

Inleiding tot AWS EMR
AWS EMR biedt vele functionaliteiten die het ons gemakkelijker maken, enkele van de technologieën zijn:
- Amazon EC2
- Amazon RDS
- Amazon S3
- Amazon CloudFront
- Amazon Auto Scaling
- Amazon Lambda
- Amazon roodverschuiving
- Amazon Elastic MapReduce (EMR)
Een van de belangrijkste diensten van AWS EMR en waar we mee te maken krijgen is Amazon EMR.
EMR, ook wel Elastic Map Reduce genoemd, is een gemakkelijke en benaderbare manier om grotere hoeveelheden gegevens te verwerken. Stel je een scenario voor big data voor waar we een enorme hoeveelheid data hebben en waar we een aantal operaties over uitvoeren, bijvoorbeeld dat er een Map Reduce-taak wordt uitgevoerd, een van de belangrijkste problemen waarmee de Bigdata-applicatie te maken heeft, is het afstemmen van het programma, we vinden het vaak moeilijk om ons programma zo af te stemmen dat alle toegewezen middelen correct worden verbruikt. Vanwege deze bovenstaande afstemmingsfactor neemt de verwerkingstijd geleidelijk toe. Elastic Map Reduce the service by Amazon, is een webservice die een raamwerk biedt dat al deze noodzakelijke functies voor big data-verwerking op een kosteneffectieve, snelle en veilige manier beheert. Van het maken van clusters tot datadistributie over verschillende instanties, al deze dingen kunnen eenvoudig worden beheerd onder Amazon EMR. De services hier zijn on-demand betekent dat we de nummers kunnen beheren op basis van de gegevens die we hebben als deze kostenefficiënt en schaalbaar zijn.
Redenen voor het gebruik van AWS EMR
Dus waarom AMR gebruiken wat het beter maakt van anderen. We komen vaak een heel eenvoudig probleem tegen waarbij we niet in staat zijn om alle beschikbare bronnen over het cluster aan elke applicatie toe te wijzen, AMAZON EMR zorgt voor deze problemen en op basis van de gegevensgrootte en de vraag naar applicaties wijst het de benodigde resource toe. Omdat we elastisch van aard zijn, kunnen we het ook dienovereenkomstig wijzigen. EMR biedt enorme applicatie-ondersteuning, zij het Hadoop, Spark, HBase dat het eenvoudiger maakt voor gegevensverwerking. Het ondersteunt verschillende ETL-operaties snel en kosteneffectief. Het kan ook worden gebruikt voor MLIB in Spark. We kunnen daarin verschillende machine learning-algoritmen uitvoeren. Of het nu batchgegevens of realtime gegevensstreaming zijn EMR is in staat beide soorten gegevens te organiseren en te verwerken.
Werken van AWS EMR
Laten we nu dit diagram van het Amazon EMR-cluster bekijken en proberen te begrijpen hoe het eigenlijk werkt:
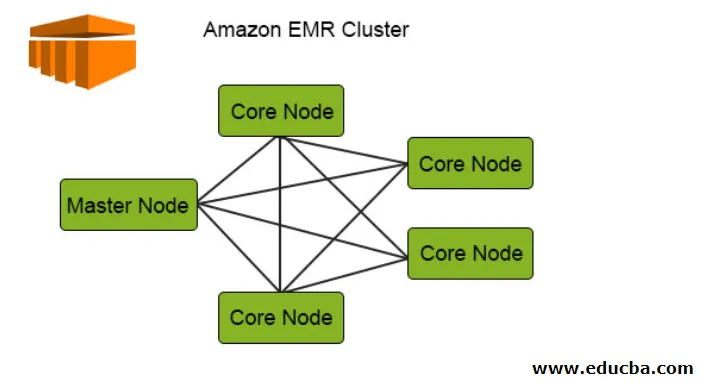
Het volgende diagram geeft de clusterdistributie van binnen EMR weer. Laten we dat eens nader bekijken:
1. De clusters zijn het centrale onderdeel in de Amazon EMR-architectuur. Ze zijn een verzameling EC2-instanties die knooppunten worden genoemd. Elk knooppunt heeft zijn specifieke rollen binnen het cluster genaamd Knooppunttype en op basis van hun rollen kunnen we ze in 3 soorten classificeren:
- Hoofdknooppunt
- Core Node
- Taakknooppunt
2. Het hoofdknooppunt, zoals de naam al aangeeft, is het hoofdverantwoordelijke dat verantwoordelijk is voor het beheer van het cluster, het uitvoeren van de componenten en de distributie van gegevens over de knooppunten voor verwerking. Het houdt alleen bij of alles goed wordt beheerd en goed werkt en werkt verder in geval van storing.
3. De Core Node is verantwoordelijk voor het uitvoeren van de taak en het opslaan van de gegevens in HDFS in het cluster. Alle verwerkingsonderdelen worden verwerkt door het kernknooppunt en de gegevens worden daarna naar de gewenste HDFS-locatie gebracht.
4. Het taakknooppunt dat optioneel is, heeft alleen de taak om de taak uit te voeren, dit slaat de gegevens niet op in HDFS.
5. Wanneer we na het indienen van een opdracht, hebben we verschillende methoden om te kiezen hoe de werken moeten worden voltooid. Van het beëindigen van het cluster na het voltooien van de taak tot een langlopend cluster met behulp van de EMR-console en CLI om stappen in te dienen, we hebben alle voorrechten om dit te doen.
6. We kunnen de opdracht rechtstreeks op de EMR uitvoeren door deze te verbinden met het hoofdknooppunt via de beschikbare interfaces en hulpmiddelen die opdrachten rechtstreeks op het cluster uitvoeren.
7. We kunnen onze gegevens ook in verschillende stappen uitvoeren met behulp van EMR, het enige dat we moeten doen is een of meer geordende stappen in het EMR-cluster indienen. De gegevens worden opgeslagen als een bestand en worden op een opeenvolgende manier verwerkt. Beginnend van "In afwachting van status tot Voltooid", kunnen we de verwerkingsstappen traceren en de fouten vinden die ook het gevolg zijn van 'Kan niet worden geannuleerd'. Al deze stappen kunnen hier eenvoudig naar worden herleid.
8. Zodra alle instanties zijn beëindigd, wordt de voltooide status voor het cluster bereikt.
Architectuur voor AWS EMR
De architectuur van EMR introduceert zichzelf vanaf het opslaggedeelte tot het toepassingsgedeelte.
- De allereerste laag wordt geleverd met de opslaglaag die verschillende bestandssystemen bevat die worden gebruikt met onze cluster. Of het nu gaat om HDFS naar EMRFS naar een lokaal bestandssysteem, deze worden allemaal gebruikt voor gegevensopslag over de hele applicatie. Caching van de tussenresultaten tijdens MapReduce-verwerking kan worden bereikt met behulp van deze technologieën die bij EMR worden geleverd.
- De tweede laag wordt geleverd met Resource Management voor het cluster, deze laag is verantwoordelijk voor resourcebeheer voor de clusters en knooppunten in de toepassing. Dit helpt eigenlijk als de managementtools die helpen om de gegevens gelijkmatig te verdelen over het cluster en correct te beheren. De standaard resource management tool die EMR gebruikt is YARN dat werd geïntroduceerd in Apache Hadoop 2.0. Het beheert centraal de bronnen voor meerdere gegevensverwerkingskaders. Het zorgt voor alle informatie die nodig is voor het goed draaiende cluster, van knooppuntgezondheid tot brondistributie met geheugenbeheer.
- De derde laag wordt geleverd met het raamwerk voor gegevensverwerking, deze laag is verantwoordelijk voor de analyse en de verwerking van gegevens. er zijn veel frameworks ondersteund door EMR die een belangrijke rol spelen bij parallelle en efficiënte gegevensverwerking. Een deel van het framework dat het ondersteunt en waarvan we ons bewust zijn, is APACHE HADOOP, SPARK, SPARK STREAMING, etc.
- De vierde laag wordt geleverd met de toepassing en programma's zoals HIVE, PIG, streaming-bibliotheek, ML-algoritmen die nuttig zijn voor het verwerken en beheren van grote gegevenssets.
Voordelen van AWS EMR
Laten we nu enkele voordelen van het gebruik van EMR bekijken:
- Hoge snelheid: aangezien alle bronnen correct worden gebruikt, is de verwerkingstijd voor de query relatief sneller dan de andere gegevensverwerkingsprogramma's die een veel duidelijk beeld hebben.
- Bulk gegevensverwerking: hoe groter de datagrootte EMR biedt de mogelijkheid om een grote hoeveelheid gegevens in voldoende tijd te verwerken.
- Minimaal gegevensverlies: aangezien gegevens over het cluster worden verspreid en parallel via het netwerk worden verwerkt, is er een minimale kans op gegevensverlies en is de nauwkeurigheid van de verwerkte gegevens beter.
- Kostenbesparend: omdat het kostenbesparend is, is het goedkoper dan elk ander alternatief dat het sterk maakt ten opzichte van het gebruik in de branche. Omdat de prijzen lager zijn, kunnen we grote hoeveelheden gegevens verwerken en deze binnen het budget verwerken.
- AWS Integrated: Het is geïntegreerd met alle diensten van AWS die gemakkelijk beschikbaar zijn onder een dak, zodat de beveiliging, opslag, netwerken alles op één plek is geïntegreerd.
- Beveiliging: het wordt geleverd met een verbazingwekkende beveiligingsgroep om het inkomende en uitgaande verkeer te beheren, en het gebruik van IAM Roles maakt het veiliger omdat het verschillende machtigingen biedt die gegevens beveiligen.
- Monitoring en implementatie: we hebben goede monitoringtools voor alle applicaties die over EMR-clusters draaien, waardoor het transparant en gemakkelijk te analyseren is en het wordt geleverd met een automatische implementatiefunctie waarbij de applicatie automatisch wordt geconfigureerd en geïmplementeerd.
Er zijn veel meer voordelen aan het hebben van EMR als een betere keuze voor andere clusterberekeningsmethoden.
AWS EMR-prijzen
EMR komt met een verbazingwekkende prijslijst die ontwikkelaars of de markt er naartoe trekt. Omdat het wordt geleverd met een on-demand prijsfunctie, kunnen we het iets meer dan een uurbasis en aantal knooppunten in ons cluster gebruiken. We kunnen een tarief per seconde betalen voor elke seconde die we gebruiken met minimaal één minuut. We kunnen ook onze exemplaren kiezen om te gebruiken als gereserveerde exemplaren of Spot-exemplaren, waarbij de spot veel kostenbesparend is.
We kunnen de totale factuur berekenen via een eenvoudige maandelijkse calculator via de onderstaande link: -
https://calculator.s3.amazonaws.com/index.html#s=EMR
Voor meer informatie over de exacte prijsdetails kunt u het onderstaande document van Amazon raadplegen: -
https://aws.amazon.com/emr/pricing/
Conclusie
Uit het bovenstaande artikel hebben we gezien hoe EMR kan worden gebruikt voor de eerlijke verwerking van big data waarbij alle bronnen op conventionele wijze worden gebruikt.
Het hebben van EMR lost ons basisprobleem van gegevensverwerking op en verkort veel de verwerkingstijd met een groot aantal, omdat het kosteneffectief is, is het gemakkelijk en handig in gebruik.
Aanbevolen artikel
Dit is een gids voor AWS EMR geweest. Hier bespreken we een inleiding tot AWS EMR langs de werking en de architectuur, evenals de voordelen. U kunt ook onze andere voorgestelde artikelen doornemen voor meer informatie -
- AWS-alternatieven
- AWS-opdrachten
- AWS Services
- Vragen tijdens solliciteren bij AWS
- AWS-opslagdiensten
- Top 7 concurrenten van AWS
- Lijst met functies van Amazon Web Services