
Inleiding tot Python-sets
In dit artikel gaan we sets in Python bespreken. Python is een zeer veelzijdige taal en wordt snel een van de meest gebruikte talen op het gebied van data science, omdat het gemakkelijk te lezen en te schrijven is en ook gebaseerd is op het OOPs-concept. Set is een ongeordende verzameling die wordt weergegeven door accolades in Python. Hier geordend betekent dat u niet zeker weet in welke volgorde de items zullen verschijnen. Set verschilt van een lijst waarin alleen unieke elementen kunnen worden opgeslagen en geen dubbele elementen.
Syntaxis:
Zoals in het algemeen python, is de syntaxis over het algemeen eenvoudig. De syntaxis voor python set is als volgt:
firstset = ("Johnny", "Nilanjan", "Rupa")
print(firstset)
Hier is de eerste set de variabelenaam waarin de set is opgeslagen. De accolades () staan voor set en omdat we tekenreekswaarden toevoegen, zijn dubbele / enkele omgekeerde komma's vereist. De waarden in de set worden gescheiden door komma's. Nu, omdat we de syntaxis van de set hebben gezien met een voorbeeld in Python. Laten we nu de verschillende methoden bespreken die in Python-sets worden gebruikt.
Verschillende methoden in Python-sets
Laten we de verschillende methoden doornemen die aanwezig zijn als ingebouwde Python voor sets.
1. add (): zoals de naam al suggereert, werd het gebruikt om een nieuw element aan de set toe te voegen. Dit betekent dat u het aantal elementen in de set met één verhoogt. Hier is een zeer belangrijke kennis over set die in gedachten moet worden gehouden dat het element alleen wordt toegevoegd als het nog niet aanwezig is in de setactiva, geen dubbele elementen gebruiken. De methode add geeft ook geen waarde terug. Laten we een voorbeeld doen.
Code:
firstset = ("Johnny", "Nilanjan", "Rupa")
firstset.add("Sepoy")
print("The new word is", firstset)
#to check duplicate property of Set
firstset.add("Sepoy")
print("The new word is", firstset)
Nu is de onderstaande schermafbeelding de uitvoer van de code wanneer deze op Jupyter Notebook wordt uitgevoerd.
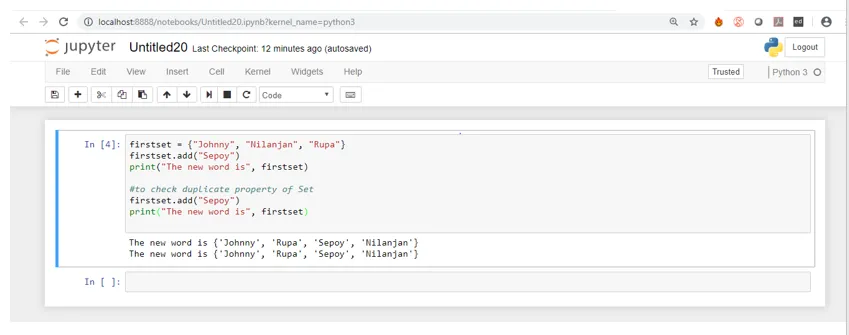
Als u de uitvoer de eerste keer ziet, wanneer de functie add () wordt gebruikt, wordt het element toegevoegd en wordt de grootte van de set met één verhoogd, zoals wordt weergegeven wanneer we de eerste afdrukopdracht uitvoeren, maar de tweede keer wanneer we de methode add () gebruiken om hetzelfde element (sepoy) toe te voegen als de eerste keer, zien we bij het uitvoeren van de printopdracht dezelfde elementen worden weergegeven zonder toename van de grootte van de set, wat betekent dat de set geen dubbele waarden aanneemt.
2. clear (): zoals de naam al doet vermoeden, worden alle elementen uit de set verwijderd. Het heeft geen parameter nodig en retourneert geen waarde. We hoeven alleen maar de duidelijke methode aan te roepen en uit te voeren. Laten we een voorbeeld bekijken:
Code:
firstset = ("Johnny", "Nilanjan", "Rupa")
print("Before clear", firstset)
firstset.clear()
print("After clear", firstset)
Laten we de uitvoer bekijken na het uitvoeren van dezelfde code in het jupyter-notebook.
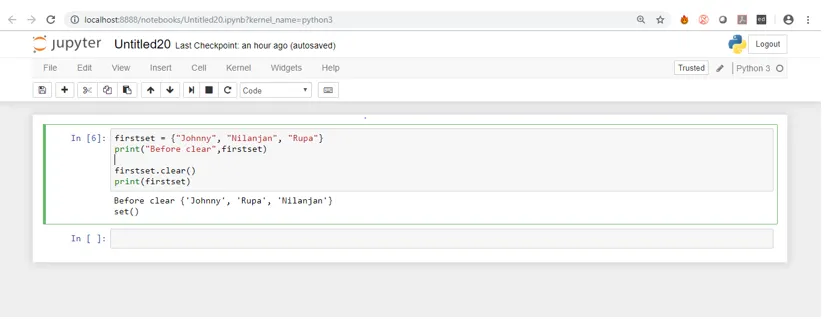
De bovenstaande schermafbeelding laat dus zien dat voordat we de methode clear hadden uitgevoerd, de lijst met elementen was afgedrukt en toen we de methode clear () uitvoerden, werden alle elementen verwijderd en hadden we een lege set.
3. copy (): deze methode wordt gebruikt om een ondiepe kopie van een set te maken. De term ondiepe kopie betekent dat als u nieuwe elementen aan de set toevoegt of elementen uit de set verwijdert, de originele set niet verandert. Het is het belangrijkste voordeel van het gebruik van de kopieerfunctie. We zullen een voorbeeld zien om het concept van de ondiepe kopie te begrijpen.
Code:
originalset = ("Johnny", "Nilanjan", "Rupa")
copiedset = originalset.copy()
print("originalset:: ", originalset)
print("copiedset:: ", copiedset)
# modify the copiedset to check shallow copy feature
copiedset.add("Rocky")
print("originalset:: ", originalset)
print("copiedset:: ", copiedset)
Laten we nu de uitvoer controleren in Jupyter Notebook.
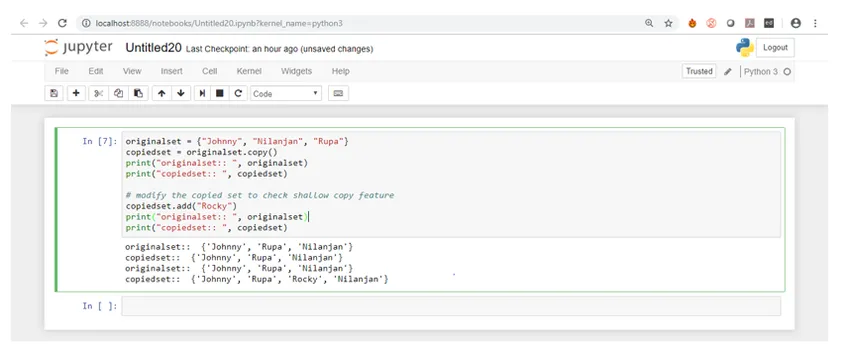
Zoals je kunt zien, toen we de functie om een nieuw element aan de gekopieerde set toe te voegen, toevoegden, werd de gekopieerde set gewijzigd, maar de oorspronkelijke set bleef nog steeds hetzelfde.
4. verschil (): dit is een zeer belangrijke functie-inzet. Deze functie retourneert een set die het verschil is tussen twee sets. Houd er rekening mee dat verschil hier geen aftrekking betekent, omdat het hier het verschil is tussen het aantal elementen in twee sets en niet de waarden van elementen. Hier betekent bijvoorbeeld set A1 - set A2 dat het een set retourneert met elementen die aanwezig zijn in A1 maar niet in A2 en vice versa in het geval van set A2 - set A1 (aanwezig in A2 maar niet in A1). Hetzelfde zal hieronder worden uitgelegd aan de hand van een voorbeeld.
Code:
A1= (24, 35, 34, 45)
A2= (24, 56, 35, 46)
print(A1.difference(A2))
print(A2.difference(A1))
Laten we nu eens kijken naar de uitvoer in de onderstaande schermafbeelding.
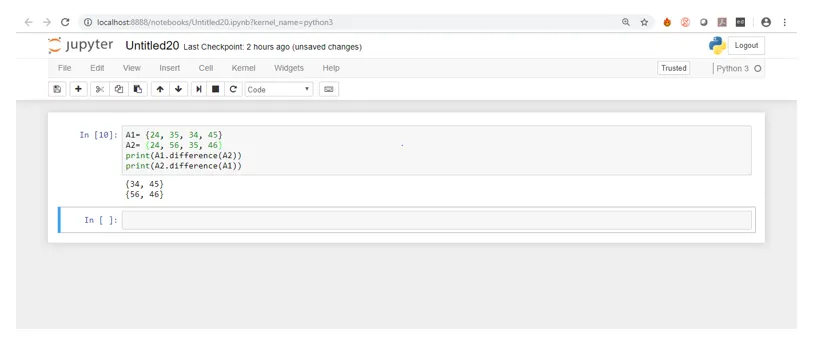
Nu, in de bovenstaande screenshot als je goed kijkt, is er een verschil tussen de eerste en tweede resultaten. In het eerste resultaat worden de elementen getoond die in A staan, maar niet in B, terwijl in het tweede resultaat elementen worden getoond die aanwezig zijn in B maar niet in A.
5. intersection (): het is heel anders dan de vorige ingebouwde methode. In dit geval worden alleen de elementen die gemeenschappelijk zijn in beide sets of in meerdere sets (in het geval van meer dan twee sets) geretourneerd in de vorm van een set. Laten we nu een voorbeeld nemen.
Code:
A1= (24, 35, 34, 45)
A2= (24, 56, 35, 46)
A3= (24, 35, 47, 56)
print(A1.intersection(A2, A3))
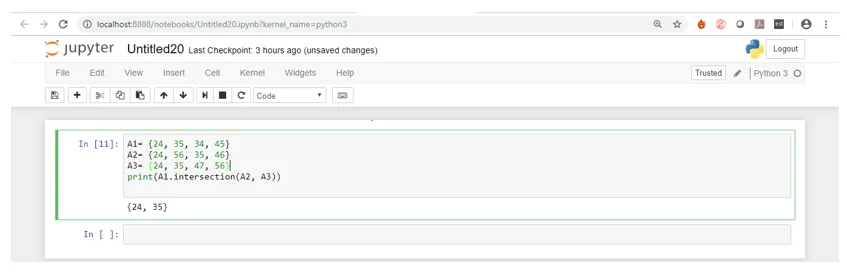
Zoals je kunt zien, hadden de drie sets slechts twee elementen gemeen, die 24 en 35 zijn. Vandaar dat bij het uitvoeren van de code een set met slechts 24 en 35 werd geretourneerd.
6. union (): het is een functie die een set retourneert met alle elementen van de oorspronkelijke set en ook de opgegeven sets. Omdat het een set retourneert, hebben alle items slechts één uiterlijk. Als twee sets dezelfde waarde bevatten, verschijnt het item slechts één keer.
Code:
A1= (24, 35, 34, 45)
A2= (24, 56, 35, 46)
A3= (24, 35, 47, 56)
print(A1.union(A2, A3))
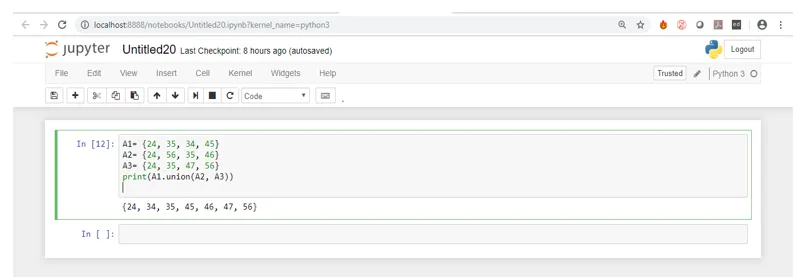
In de bovenstaande schermafbeelding ziet u de uitvoer van de code bij uitvoering. Als u goed kijkt, vindt u alle waarden van A1 en alle unieke waarden van de andere twee sets.
7. issubset (): deze functie retourneert Booleaanse waarden die waar of onwaar zijn. Als alle elementen van de ene set aanwezig zijn in een andere set, retourneert deze true, anders false. We zullen een voorbeeld van hetzelfde zien om beter te begrijpen.
Code:
A1 =(3, 6, 8)
A2 =(45, 87, 3, 67, 6, 8)
print(A1.issubset(A2))
print(A2.issubset(A1))
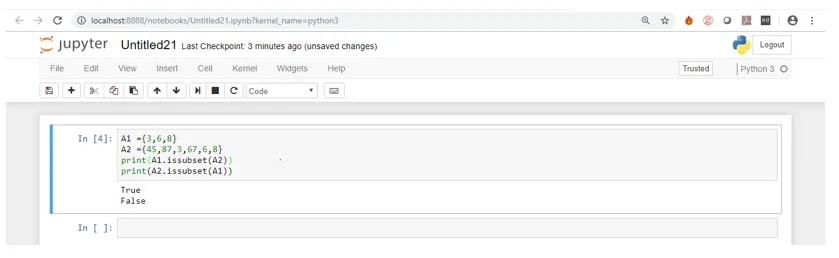
Als u het bovenstaande screenshot ziet, kunt u zien dat A2 alle elementen van A1 heeft, maar dat A1 niet alle elementen van A2 heeft. Daarom is A1 een subset van A2.
8. issuperset (): deze functie retourneert Booleaanse waarden die waar of onwaar zijn. Als een set alle elementen van een andere set bevat, kan die set een superset van de andere set worden genoemd en de waarde die door de functie wordt geretourneerd is waar anders onwaar. We zullen een voorbeeld van hetzelfde zien om beter te begrijpen.
Code:
A1 = (3, 6, 8)
A2 = (45, 87, 3, 67, 6, 8)
print(A1.issuperset(A2))
print(A2.issuperset(A1))
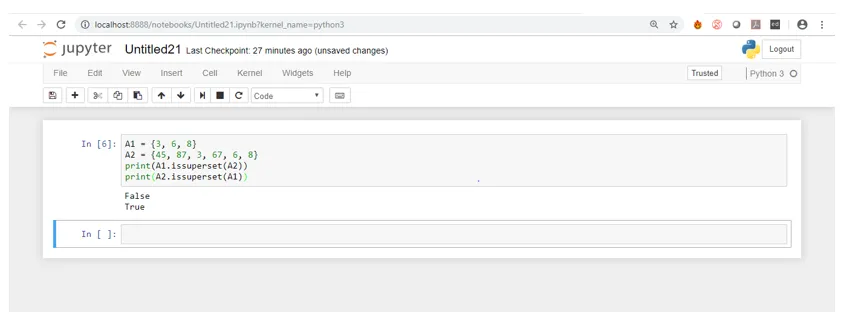
Zoals je in de output screenshot kunt zien, bevat de tweede set A2 alle elementen van set A1. Daarom is het een superset van A1. Hetzelfde geldt niet voor A1 met betrekking tot A2, dus retourneert het onwaar.
9. remove (): deze functie wordt gebruikt om elementen uit de set te verwijderen. De te verwijderen elementen worden als argumenten doorgegeven. De functie verwijdert het element als het in de set aanwezig is, anders wordt een fout geretourneerd. We zullen een voorbeeld uitvoeren om dit te controleren.
Code:
firstset = ("Johnny", "Nilanjan", "Rupa")
firstset.remove("Nilanjan")
print(firstset)
# to check error
firstset.remove("Rocky")
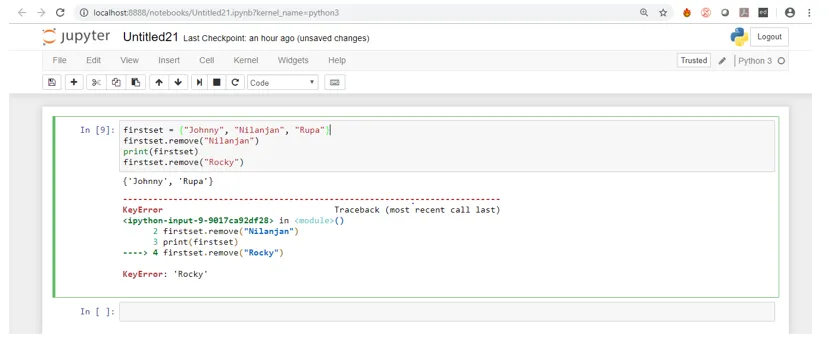
Als u bovenstaande schermafbeelding ziet wanneer de code wordt uitgevoerd, wordt het element "Nilanjan" verwijderd zoals het in de set aanwezig was, maar wanneer we proberen "Rocky" te verwijderen, geeft dit een foutmelding omdat "Rocky" niet aanwezig is in de set.
10. discard (): deze ingebouwde methode wordt ook gebruikt om elementen uit de set te verwijderen, maar deze verschilt van de verwijderingsmethode die we eerder hebben besproken. Als het element aanwezig is in de set, verwijdert het het element, maar als het aanwezig is, geeft het geen fout en drukt het normaal gesproken gewoon de set af. We zullen hiervan een voorbeeld zien
Code:
firstset = ("Johnny", "Nilanjan", "Rupa")
firstset.discard("Nilanjan")
print(firstset)
firstset.discard("Rocky")
print(firstset)
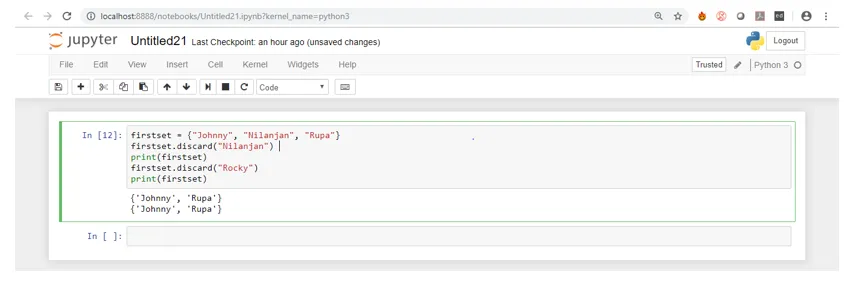
Als we het bovenstaande screenshot zien, kunnen we zien dat hoewel "Rocky" niet aanwezig is in de set, er geen fout wordt weergegeven in tegenstelling tot de verwijderingsmethode waarbij een fout werd weergegeven.
Conclusie
We hebben in dit artikel het concept van sets in python besproken en de verschillende functies die in sets kunnen worden gebruikt of toegepast. Sets, zoals besproken, zijn belangrijk in python en de ingebouwde methoden worden gebruikt om de sets te manipuleren en ook om bewerkingen met sets uit te voeren.
Aanbevolen artikelen
Dit is een handleiding voor de Python-sets. Hier bespreken we de introductie van de Python-sets, verschillende methoden in Python-sets samen met Syntax. U kunt ook onze andere voorgestelde artikelen doornemen voor meer informatie–
- String Array in Python
- Wat is Python
- NLP in Python
- Is Python een scripttaal?
- Python-functies
- String Array in JavaScript
- Complete gids voor strijkersmatrix in C