatie wordt geconfronteerd en tijdens de opzegtermijn kan de activiteit van de werknemer worden gevolgd om de gegevens van de organisatie te beschermen, waardoor hun activiteit wordt bewaakt en andere werknemers in de opzegtermijn worden beperkt om niet hetzelfde te doen .
8. Uitleg Search Factor (SF) & Replication Factor (RF)
Antwoord:
Dit zijn de terminologieën die worden gebruikt in Splunk-clusteringstechnieken. Indexer cluster is een speciaal geconfigureerde groep Splunk Enterprise-indexers die externe gegevens repliceert en wordt gebruikt voor noodherstel.
In termen van de Splunk-documentatiezoekactie kan de factor worden omschreven als "Het aantal doorzoekbare kopieën van gegevens dat een indexercluster bijhoudt. De standaardwaarde van de zoekfactor is 2 ”, terwijl de replicatiefactor wordt gedefinieerd als het aantal kopieën van gegevens dat het cluster bijhoudt.
Indexercluster heeft zowel een zoekfactor als een replicatiefactor, terwijl het zoekhoofdcluster alleen een zoekfactor heeft
Laten we doorgaan naar de volgende Splunk-interviewvragen.
9. Wat zijn Splunk-emmers? Verklaar de emmerlevenscyclus.
Antwoord:
De mappen waarin de geïndexeerde gegevens worden opgeslagen, staan bekend als Splunk-emmers en deze hebben gebeurtenissen van de bepaalde periode. De levenscyclus van de Splunk-emmer bestaat uit vier fasen: warm, warm, koud, bevroren en ontdooid.
- Hot - deze bucket bevat de recent geïndexeerde gegevens en is open voor schrijven.
- Warm - Nadat de gegevens in een warme emmer vallen, afhankelijk van uw gegevensbeleid, worden deze naar warme emmers verplaatst
- Koud - De volgende fase na warm is de koude fase waarin de gegevens niet kunnen worden bewerkt.
- Bevroren - Standaard verwijdert de indexer de gegevens van bevroren emmers, maar deze kunnen ook worden gearchiveerd.
- Ontdooid - Het ophalen van informatie uit gearchiveerde bestanden (bevroren emmer) staat bekend als ontdooien.
10. Waarom zouden we Splunk Alert gebruiken? Wat zijn de verschillende opties tijdens het instellen van waarschuwingen?
Antwoord:
De status van waakzaam zijn voor elke mogelijke fout staat bekend als alert en in Splunk kunnen omgevingswaarschuwingen optreden als gevolg van verbindingsfouten of beveiligingsovertredingen of het overtreden van door de gebruiker gemaakte regels.
Bijvoorbeeld het verzenden van meldingen of een rapport van de gebruikers die na het gebruik van hun drie pogingen in een portal niet zijn ingelogd naar de applicatiebeheerder.
Verschillende opties die beschikbaar zijn tijdens het instellen van waarschuwingen zijn:
- Er kan een webhook worden gemaakt om de waarschuwingen naar hipchat of GitHub te schrijven.
- Voeg resultaten, .csv of pdf toe of in lijn met de hoofdtekst van het bericht, zodat de hoofdoorzaak van de melding kan worden vastgesteld.
- Kaartjes kunnen worden gemaakt en waarschuwingen kunnen worden gesmoord vanaf een machine of een IP.
Aanbevolen artikel
Dit is een gids voor Lijst met Splunk Interviewvragen en antwoorden, zodat de kandidaat deze Splunk Interviewvragen en antwoorden gemakkelijk kan opnemen. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Sollicitatievragen voor SAS-systeem - Top 10 nuttige vragen
- 10 uitstekende sollicitatievragen voor Tableau die u moet weten
- 15 meest succesvolle Oracle sollicitatievragen en antwoorden
- Interviewvragen netwerkbeveiliging - Meest gevraagd en gevraagd
- Splunk vs Nagios