
Inleiding tot versterkingsleren
Versterkingsleren is een vorm van machinaal leren en daarom maakt het ook deel uit van kunstmatige intelligentie. Wanneer het wordt toegepast op systemen, voert het systeem stappen uit en leert het op basis van de uitkomst van stappen om een complex doel te bereiken dat het systeem moet bereiken.
Versterking leren begrijpen
Laten we proberen om onder de werking van versterkingsleren te werken met behulp van 2 eenvoudige use cases:
Zaak 1
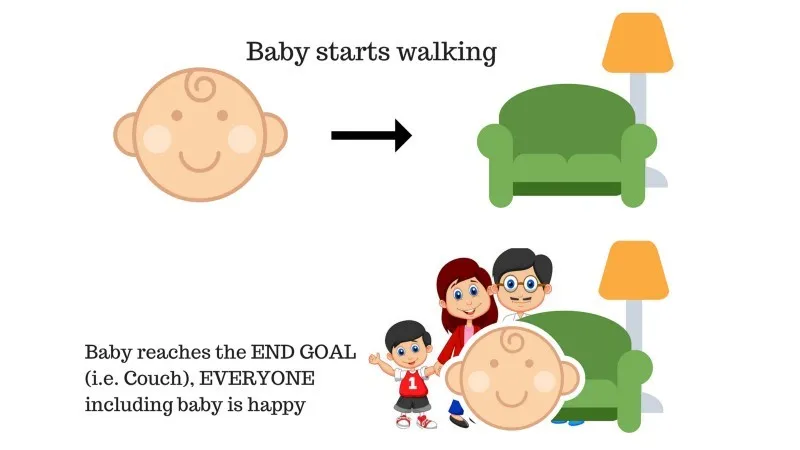
Er is een baby in de familie en ze is net begonnen met lopen en iedereen is er heel blij mee. Op een dag proberen de ouders een doel te stellen, laten we de baby de bank bereiken en kijken of de baby dat kan.
Resultaat van geval 1: de baby bereikt met succes de bank en dus is iedereen in het gezin erg blij dit te zien. Het gekozen pad komt nu met een positieve beloning.
Punten: Beloning + (+ n) → Positieve beloning.
Bron: https://images.app.goo.gl/pGCXJ1N1bzLAer126
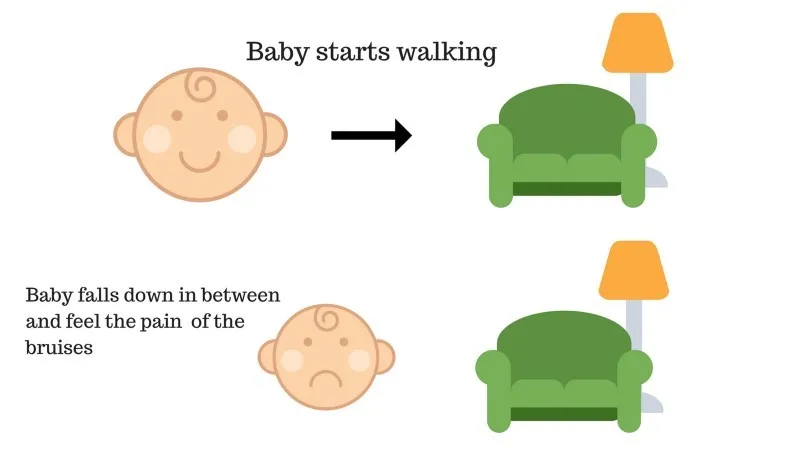
Geval # 2
De baby kon de bank niet bereiken en de baby is gevallen. Het doet zeer! Wat zou de reden kunnen zijn? Er kunnen enkele obstakels zijn in het pad naar de bank en de baby is op obstakels gevallen.
Resultaat van geval 2: de baby valt op enkele obstakels en ze huilt! Oh, dat was slecht, leerde ze, om de volgende keer niet in de val van een obstakel te vallen. Het gekozen pad komt nu met een negatieve beloning.
Punten: Beloningen + (-n) → Negatieve beloning.
Bron: https://images.app.goo.gl/FRfd8cUqrQRLe6sZ7
Dit hebben we nu gevallen 1 en 2 gezien, versterking leren, in concept, doet hetzelfde behalve dat het niet menselijk is maar in plaats daarvan computationeel wordt uitgevoerd.
Versterking stapsgewijs gebruiken
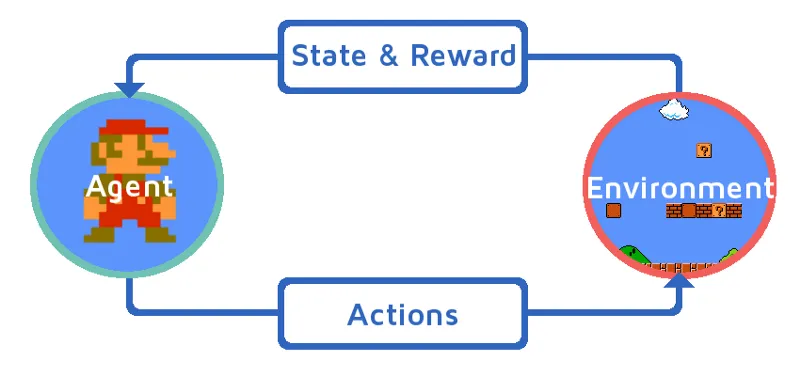
Laten we het versterkingsleren begrijpen door een versterkingsagent op een stapsgewijze manier te brengen. In dit voorbeeld is Mario voor het leren van versterkingen, die zelfstandig leert spelen:
Bron: https://images.app.goo.gl/Kj44uvBzWzMw1QzE9
- De huidige status van de Mario-spelomgeving is S_0. Omdat het spel nog niet is gestart en de Mario op zijn plaats staat.
- Vervolgens wordt het spel gestart en beweegt de Mario, de Mario ie RL-agent neemt en actie, laten we zeggen A_0.
- Nu is de status van de game-omgeving S_1 geworden.
- Ook heeft de RL-agent, dat wil zeggen de Mario nu een positief beloningspunt toegewezen gekregen, R_1, waarschijnlijk omdat de Mario nog in leven is en er geen gevaar is aangetroffen.
Nu blijft de bovenstaande lus lopen totdat de Mario eindelijk dood is of de Mario zijn bestemming bereikt. Dit model geeft continu de actie, beloning en status weer.
Maximalisatiebeloningen
Het doel van versterkend leren is om beloningen te maximaliseren door rekening te houden met bepaalde andere factoren, zoals de korting op beloningen; we zullen kort uitleggen wat met korting wordt bedoeld aan de hand van een illustratie.
De cumulatieve formule voor kortingsbeloningen is als:
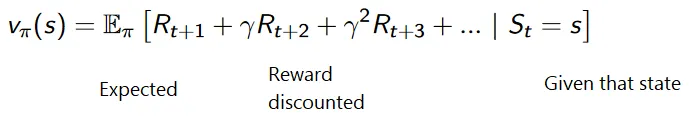
Kortingsbeloningen
Laten we dit door een voorbeeld begrijpen:
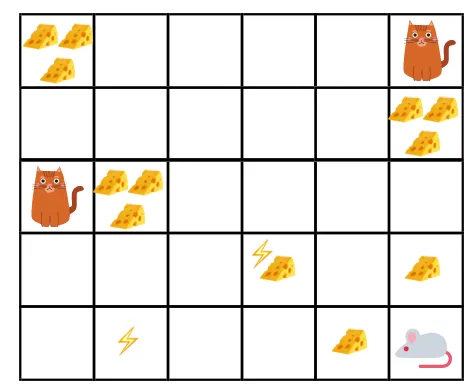
- In de gegeven figuur is het doel: de muis in het spel moet zoveel kaas eten voordat hij door een kat wordt opgegeten of zonder elektroshock.
- Nu kunnen we aannemen dat hoe dichter we bij de kat of de elektrische val staan, hoe groter de kans is dat de muis wordt opgegeten of geschokt.
- Dit betekent dat, zelfs als we de volle kaas bij het elektrische schokblok of bij de kat hebben, hoe riskanter het is om daarheen te gaan, het is beter om de kaas in de buurt te eten om elk risico te vermijden.
- Dus hoewel, we hebben een "blok1" kaas die vol is en ver van de kat en het blok met elektrische schokken is en de andere "blok2", die ook vol is, maar zich dicht bij de kat of het blok met elektrische schokken bevindt, het latere kaasblok, dat wil zeggen "blok2", wordt meer beloond met beloningen dan het vorige.
Bron: https://images.app.goo.gl/8QrH78FjmRVs5Wxk8
Bron: https://cdn-images-1.medium.com/max/800/1*l8wl4hZvZAiLU56hT9vLlg.png.webp
Soorten versterkingsleren
Hieronder staan de twee soorten versterkingsleren met hun voor- en nadelen:
1. Positief
Wanneer de sterkte en frequentie van het gedrag worden verhoogd als gevolg van het optreden van een bepaald gedrag, staat dit bekend als positief leren van versterking.
Voordelen: de prestaties zijn gemaximaliseerd en de verandering blijft langer behouden.
Nadelen: resultaten kunnen worden verminderd als we te veel versterking hebben.
2. Negatief
Het is het versterken van gedrag, vooral vanwege het verdwijnen van de negatieve term.
Voordelen: gedrag is verhoogd.
Nadelen: alleen het minimale gedrag van het model kan worden bereikt met behulp van negatief versterkend leren.
Waar moet Versterking leren gebruiken?
Dingen die gedaan kunnen worden met Versterkingsleren / Voorbeelden. Hier volgen de gebieden waarop Versterkingsleren tegenwoordig wordt gebruikt:
- Gezondheidszorg
- Onderwijs
- Spellen
- Computer visie
- Bedrijfsmanagement
- Robotics
- Financiën
- NLP (natuurlijke taalverwerking)
- vervoer
- Energie
Carrières in leren van versterking
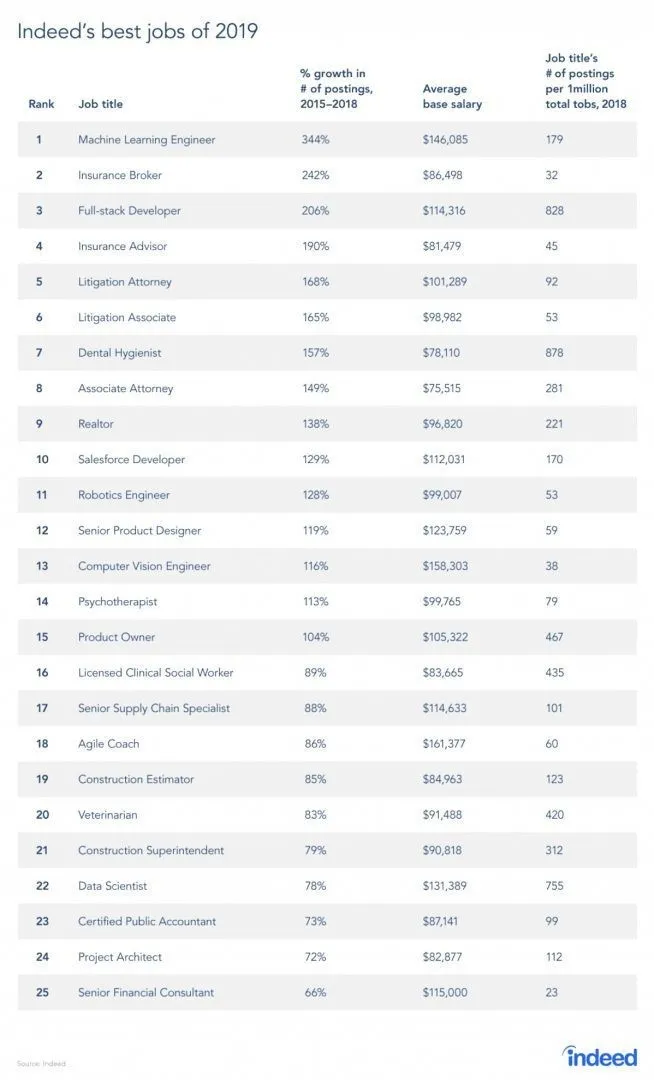
Er is inderdaad een rapport van de vacaturesite, aangezien RL een tak van Machine learning is, volgens het rapport is Machine Learning de beste taak van 2019. Hieronder is de momentopname van het rapport. Volgens de huidige trends komt een machine learning-ingenieur met een enorm gemiddeld salaris van $ 146.085 en met een groeipercentage van 344 procent.
Bron: https://i0.wp.com/www.artificialintelligence-news.com/wp-content/uploads/2019/03/indeed-top-jobs-2019-best.jpg.webp?w=654&ssl=1
Vaardigheden voor het leren van versterking
Hieronder staan de vaardigheden die nodig zijn voor het leren van versterking:
1. Basisvaardigheden
- Waarschijnlijkheid
- Statistieken
- Datamodellering
2. Programmeervaardigheden
- Basisprincipes van programmeren en informatica
- Ontwerp van software
- In staat om Machine Learning-bibliotheken en algoritmen toe te passen
3. Programmeertalen voor machinaal leren
- Python
- R
- Hoewel er ook andere talen zijn waar Machine Learning-modellen kunnen worden ontworpen, zoals Java, C / C ++, maar Python en R zijn de meest favoriete talen die worden gebruikt.
Conclusie
In dit artikel zijn we begonnen met een korte introductie over leren van versterking, en daarna hebben we ons verdiept in de werking van RL en verschillende factoren die een rol spelen bij de werking van RL-modellen. Daarna hadden we enkele voorbeelden uit de praktijk gegeven om het onderwerp nog beter te begrijpen. Tegen het einde van dit artikel moet men een goed begrip hebben van de werking van versterkend leren.
Aanbevolen artikelen
Dit is een gids voor Wat is versterkingsleren ?. Hier bespreken we de functie en verschillende factoren die betrokken zijn bij de ontwikkeling van versterkingsleermodellen, met voorbeelden. U kunt ook onze andere gerelateerde artikelen doornemen voor meer informatie -
- Soorten algoritmen voor machine learning
- Inleiding tot kunstmatige intelligentie
- Hulpmiddelen voor kunstmatige intelligentie
- IoT-platform
- Top 6 programmeertalen voor machinaal leren