

Verschil tussen Hadoop en HBase
Hadoop is een open-source Java-framework, dat wordt gebruikt voor het beheren en verwerken van een enorme hoeveelheid gestructureerde en ongestructureerde gegevens. Hadoop is enorm schaalbaar en wordt daarom gebruikt om big data-workloads te verwerken. Big data wordt opgeslagen, benaderd en verwerkt op het betrouwbare en uitbreidbare cluster. HBase (Hadoop Database) is een niet-relationele en niet alleen SQL ie NoSQL database die op de top van Hadoop draait als een gedistribueerde en schaalbare big data store. Het is een open-source database waarin gegevens worden opgeslagen in de vorm van rijen en kolommen, in die cel is een kruising van kolommen en rijen.
Hieronder staan de kerncomponenten van Hadoop-architectuur:
- Hadoop Distributed File System (HDFS): Hadoop bevat een gedistribueerd opslagsysteem, het Hadoop Distributed File System (HDFS). HDFS is de master-slave-architectuur die gegevens in het cluster opslaat. Gegevens verdeeld over meerdere slave-knooppunten door het hoofdknooppunt in het formulierblok. Het hoofdknooppunt wordt Namenode genoemd en slavenknooppunten worden Datanode genoemd. HDFS is eenvoudig uit te breiden en slaat een enorme hoeveelheid gegevens op op Datanodes. HDFS heeft een configureerbare replicatiefactor met standaardwaarde 3 die kan worden bewerkt.
- MapReduce: MapReduce is een programmeerparadigma, dat parallel wordt verwerkt op een groot aantal datasets via het netwerk. MapReduce verwijst naar twee verschillende taken: wijs de invoergegevens toe waarin gegevens worden verdeeld in een subset van gegevens die als tupels worden genoemd en taak verminderen deze tupels van de kaart als invoer en combineren om de uitvoer van origineel te vormen.
- Yarn: YARN staat voor Weer een andere resource-navigator die bronnen zoals CPU en geheugen beheert, planning van resource-aanvragen.
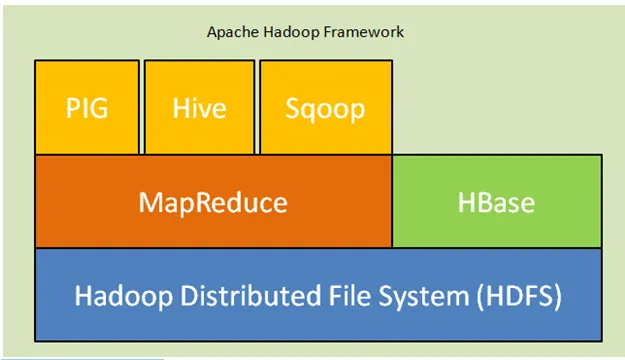
Fig. Apache Hadoop Framework
Regioserver dient gegevens voor lees- / schrijfbewerkingen. Alle HBase-gegevens worden opgeslagen in het HDFS-bestand. De HDFS Datanode slaat de gegevens op die de Region Server beheert. De HDFS Namenode bewaart metadata-informatie voor alle fysieke datablokken waaruit de bestanden bestaan.
Versiebeheer wordt gebruikt om celwijzigingen bij te houden, waardoor de versie van de inhoud wordt bijgehouden. Daaruit kan elke inhoudsversie worden opgehaald. Elke celwaarde bevat het kenmerk 'versie' met betrekking tot de tijdstempel om de cel op te halen. Elke waarde op de kaart is een ononderbroken reeks bytes. De kaart wordt geïndexeerd door een rijsleutel, een kolomsleutel en een tijdstempel. De architectuur van HBase is zeer schaalbare, schaarse, gedistribueerde, persistente en multidimensionale kaarten.
Vergelijking van kop tot kop tussen Hadoop en HBase (infographics)
Hieronder staat het top 7-verschil tussen Hadoop en HBase
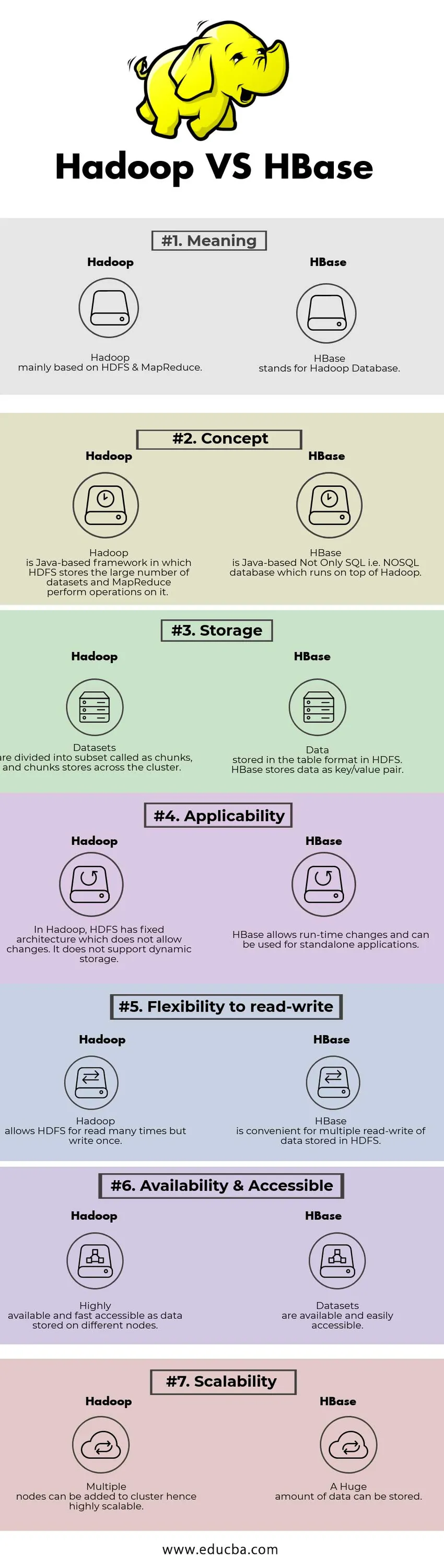
Belangrijkste verschillen tussen Hadoop en HBase
Het verschil tussen Hadoop en HBase wordt uitgelegd in de onderstaande punten:
- Hadoop is niet geschikt voor online analytische verwerking (OLAP) en HBase maakt deel uit van het Hadoop-ecosysteem dat willekeurige realtime toegang (lezen / schrijven) biedt tot gegevens in het Hadoop-bestandssysteem.
- Hadoop-framework is foutentolerant van ontwerp en ondersteunt snelle gegevensoverdracht tussen knooppunten, zelfs tijdens systeemfouten. HBase is een niet-relationele en open source niet-alleen-SQL-database die wordt uitgevoerd bovenop Hadoop. HBase valt onder het CP-type CAP (consistentie, beschikbaarheid en partitietolerantie).
- Hadoop is het meest geschikt voor het uitvoeren van batchanalyses. Een van de grootste nadelen is echter het onvermogen om realtime analyses uit te voeren, de trending-eis van de IT-industrie. HBase kan daarentegen grote datasets verwerken en is niet geschikt voor batchanalyses. In plaats daarvan wordt het gebruikt om real-time gegevens van Hadoop te schrijven / lezen.
- Zowel Hadoop als HBase kunnen gestructureerde, semi-gestructureerde en ongestructureerde gegevens verwerken. In Hadoop mist HDFS een in-memory verwerkingsmachine die het proces van data-analyse vertraagt; omdat het gewoon oude MapReduce gebruikt om het te doen. HBase, daarentegen, heeft een in-memory processor die de snelheid van lezen / schrijven drastisch verhoogt.
- Hadoop is zeer transparant in het uitvoeren van data-analyse. HBase daarentegen is een NoSQL-database in tabelvorm en haalt waarden op door ze onder verschillende sleutelwaarden te sorteren.
Vergelijkingstabel Hadoop vs HBase
| BASIS VOOR VERGELIJKING | Hadoop | HBase |
| Betekenis | Hadoop voornamelijk gebaseerd op HDFS & MapReduce. | HBase staat voor Hadoop Database. |
| Concept | Hadoop is een op Java gebaseerd framework waarin HDFS het grote aantal datasets opslaat en MapReduce daarop bewerkingen uitvoert. | HBase is op Java gebaseerde niet alleen SQL ie NoSQL database die bovenop Hadoop draait. |
| opslagruimte | Datasets zijn onderverdeeld in een subset die chunks wordt genoemd en chunks-winkels in het cluster. | Gegevens opgeslagen in de tabelindeling in HDFS. HBase slaat gegevens op als sleutel / waarde-paar. |
| toepasselijkheid | In Hadoop heeft HDFS een vaste architectuur die geen wijzigingen toestaat. Het ondersteunt geen dynamische opslag. | HBase maakt runtime-wijzigingen mogelijk en kan worden gebruikt voor zelfstandige toepassingen. |
| Flexibiliteit om te lezen en schrijven | Hadoop staat HDFS toe om vele malen te lezen, maar schrijf eenmaal. | HBase is handig voor meervoudig lezen en schrijven van gegevens die zijn opgeslagen in HDFS |
| Beschikbaarheid & Toegankelijk | Zeer beschikbaar en snel toegankelijk als gegevens die op verschillende knooppunten zijn opgeslagen. | Datasets zijn beschikbaar en gemakkelijk toegankelijk |
| schaalbaarheid | Er kunnen meerdere knooppunten worden toegevoegd om te clusteren, dus zeer schaalbaar. | Er kan een enorme hoeveelheid gegevens worden opgeslagen. |
Conclusie - Hadoop vs HBase
Hadoop-architectuur voornamelijk gebaseerd op HDFS en MapReduce. HBase is de ondersteunende component in het Hadoop-systeem. HBase kan enorme tabellen hosten en biedt snelle willekeurige toegang tot beschikbare gegevens, terwijl HDFS geschikt is voor het opslaan van grote bestanden. Zowel Hadoop als HBase bieden snelle toegang tot gegevens, maar met HBase kunnen lees- en schrijfbewerkingen worden uitgevoerd en voor HDFS vele malen lezen en eenmaal schrijven kan worden uitgevoerd. In dit artikel werd een begrip van Hadoop en HBase beschreven, kort aandacht besteed aan functies en verstandig vergeleken.
Aanbevolen artikel
- Apache Hadoop vs Apache Spark | Top 10 vergelijkingen die u moet weten!
- Hadoop vs Hive - Ontdek de beste verschillen
- HBase versus Cassandra - Welke is beter (Infographics)
- Top 12 vergelijking van Apache Hive vs Apache HBase (Infographics)
- Hadoop vs Spark: wat zijn de functies