
Verschillen tussen Data Scientist versus Machine Learning
Een Data Scientist is een expert die verantwoordelijk is voor het verzamelen, onderzoeken en interpreteren van grote hoeveelheden gegevens om manieren te vinden om een bedrijf te helpen zijn activiteiten te verbeteren en een concurrentievoordeel te behalen ten opzichte van rivalen. Het volgt een interdisciplinaire aanpak. Het ligt tussen de verbinding van wiskunde, statistiek, software engineering, kunstmatige intelligentie en ontwerpdenken. Het gaat over het verzamelen van gegevens, opschonen, analyseren, visualiseren, validatiemodel, voorspellen van experimenten, ontwerpen, testen en hypothese. Machine learning is een divisie van kunstmatige intelligentie die door data science wordt gebruikt om haar doelstellingen te bereiken. Machine Learning richt zich vooral op algoritmen, polynoomstructuren en het toevoegen van woorden. Het bestaat uit een groep algoritmen, machines waarmee ze kunnen leren zonder dat ze daarvoor duidelijk zijn geprogrammeerd.
Data scientist
Deze rol van gegevenswetenschapper is een onderdeel van de rol van de statistiek, waaronder het gebruik van de geavanceerde versie van analysetechnologieën, inclusief machine learning en voorspellende modellen, om visies te bieden die verder gaan dan statistische analyse. De petitie voor data science-vaardigheden is de afgelopen jaren aanzienlijk gegroeid, omdat bedrijven nuttige informatie proberen te verzamelen uit de enorme hoeveelheden gestructureerde, semi-gestructureerde en ongestructureerde gegevens die een grote onderneming produceert en gezamenlijk aangeduid als big data. Het doel van alle stappen is alleen om inzichten uit gegevens te halen.
Standaard taken:
- Gegevens uit verschillende gestructureerde en ongestructureerde bronnen toewijzen, verzamelen en synthetiseren
- Verken, ontwikkel en pas intelligent leren toe op gegevens uit de praktijk, verstrek belangrijke bevindingen en succesvolle acties op basis daarvan
- Analyseer en verstrek gegevens die in de organisatie zijn verzameld
- Ontwerp en bouw nieuwe processen voor modellering, datamining en implementatie
- Ontwikkel prototypes, algoritmen, voorspellende modellen, prototypes
- Voer verzoeken om gegevensanalyse uit en communiceer hun bevindingen en beslissingen
Daarnaast zijn er meer specifieke taken, afhankelijk van het domein waarin de werkgever werkt of het project wordt uitgevoerd.
Raw Data -> Data Science --> Actionable Insights
Machine leren
De functie Machine Learning Engineer is meer "technisch". ML Engineer heeft meer gemeen met klassieke Software Engineering dan Data Scientist. Het helpt u de objectieve functie te leren die de ingangen naar de doelvariabele en / of onafhankelijke variabelen naar de afhankelijke variabelen plot.
De standaardtaken van ML Engineer zijn over het algemeen zoals Data Scientist. U moet ook kunnen werken met gegevens, experimenteren met verschillende algoritmen voor Machine Learning die de taak zullen oplossen, prototypes en kant-en-klare oplossingen maken.
De vereiste kennis en vaardigheden voor deze functie overlappen ook met Data Scientist. Van de belangrijkste verschillen zou ik willen noemen:
- Sterke programmeervaardigheden in een of meer populaire talen (meestal Python en Java), evenals in databases;
- Minder nadruk op het vermogen om te werken in data-analyseomgevingen, maar meer nadruk op machine learning-algoritmen;
- R en Python voor modellering hebben de voorkeur boven Matlab, SPSS en SAS;
- Mogelijkheid om kant-en-klare bibliotheken te gebruiken voor verschillende stapels in de toepassing, bijvoorbeeld Mahout, Lucene voor Java, NumPy / SciPy voor Python;
- Mogelijkheid om gedistribueerde applicaties te maken met behulp van Hadoop en andere oplossingen.
Zoals u kunt zien, vereist de positie van ML Engineer (of smaller) meer kennis in Software Engineering en is daarom goed geschikt voor ervaren ontwikkelaars. Heel vaak werkt de zaak wanneer de gebruikelijke ontwikkelaar de ML-taak voor zijn taak moet oplossen en hij de benodigde algoritmen en bibliotheken begint te begrijpen.
Vergelijking tussen gegevenswetenschapper en machinaal leren
Hieronder vindt u de top 5 verschillen tussen Data Scientist en Machine Learning Engineer 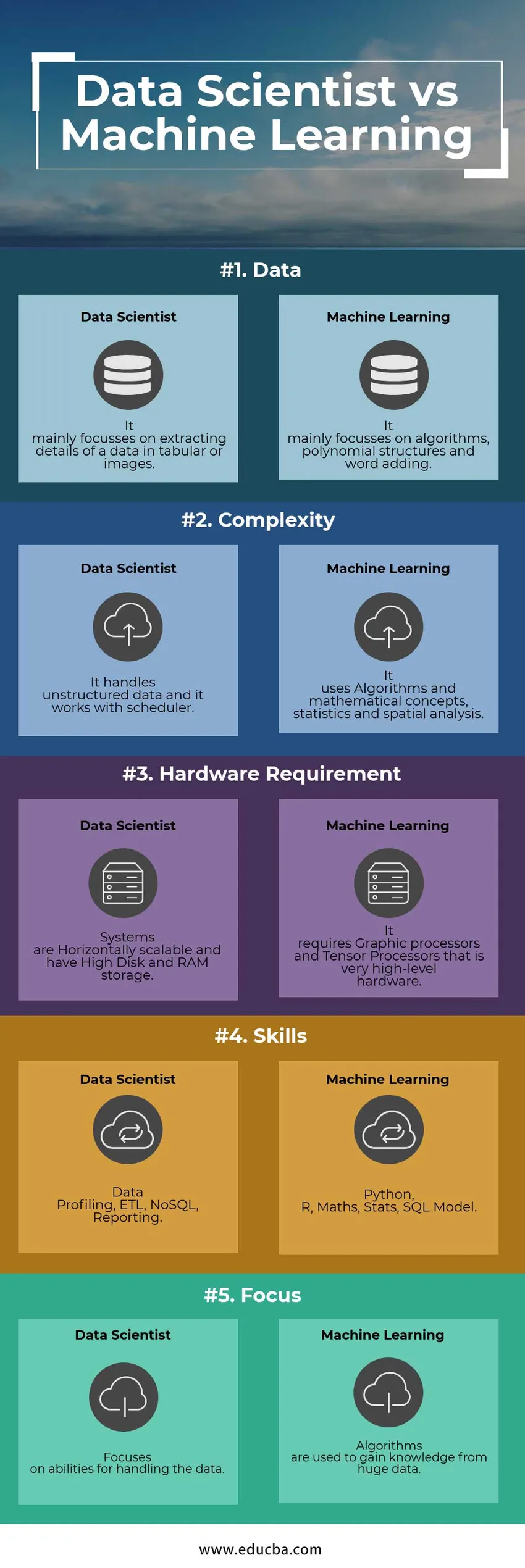
Belangrijk verschil tussen gegevenswetenschapper versus machinaal leren
Hieronder staan de lijst met punten, beschrijf de belangrijkste verschillen tussen Data Scientist en Machine Learning Engineer
- Machine learning en statistieken maken deel uit van data science. Het woord leren in machine learning betekent dat de algoritmen afhankelijk zijn van bepaalde gegevens, gebruikt als trainingsset, om sommige model- of algoritmeparameters te verfijnen. Dit omvat veel technieken zoals regressie, naïeve Bayes of begeleide clustering. Maar niet alle technieken passen in deze categorie. Zo is onbewaakte clustering - een statistische en data science techniek - gericht op het detecteren van clusters en clusterstructuren zonder voorafgaande kennis of training om het classificatie-algoritme te helpen. Er is een mens nodig om de gevonden clusters te labelen. Sommige technieken zijn hybride, zoals semi-gecontroleerde classificatie. Sommige technieken voor patroondetectie of dichtheidsschatting passen in deze categorie.
- Data science is echter veel meer dan machine learning. Gegevens, in de gegevenswetenschap, kunnen al dan niet afkomstig zijn van een machine of mechanisch proces (enquêtegegevens kunnen handmatig worden verzameld, klinische onderzoeken omvatten een specifiek type kleine gegevens) en het heeft misschien niets te maken met leren, zoals ik zojuist heb besproken. Maar het belangrijkste verschil is het feit dat data science het hele spectrum van gegevensverwerking omvat, niet alleen de algoritmische of statistische aspecten. Data science omvat ook data-integratie, gedistribueerde architectuur, geautomatiseerde machine learning, datavisualisatie, dashboards en Big data-engineering.
Data Scientist versus Machine Learning Vergelijkingstabel
Hieronder volgen de lijst met punten, beschrijf de vergelijkingen tussen Data Scientist versus Machine Learning engineer:
| Voorzien zijn van | Data scientist | Machine leren |
| Gegevens | Het richt zich vooral op het extraheren van gegevens in tabelvorm of afbeeldingen | Het richt zich vooral op algoritmen, polynoomstructuren en het toevoegen van woorden |
| ingewikkeldheid | Het verwerkt ongestructureerde gegevens en het werkt met de planner | Het maakt gebruik van algoritmen en wiskundige concepten, statistieken en ruimtelijke analyse |
| Hardwarevereiste | Systemen zijn horizontaal schaalbaar en hebben een hoge schijf- en RAM-opslag | Het vereist grafische processors en Tensor-processors die hardware op zeer hoog niveau zijn |
| Vaardigheden | Gegevensprofilering, ETL, NoSQL, rapportage | Python, R, Maths, Stats, SQL Model |
| Focus | Richt zich op mogelijkheden voor het verwerken van de gegevens | Algoritmen worden gebruikt om kennis te vergaren uit enorme gegevens |
Conclusie - Data Scientist versus Machine Learning
Machinaal leren helpt u de objectieve functie te leren die de ingangen naar de doelvariabele en / of onafhankelijke variabelen naar de afhankelijke variabelen plot
Een datawetenschapper onderzoekt veel gegevens en komt tot de brede strategie om deze aan te pakken. Hij is verantwoordelijk voor het stellen van vragen binnen de gegevens en vindt welke antwoorden men redelijkerwijs uit gegevens kan putten. Feature engineering behoort tot het domein van Data Scientist. Creativiteit speelt hier ook een rol en een machineleertechnicus kent meer tools en kan modellen bouwen met een reeks functies en gegevens - volgens de aanwijzingen van de Data Scientist. Het rijk van gegevensvoorbewerking en extractie van functies behoort toe aan ML engineer.
Data science en onderzoek maken gebruik van machine learning voor dit soort archetypische validatie en creatie. Het is van vitaal belang om op te merken dat alle algoritmen in deze modelcreatie mogelijk niet afkomstig zijn van machine learning. Ze kunnen uit tal van andere velden komen. Het model wil altijd relevant blijven. Als de situaties veranderen, kan het model dat we eerder hebben gemaakt, niet van belang zijn. De modelvereisten moeten op verschillende tijdstippen op hun zekerheid worden gecontroleerd en moeten worden aangepast als de zekerheid vermindert.
Data science is een heel groot domein. Als we proberen het in een pijplijn te plaatsen, zou het data-acquisitie, data-opslag, data-preprocessing of data-opschoning, leerpatronen in data (via machine learning) hebben, met behulp van leren voor voorspellingen. Dit is een manier om te begrijpen hoe machine learning past in data science.
Aanbevolen artikel
Dit is een leidraad geweest voor verschillen tussen Data Scientist versus Machine Learning-ingenieur, hun betekenis, vergelijking van persoon tot persoon, belangrijkste verschillen, vergelijkingstabel en conclusie. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Datamining versus machinaal leren - 10 beste dingen die u moet weten
- Machine Learning versus Predictive Analytics - 7 nuttige verschillen
- Data Scientist versus Business Analyst - Ontdek de 5 geweldige verschillen
- Data Scientist versus Data Engineer - 7 Verbazingwekkende vergelijkingen
- Vragen tijdens solliciteren bij Software Engineering | Top en meest gestelde