
Inleiding tot grafieken in R
Een grafiek is een hulpmiddel dat een aanzienlijk verschil maakt voor de analyse. Grafieken in Zeldzaam belangrijk omdat ze helpen om de resultaten op de meest interactieve manier te presenteren. R, als een statistisch programmeerpakket, biedt uitgebreide opties om verschillende grafieken te genereren.
Sommige grafieken in R zijn beschikbaar in de basisinstallatie, maar andere kunnen worden gebruikt door vereiste pakketten te installeren. Het unieke kenmerk van grafieken in R is dat ze ingewikkelde statistische bevindingen verklaren door middel van visualisaties. Dus in wezen is dit hetzelfde als een stap verder gaan dan de traditionele manier om de gegevens te visualiseren. R biedt dus een out-of-the-box benadering voor analyse van de aandrijving.
Soorten grafieken in R
Een verscheidenheid aan grafieken is beschikbaar in R, en het gebruik wordt uitsluitend bepaald door de context. Verkennende analyse vereist echter het gebruik van bepaalde grafieken in R, die moeten worden gebruikt voor het analyseren van gegevens. We zullen nu enkele van dergelijke belangrijke grafieken in R. bekijken
Voor de demonstratie van verschillende grafieken gaan we de "bomen" -dataset gebruiken die beschikbaar is in de basisinstallatie. Meer details over de dataset kunnen worden ontdekt met behulp van? bomen commando in R.
1. Histogram
Een histogram is een grafisch hulpmiddel dat op een enkele variabele werkt. Talrijke variabele waarden zijn gegroepeerd in opslaglocaties en een aantal waarden worden genoemd als de frequentie wordt berekend. Deze berekening wordt vervolgens gebruikt om frequentiebalken in de respectieve bonen te plotten. De hoogte van een balk wordt weergegeven door frequentie.
In R kunnen we de functie hist () gebruiken, zoals hieronder wordt getoond, om het histogram te genereren. Een eenvoudig histogram van boomhoogtes wordt hieronder getoond.
Code:
hist(trees$Height, breaks = 10, col = "orange", main = "Histogram of Tree heights", xlab = "Height Bin")
Output:

Om de trend van frequentie te begrijpen, kunnen we een dichtheidsgrafiek toevoegen over het bovenstaande histogram. Dit biedt meer inzichten in gegevensdistributie, scheefheid, kurtosis, enz. De volgende code doet dit en de uitvoer wordt weergegeven volgens de code.
Code:
hist(trees$Height, breaks = 10, col = "orange",
+ main = "Histogram of Tree heights with Kernal Denisty plot",
+ xlab = "Height Bin", prob = TRUE)
Output:

2. Scatterplot
Deze plot is een eenvoudig grafiektype, maar zeer cruciaal met een enorme betekenis. De grafiek geeft het idee van een verband tussen variabelen en is een handig hulpmiddel in een verkennende analyse.
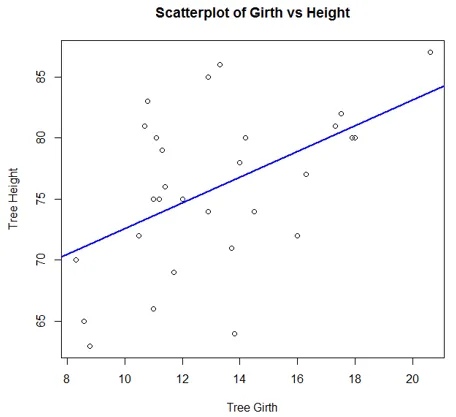
De volgende code genereert een eenvoudig Scatterplot-diagram. We hebben er een trendlijn aan toegevoegd, om de trend te begrijpen, de gegevens vertegenwoordigen.
Code:
attach(trees)
plot(Girth, Height, main = "Scatterplot of Girth vs Height", xlab = "Tree Girth", ylab = "Tree Height")
abline(lm(Height ~ Girth), col = "blue", lwd = 2)
Output:
De grafiek met de volgende code laat zien dat er een goede correlatie bestaat tussen de boomomtrek en het boomvolume.
Code:
plot(Girth, Volume, main = "Scatterplot of Girth vs Volume", xlab = "Tree Girth", ylab = "Tree Volume")
abline(lm(Volume ~ Girth), col = "blue", lwd = 2)
Output:

Scatterplot-matrices
R stelt ons in staat om meerdere variabelen tegelijkertijd te vergelijken omdat het spreidingsmatrices gebruikt. Het implementeren van de visualisatie is vrij eenvoudig en kan worden bereikt met behulp van de paren () -functie zoals hieronder getoond.
Code:
pairs(trees, main = "Scatterplot matrix for trees dataset")
Output:

Scatterplot3d
Ze maken visualisatie mogelijk in drie dimensies die kunnen helpen de relatie tussen meerdere variabelen te begrijpen. Dus, om scatterplots beschikbaar te maken in 3d, moet eerst scatterplot3d worden geïnstalleerd. De volgende code genereert dus een 3D-grafiek zoals weergegeven onder de code.
Code:
library(scatterplot3d)
attach(trees)
scatterplot3d(Girth, Height, Volume, main = "3D Scatterplot of trees dataset")
Output:
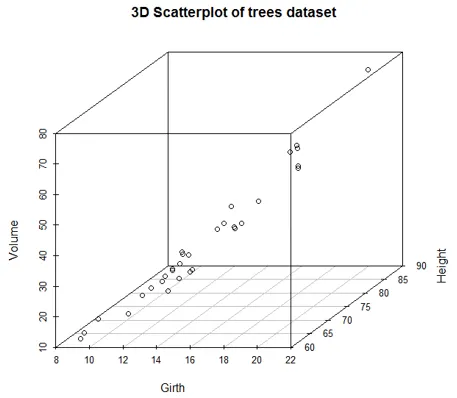
We kunnen druppellijnen en kleuren toevoegen met behulp van de onderstaande code. Nu kunnen we gemakkelijk onderscheid maken tussen verschillende variabelen.
Code:
scatterplot3d(Girth, Height, Volume, pch = 20, highlight.3d = TRUE,
+ type = "h", main = "3D Scatterplot of trees dataset")
Output:

3. Boxplot
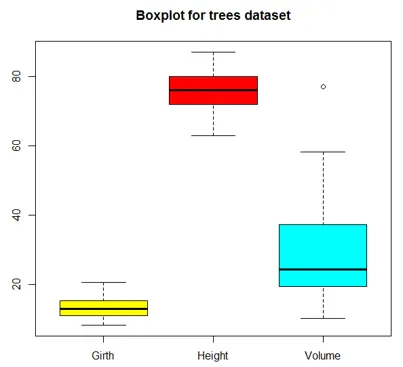
Boxplot is een manier om gegevens te visualiseren door middel van dozen en snorharen. Ten eerste worden variabele waarden gesorteerd in oplopende volgorde en vervolgens worden de gegevens in kwartalen verdeeld.
Het vak in de plot is de middelste 50% van de gegevens, bekend als IQR. De zwarte lijn in het vak geeft de mediaan aan.
Code:
boxplot(trees, col = c("yellow", "red", "cyan"), main = "Boxplot for trees dataset")
Output:
Een variant van de boxplot, met inkepingen, is zoals hieronder weergegeven.
Code:
boxplot(trees, col = "orange", notch = TRUE, main = "Boxplot for trees dataset")
Output:

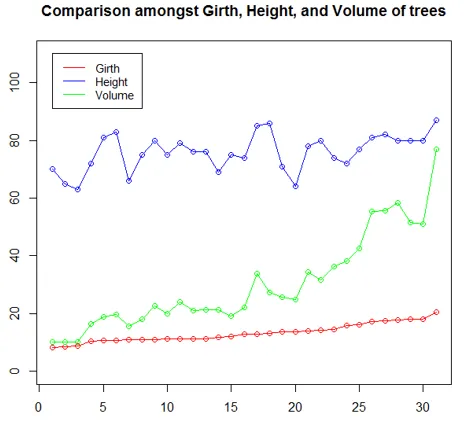
4. Lijndiagram
Lijndiagrammen zijn handig bij het vergelijken van meerdere variabelen. Ze helpen ons de relatie tussen meerdere variabelen in één plot. In de volgende afbeelding proberen we de trend van drie boomstructuren te begrijpen. Dus, zoals in de onderstaande code, in eerste instantie, en het lijndiagram voor Omtrek wordt uitgezet met behulp van de plot () functie. Vervolgens worden lijndiagrammen voor Hoogte en Volume op dezelfde plot uitgezet met behulp van de functie lines ().
De parameter "ylim" in de functie plot () is om alle drie de lijndiagrammen correct te kunnen gebruiken. Het hebben van een legende is hier belangrijk, omdat het helpt te begrijpen welke regel welke variabele vertegenwoordigt. In de legenda betekent de parameter "lty = 1: 1" dat we hetzelfde lijntype hebben voor alle variabelen en "cex" staat voor de grootte van de punten.
Code:
plot(Girth, type = "o", col = "red", ylab = "", ylim = c(0, 110),
+ main = "Comparison amongst Girth, Height, and Volume of trees")
lines(Height, type = "o", col = "blue")
lines(Volume, type = "o", col = "green")
legend(1, 110, legend = c("Girth", "Height", "Volume"),
+ col = c("red", "blue", "green"), lty = 1:1, cex = 0.9)
Output:
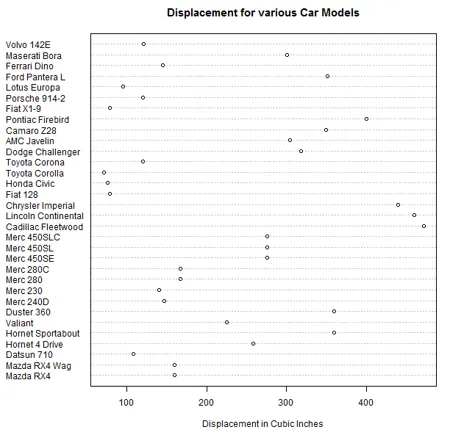
5. Puntplot
Deze visualisatietool is handig als we meerdere categorieën willen vergelijken met een bepaalde maat. Voor de onderstaande illustratie is de dataset mtcars gebruikt. De dotchart () functie plot de verplaatsing voor verschillende automodellen zoals hieronder.
Code:
attach(mtcars)
dotchart(disp, labels = row.names(mtcars), cex = 0.75,
+ main = "Displacement for various Car Models", xlab = "Displacement in Cubic Inches")
Output:
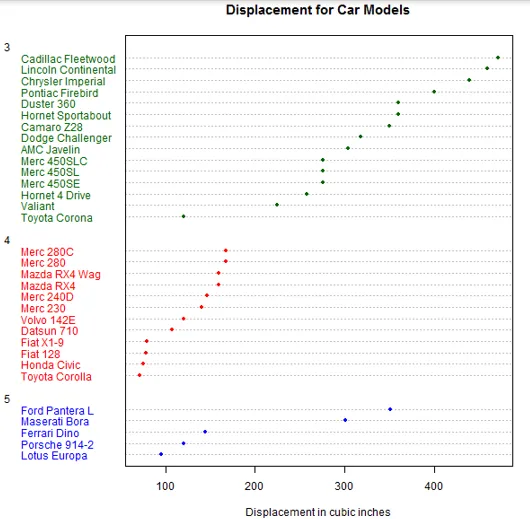
Dus nu zullen we de gegevensset sorteren op verplaatsingswaarden en ze vervolgens op verschillende tandwielen plotten met de functie dotchart ().
Code:
m <- mtcars(order(mtcars$disp), ) m$gear <- factor(m$gear)
m$color(m$gear == 3) <- "darkgreen"
m$color(m$gear == 4) <- "red"
m$color(m$gear == 5) <- "blue"
dotchart(m$disp, labels = row.names(m), groups = m$gear, color = m$color, cex = 0.75, pch = 20,
+ main = "Displacement for Car Models", xlab = "Displacement in cubic inches")
Output:
Conclusie
Analytics in echte zin wordt alleen gebruikt via visualisaties. R, als statistisch hulpmiddel, biedt sterke visualisatiemogelijkheden. Dus de vele opties die aan grafieken zijn gekoppeld, zijn wat hen bijzonder maakt. Elk diagram heeft zijn eigen toepassing en het diagram moet worden bestudeerd voordat het op een probleem wordt toegepast.
Aanbevolen artikelen
Dit is een gids voor grafieken in R. Hier bespreken we de introductie en typen grafieken in R zoals histogram, spreidingsdiagram, boxplot en nog veel meer samen met voorbeelden en implementatie. U kunt ook de volgende artikelen bekijken voor meer informatie -
- R Gegevenstypen
- R-pakketten
- Inleiding tot Matlab
- Grafieken versus grafieken