

Introductie tot Hashing in DBMS
Als we het hebben over de enorme databasestructuur en hun complexiteit, wordt het erg inefficiënt om naar alle indexen te zoeken en wordt het bereiken van de gewenste gegevens erg vaag en een complexe mogelijkheid. Door gebruik te maken van de hashingtechniek kunnen deze toestanden worden bereikt en kan een directe wijzer worden toegewezen om de exacte en de directe locatie op de schijf voor het specifieke record te kennen zonder gebruik te maken van de complexe indexstructuur. De gegevens in het geval van hashing-techniek worden opgeslagen in de vorm van gegevensblokken waarvan het adres wordt gegenereerd door gebruik te maken van de functie die typisch bekend staat als de hashing-functie. De locatie in het geheugen waar deze zich bevindt en records worden opgeslagen, wordt gegevensblokken of gegevensemmers genoemd.
Soorten hashing in DBMS
Er zijn doorgaans twee soorten hashingtechnieken in DBMS:
1. Statisch slaan
2. Dynamisch slaan
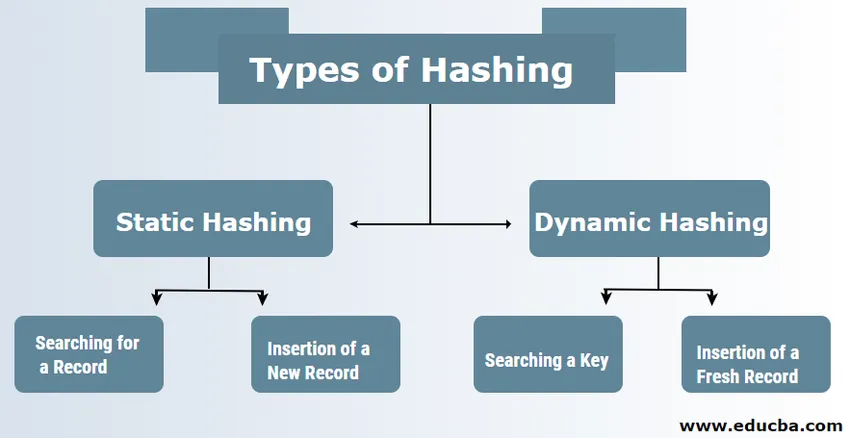
1) Statische hash
In het geval van statische hashing zijn de gevormde gegevensset en het bucket-adres hetzelfde. Dit betekent dat als we proberen het adres voor USER_ID = 113 te genereren door gebruik te maken van de hashing-functiemodulus 5, dit ons altijd de resultante als 3 oplevert met hetzelfde uitziende bucket-adres. In dit geval zal het adres van de geleverde emmer niet worden gewijzigd. Daarom blijft het aantal emmers constant gedurende de operatie.
Werking van statisch getypte hashing
een. Zoeken naar een record: als het record moet worden gevonden, wordt exact dezelfde hashfunctie gebruikt om het adres en pad van de gegevensbak op te halen met de gegevens die worden opgeslagen.
b. Invoegen van een nieuw record: als een nieuw en nieuw record in een tabel wordt geplaatst, wordt een adres gegenereerd voor een nieuw record op basis van de hashing-sleutel, waardoor het record op die locatie wordt opgeslagen.
- Verwijderen van het record: om het record te kunnen verwijderen, moet eerst dat record worden opgehaald dat kan worden verwijderd. Zodra die taak is voltooid, moeten de records voor dat geheugenadres worden verwijderd.
- Updaten van een record: Om het record bij te werken, zoeken we eerst het record door gebruik te maken van de op hash gebaseerde functie en als dat eenmaal is gedaan, kan worden gezegd dat ons gegevensrecord in een bijgewerkte staat is. Om een nieuw record in het bestand in te voegen en het adres dat is gegenereerd vanuit de hash-gebaseerde functie en de gegevensemmer niet leeg is of als de gegevens al aanwezig zijn in het opgegeven adres. Deze situatie die zich met name voordoet in het geval van statisch hashen, kan beter de emmeroverloop worden genoemd en daarom zijn er enkele manieren om dit probleem op te lossen, zoals:
(i) Open hash: als een hashfunctie het adres genereert waarvoor de gegevens al in de opgeslagen status kunnen worden gezien, wordt in dat geval automatisch het volgende niveau van de bucket toegewezen. Dit mechanisme kan een lineaire sondeertechniek worden genoemd.
Als bijvoorbeeld R3 het nieuwe adres is dat moet worden gezet, dan zal de op hash gebaseerde functie adres genereren als het nummer 102 voor het R3-adres. Het gegenereerde adres bevindt zich in de volledige status en daarom is het systeem bedoeld om te zoeken naar de nieuwe gegevensemmer die 113 is en R3 aan die gegevensemmer toe te wijzen.
(ii) Gesloten hashen: wanneer de emmers volledig vol zijn, wordt vervolgens een nieuwe emmer toegewezen voor een bepaald hashresultaat dat direct wordt gekoppeld aan het eerder voltooide en daarom wordt deze methode de overloopkettingtechniek genoemd.
R3 is bijvoorbeeld het nieuwe adres dat in de nieuwe tabel moet worden geplaatst. De hashing-functie wordt gebruikt om het adres als het nummer 110 te genereren. Deze bucket is op zijn beurt vol en kan daarom geen nieuwe gegevens ontvangen en daarom wordt na 100 een nieuwe bucket geplaatst.
2) Dynamische Hashing
Dit soort op hash gebaseerde methode kan worden gebruikt om de basisproblemen van statisch gebaseerde hashing op te lossen, zoals die overloop van emmers, omdat de gegevensemmers kunnen groeien en krimpen met de grootte, het is meer ruimte-geoptimaliseerde techniek en daarom wordt het genoemd als uitschuifbaar op hash gebaseerde methode. In deze methode wordt het hashen dynamisch gemaakt, wat betekent dat de invoegactiviteit of verwijdering is toegestaan zonder slechte prestaties te leveren.
een. Een sleutel zoeken: bereken het op hash gebaseerde adres van de vereiste sleutel en controleer het aantal bits dat wordt gebruikt in het geval van een map die bekend staat als i. Dan worden degenen die het minst significant zijn van de I-bits genomen uit de map die een idee geeft over de index uit de map. Door gebruik te maken van die indexwaarde, gaat u naar de directory om het bucket-adres te vinden om naar de huidige records te zoeken.
b. Een nieuw record invoegen: eerst moet u exact dezelfde ophaalprocedure volgen die ergens in de emmer moet eindigen. Zoek naar de ruimte in die bucket en plaats de records erin. Als die gemaakte bucket compleet en vol is, wordt de bucket gesplitst en worden de records opnieuw verdeeld.
De laatste twee bits van de cijfers 2 en 4 zijn bijvoorbeeld 00. Ze gaan dus in de bucket B0 enzovoort volgens de modulusfunctie. Sleutel 9 heeft een adres van 10001 dat aanwezig moet zijn in de eerste bak, maar wordt gesplitst en gaat naar de nieuwe bak B1 en dit gaat door totdat alle emmers en sleutels dynamisch zijn gehasht. De hash-functie wordt gebruikt op een manier waarbij de hash-functie wordt gebruikt om de kolom en de waarde ervan te kiezen om het adres te genereren. Maximum aantal keren dat de hashfunctie gebruik maakt van de primaire sleutel die op zijn beurt wordt gebruikt om de adressen van het gegevensblok te genereren. Het is een eenvoudige wiskundige functie waarbij de primaire sleutel ook als het gegevensblokadres kan worden beschouwd, wat betekent dat elke rij met hetzelfde adres als dat van de primaire sleutel in het gegevensblok wordt opgeslagen.
Aanbevolen artikelen
Dit is een gids voor Hashing in DBMS. Hier bespreken we de introductie en verschillende soorten hashing in DBMS, inclusief statische hashing en dynamische hashing, samen met voorbeelden. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Gegevensmodellen in DBMS
- Voordelen van DBMS
- Data Integration Tool
- Wat is RDBMS?