
Overzicht van TensorBoard
TensorBoard is een visualisatiekader van tensorflow voor het begrijpen en inspecteren van de algoritmestroom van machine learning.
De evaluatie van het machine learning-model kan worden gedaan met veel statistieken, zoals verlies, nauwkeurigheid, modelgrafiek en nog veel meer. De prestaties van het machine learning-algoritme zijn afhankelijk van modelselectie en hyperparameters die in het algoritme worden ingevoerd. Experimenten worden uitgevoerd door de waarden van die parameters te wijzigen.
De Deep learning-modellen zijn net als een zwarte doos, het is moeilijk om de verwerking binnenin te vinden. Het is belangrijk om inzicht te krijgen om het model te bouwen. Met behulp van visualisatie kunt u weten welke parameters u moet wijzigen met welk bedrag om de verbetering van de modelprestaties te krijgen. Dus TensorBoard is een belangrijk hulpmiddel om elk tijdperk tijdens de modeltraining te visualiseren.
Installatie
Voer de volgende opdracht uit om het tensorboard met behulp van pip te installeren:
pip install tensorboard
Als alternatief kan het worden geïnstalleerd met behulp van het conda-commando,
Conda install tensorboard
Gebruik
Tensorboard gebruiken met Keras-model:
Keras is een open-source bibliotheek voor diepgaande leermodellen. Het is een bibliotheek op hoog niveau die kan worden uitgevoerd op de top van tensorflow, theano, enz.
Om de tensorflow- en Keras-bibliotheek te installeren met behulp van pip:
pip install tensorflow pip install Keras
Laten we een eenvoudig voorbeeld van classificatie nemen met behulp van de MNIST-gegevensset. MNIST is een Engelse numerieke gegevensset die afbeeldingen van getallen van 0-9 bevat. Het is beschikbaar met Keras-bibliotheek.
- Importeer de bibliotheek tensorflow zoals we Keras zullen gebruiken met tensorflow backend.
import tensorflow as tf
- Laad eerst de MNIST-gegevensset van Keras in training- en testgegevensset.
mnist = tf.keras.datasets.mnist

- Het sequentiële model wordt gemaakt met,
tf.keras.models.Sequential
- Om het model te trainen wordt Model.fit () gebruikt. Logboeken kunnen worden gemaakt en opgeslagen met,
tf.keras.callback.TensorBoard
- Om histogramcomputing in te schakelen,
histogram_freq=1.
Het is standaard uitgeschakeld.
De code voor de hierboven besproken classificatie van MNIST-gegevensset is als volgt:
# Simple NN to classify handwritten digits from MNIST dataset
import tensorflow as tf
import datetime
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0
def create_model(): return tf.keras.models.Sequential(( tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
))
model = create_model() model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=('accuracy'))
log_dir="logs/fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
model.fit(x=x_train, y=y_train, epochs=5, validation_data=(x_test, y_test),
callbacks=(tensorboard_callback))
Om het tensorboard op de lokale server te starten, gaat u naar de directorylocatie waar tensorflow is geïnstalleerd en voert u de volgende opdracht uit:
tensorboard --logdir=/path/to/logs/files

-
scalars
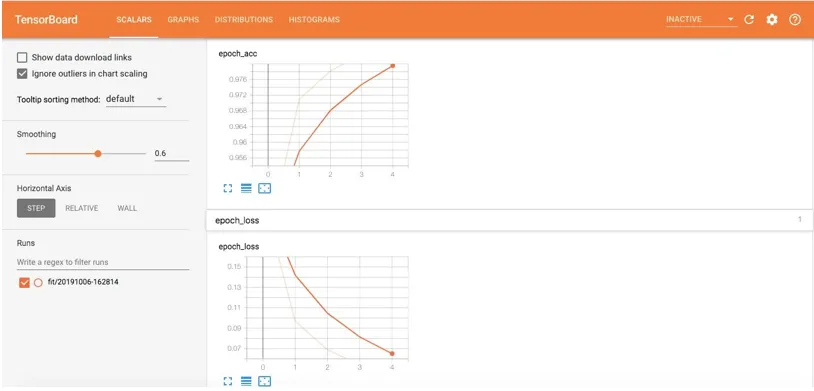
Scalars tonen verandering met elk tijdperk. De bovenstaande afbeelding toont de grafiek van nauwkeurigheid en verlies na elk tijdperk. Epoch_acc en epoch_loss zijn trainingsnauwkeurigheid en trainingsverlies. Terwijl epoch_val_acc en epoch_val_loss de nauwkeurigheid en het verlies van validatiegegevens zijn.
De lichtere oranje lijnen tonen exacte nauwkeurigheid of verlies en de donkerdere geeft vloeiende waarden weer. Smoothing helpt bij het visualiseren van de algemene trend in de gegevens.
-
grafieken
De grafiekpagina helpt u om de grafiek van uw model te visualiseren. Dit helpt u om te controleren of het model correct is gebouwd of niet.
Om de grafiek te visualiseren, moeten we een sessie maken en vervolgens het TensorFLow FileWriter-object. Om het writer-object te maken, moeten we het pad passeren waar de samenvatting is opgeslagen en sess.graph als het argument.
writer = tf.summary.FileWriter(STORE_PATH, sess.graph)
tf.placeholder () en tf.Variable () worden gebruikt voor placeholders en variabelen in de tensorflow-code.
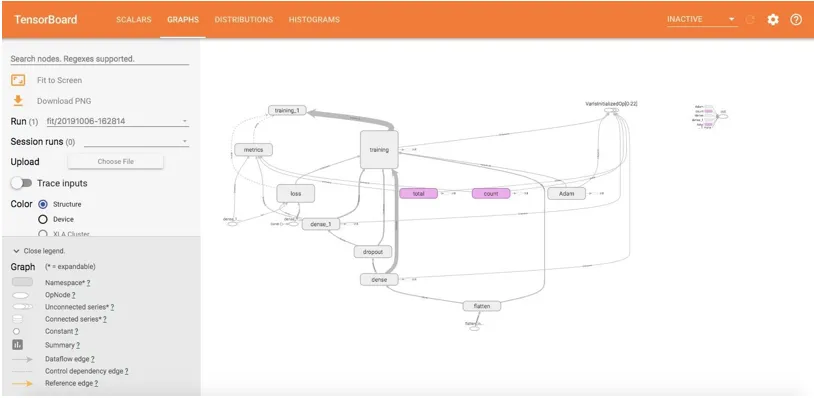
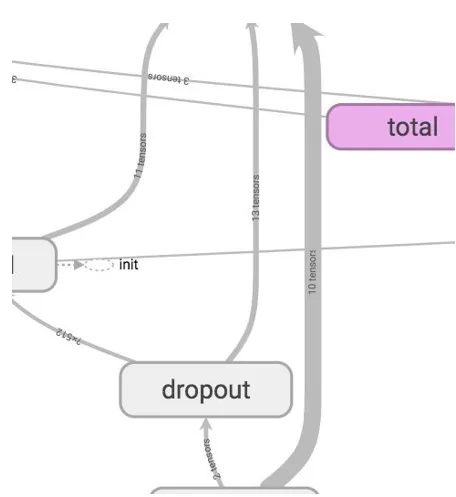
Dit toont de grafische visualisatie van het model dat we hebben gebouwd. Alle afgeronde rechthoeken zijn naamruimten. En ovalen tonen de wiskundige bewerkingen.
Constanten worden weergegeven als kleine cirkels. Om rommel in de grafiek te verminderen, doet tensorboard enkele vereenvoudigingen door gestippelde ovalen of afgeronde rechthoeken met stippellijnen te gebruiken. Dit zijn de knooppunten die zijn gekoppeld aan veel andere knooppunten of alle knooppunten. Ze worden dus bewaard zoals gestippeld in de grafiek en hun details zijn te zien in de rechterbovenhoek. In de rechterbovenhoek is koppeling met verlopen, verloopafnames of init-knooppunten voorzien.
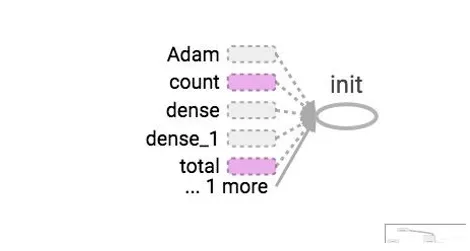
Om het aantal tensoren te kennen die binnenkomen en uit elk knooppunt komen, kunt u de randen in de grafiek zien. De grafiekranden beschrijven het aantal tensoren dat in de grafiek stroomt. Dit helpt bij het identificeren van de invoer- en uitvoerdimensies van elk knooppunt. Dit helpt bij het debuggen van elk probleem.
-
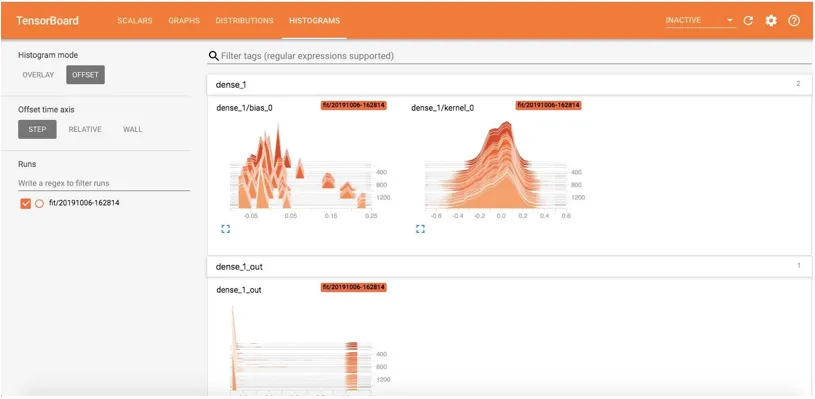
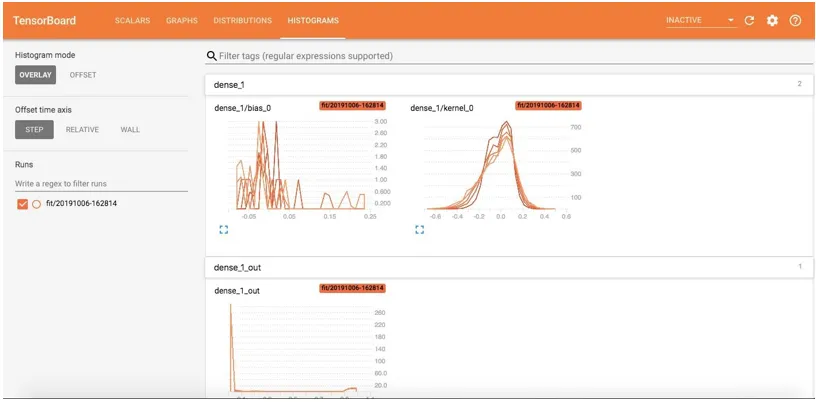
Verdelingen en histogrammen
Dit toont de tensor-distributies met de tijd en we kunnen ook gewichten en vooroordelen zien. Dit toont de voortgang van inputs en outputs in de loop van de tijd voor elk tijdperk. Er zijn twee weergaveopties:
Offset en overlay.
De offset-weergave van histogrammen is als volgt:
De overlayweergave van het histogram is:
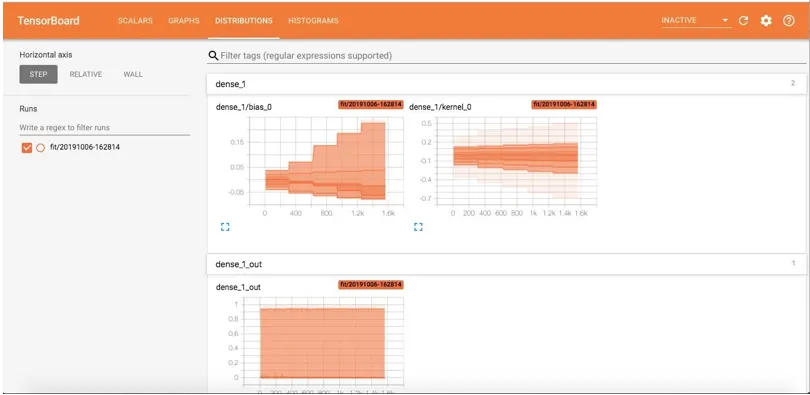
Op de pagina Distributie worden de statistische distributies weergegeven. De grafiek toont het gemiddelde en de standaardafwijkingen.
Voordelen
- Het TensorBoard helpt bij het visualiseren van het leren door samenvattingen van het model te schrijven, zoals scalars, histogrammen of afbeeldingen. Dit helpt op zijn beurt om de modelnauwkeurigheid te verbeteren en eenvoudig fouten te verwijderen.
- Diep leren verwerken is een black box-ding en tensorboard helpt bij het begrijpen van de verwerking die plaatsvindt in de black box met behulp van grafieken en histogrammen.
Conclusie - TensorBoard
TensorBoards biedt visualisatie voor het diepe verdienmodel dat is getraind en helpt hen deze te begrijpen. Het kan zowel met TensorFlow als Keras worden gebruikt. Het biedt voornamelijk visualisatie van het gedrag van scalars, metrieken met behulp van histogrammen en modelgrafiek als geheel.
Aanbevolen artikelen
Dit is een handleiding voor TensorBoard. Hier bespreken we de installatie en het gebruik van Tensboard met behulp van Keras-model met voordelen. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Inleiding tot Tensorflow
- Hoe TensorFlow te installeren
- Wat is TensorFlow?
- TensorFlow Speeltuin
- Tensorflow Basics