
Verschil tussen HBase en Cassandra
HBase is een database die het door Hadoop gedistribueerde bestandssysteem gebruikt voor de opslag ervan. HBase is een belangrijk onderdeel van HDFS en draait bovenop de Hadoop-cluster. HBase is geen traditionele relationele database, het vereist een andere datamodellering. Cassandra werkt op het datareplicatiemodel, dus in het geval van het niet beschikbaar zijn van een knooppunt, zal er geen dataverlies zijn. Cassandra is een gedistribueerde database betekent dat gegevens toegankelijk zijn voor een client vanuit elk cluster en vanuit elk knooppunt
1.1) Cassandra:
Het is gestart door Facebook omdat het altijd voldoet aan de applicatie-eisen. Cassandra is gestart in 2005 en beschikbaar gesteld voor het publiek in 2008. Cassandra is ontwikkeld voor altijd beschikbare applicaties zoals sociale netwerken zoals Facebook en Twitter.
Cassandra werkt op de "always-on" -architectuur en heeft een Active-Active node-model, dus er is geen SPoF (Single point of failure). CQL (Cassandra Query Language) is de querytaal van Cassandra maar heeft dezelfde syntaxis als SQL. Het ondersteunt alle belangrijke besturingssystemen zoals Linux, Unix, OSX en Windows.
Altijd aan:
Cassandra is een database met een distributiemodel en alle knooppunten zijn hetzelfde binnen het cluster. Gegevens worden gerepliceerd op configureerbare knooppunten, dus in het geval van een storing nee. van knooppunten leidt niet tot het verlies van gegevens.
(Altijd op model)
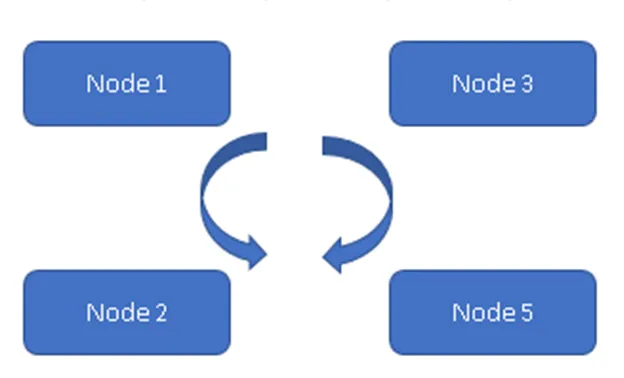
In figuur 1 zijn alle vier knooppunten synchroon met elkaar en repliceren de gegevens binnen het cluster. Allen werken op Active-Active Model, dus in het geval van een knooppuntfout leidt dit niet tot gegevensverlies. Een client kan de gegevens van de rest van de beschikbare knooppunt / knooppunten lezen.
1.2) HBase:
HBase is een op NoSQL gebaseerde database en is ontworpen voor het verwerken van query's in grote tabellen met miljarden rijen met miljoenen kolommen en loopt over een cluster van standaard / normale hardware. Het biedt u realtime query-mogelijkheden met de snelheid van een " sleutel / waardeopslag " .
HBase is eigenlijk gebaseerd op / werkt op een vierdimensionaal datamodel.
- Rij-ID / rijsleutel
- Kolomfamilie.
- Sleutel / waarde-paren.
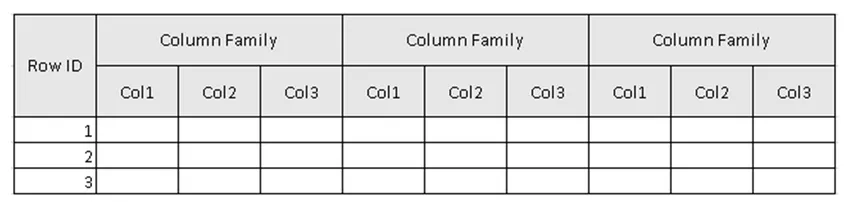
(Afbeelding 2, voorbeeldschema van de tabel in HBase.)
In figuur 2 is Tabel de verzameling Kolomfamilie en Kolomfamilie is de verzameling Kolommen. Kolommen zijn de verzameling sleutel / waarde-paren
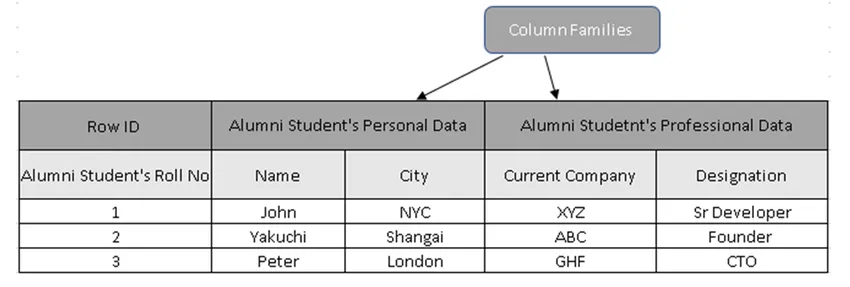
(Afbeelding 3, voorbeeldtabel in HBase)
In figuur 3 zijn kolomfamilies de verzameling gegevens van Alumni-studenten en bevatten rij-ID's (rijcodes) het studentennummer.
In feite bevatten rijtoetsen de unieke waarde ten opzichte van de gegevens van de kolomfamilie. Door de rijtoets te gebruiken, kan men alle details extraheren, redenen waarom kolomgeoriënteerde databases veel sneller zijn dan traditionele databases.
Apache HBase kan worden gebruikt voor willekeurige lees- / schrijftoegang en biedt foutondersteuning. Het ondersteunt ook replicatie en werk aan het distributiedatabase-model.
Head to Head-vergelijking van HBase versus Cassandra (infographics)
Hieronder staat het top 9 verschil tussen HBase en Cassandra
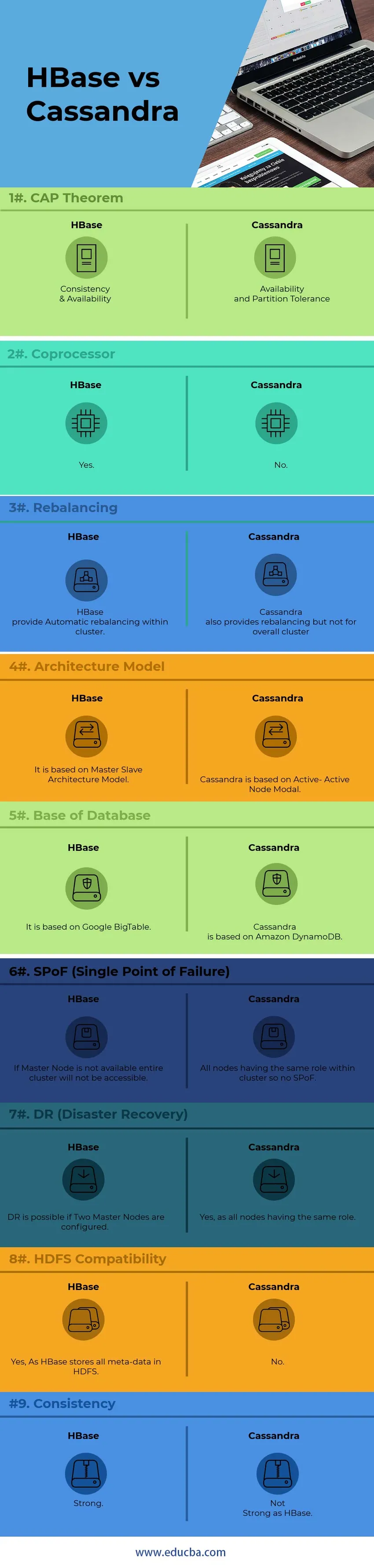 Belangrijkste verschillen tussen HBase versus Cassandra
Belangrijkste verschillen tussen HBase versus Cassandra
Hieronder staan de lijst met punten, beschrijf de belangrijkste verschillen tussen HBase en Cassandra:
1) Voor interne knooppuntcommunicatie gebruikt Cassandra GOSSIP Protocol terwijl HBase is gebaseerd op Zookeeper. Diensten van GOSSIP Protocol zijn geïntegreerd met Cassandra overkant Zookeeper is een volledig afzonderlijke distributietoepassing.
2) In Cassandra-architectuur werken alle knooppunten als Active Node, terwijl HBase architect het Master-Slave Node-model volgt. In het Active-Active Node-model is er geen SPoF (Single Point of Failure). In HBase is het hele cluster niet toegankelijk als het hoofdknooppunt omlaag gaat.
3) HBase ondersteunt binair boomzoekmodel, terwijl Cassandra geen B-boommodel ondersteunt. Zonder B-Tree kun je in april geen gebruikerskolommen zoeken voor iedereen met een jubileum, terwijl je kunt zoeken naar iedereen die in Beijing woont met een Verjaardag in april.
4) HBase, ondersteunt C, C ++, Java, Python, Scala-scripttalen, terwijl Cassandra ook JavaScript & Ruby ondersteunt.
5) HBase heeft één functie die coprocessors wordt genoemd, terwijl Cassandra die functie vanaf nu niet heeft. Coprocessors bieden een bibliotheek en runtime-omgeving voor het uitvoeren van gebruikerscode binnen de HBase-regioserver en masterprocessen.
6) HBase is ontworpen om het datawarehouse te ondersteunen, terwijl Cassandra perfect is voor applicaties die altijd actief zijn, zoals web- en mobiele applicaties.
7) HBase-querytaal is een aangepaste taal die moet worden geleerd, terwijl Cassandra zijn eigen ontwikkelde CQL (Cassandra Query Language) gebruikt, die SQL-achtige taal is
8) Het beheren van Cassandra is veel eenvoudiger dan HBase. In Cassandra moet een enkel Java-proces per knoop worden uitgevoerd, terwijl voor HBase, volledig operationele HDFS, verschillende HBase-processen en een Zookeeper-systeem vereist zijn.
9) HBase eindigt wel met controlesommen en automatisch opnieuw in evenwicht brengen, terwijl Cassandra geen ondersteuning biedt voor het opnieuw in evenwicht brengen van het cluster in het algemeen.
10) Cassandra werkt op basis van “ CAP-stelling” op AP-model, terwijl HBase CP-model is.
CAP-stelling
Deze stelling wordt gebruikt voor gedistribueerde systemen. C staat voor Consistentie, A betekent Beschikbaarheid & P is Partitietolerantie. CAP-theorie hieronder uitgelegd:
C (Consistentie): Consistentie betekent dat als iemand een waarde naar een database heeft geschreven, anderen onmiddellijk dezelfde waarde kunnen lezen.
A (Beschikbaarheid) : Beschikbaarheid betekent dat als sommige knooppunten niet beschikbaar zijn in uw cluster (knooppunten zijn niet beschikbaar / niet in het cluster aanwezig vanwege een probleem) geen invloed hebben op het hele cluster en dat Gedistribueerd systeem / database beschikbaar is voor toegang tot de gegevens. De Cluster zal toegankelijk zijn voor alle soorten taken.
P (Partitietolerantie): Partitietolerantie betekent dat als één datacenter nog steeds niet actief is, dit geen invloed heeft op de gegevens op de knooppunten en alle gegevens op elk gewenst moment toegankelijk moeten zijn. Dit betekent dat partitietolerantie een betere replicatie van gegevens naar andere datacenters en binnen de clusteromgeving mogelijk maakt.
HBase versus Cassandra vergelijkingstabel
| punten | HBase | Cassandra |
| CAP-stelling | Consistentie en beschikbaarheid | Beschikbaarheid en partitietolerantie |
| coprocessor | Ja | Nee |
| Rebalancing | HBase biedt automatische herbalancering binnen een cluster. | Cassandra biedt ook herbalancering, maar niet voor het totale cluster |
| Architectuurmodel | Het is gebaseerd op Master-Slave Architecture Model | Cassandra is gebaseerd op Active-Active Node Modal |
| Basis van database | Het is gebaseerd op Google BigTable | Cassandra is gebaseerd op Amazon DynamoDB |
| SPoF (Single Point of Failure) | Als Master Node niet beschikbaar is, is het hele cluster niet toegankelijk | Alle knooppunten hebben dezelfde rol binnen het cluster dus geen SPoF |
| DR (noodherstel) | DR is mogelijk als er twee hoofdknooppunten zijn geconfigureerd. | Ja, omdat alle knooppunten dezelfde rol hebben |
| HDFS-compatibiliteit | Ja, omdat HBase alle metagegevens opslaat in HDFS | Nee |
| Consistentie | Sterk | Niet sterk als HBase |
Conclusie - HBase versus Cassandra
Facebook en een andere sociale netwerkkant geven de voorkeur aan HBase (eerder gebruikten beiden Cassandra, zie Facebook-post) vanwege de beschikbaarheid van de andere kant van het bankdomein zoekt naar beveiliging voor elke financiële transactie, zodat ze Cassandra zouden selecteren boven HBase.
Cassandra Key-kenmerken omvatten hoge beschikbaarheid, minimale administratie en geen SPoF (Single Point of Failure) andere kant HBase is goed voor sneller lezen en schrijven van de gegevens met lineaire schaalbaarheid.
Bedrijven zoals Verizon, Bloomberg, Bank of America en nog veel meer gebruiken HBase en Cassandra wordt gebruikt door grote sociale netwerksites zoals Twitter, Facebook enz …
We kunnen niet concluderen welke het beste is, HBase en Cassandra hebben beide hun eigen voor- en nadelen. De werkelijke prestaties van zowel HBase als Cassandra Databases zijn te zien in de productieomgeving.
Aanbevolen artikelen:
Dit is een leidraad geweest voor HBase versus Cassandra, hun betekenis, vergelijking van persoon tot persoon, belangrijkste verschillen, vergelijkingstabel en conclusie. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Hadoop vs Apache Spark - interessante dingen die u moet weten
- Hoe het Hadoop-ontwikkelaarsinterview te kraken?
- Top 5 Big Data-trends
- 5 uitdagingen van Big Data Analytics