

Introductie van Python Pandas DataFrame
Meerdere uitbreidingen voor de Python-bibliotheek, Panda's, zijn online te vinden. Een daarvan is Panel (pan) Data (das). Dit woord, * Panel *, verwijst subtiel naar een tweedimensionale datastructuur in deze bibliotheek, die de gebruikers enorm machtigt. Deze structuur wordt een DataFrame genoemd.
Het is in wezen een matrix van rijen en kolommen, die uw volledige gegevensset bevat, met zeer uitgebreide opties om hetzelfde te indexeren. Het DataFrame (DF) is denkbeeldig vergelijkbaar met een Excel-sheet. Maar wat het krachtig maakt, is het gemak waarmee analytische en transformationele bewerkingen kunnen worden uitgevoerd op de gegevens die zijn opgeslagen in een DataFrame.
Wat is precies een Python Pandas DataFrame?
Pydata-pagina kan worden verwezen voor een officiële definitie.
Indien correct begrepen, vermeldt het DataFrame als een kolomstructuur, die elk python-object (inclusief een DataFrame zelf) kan opslaan als één celwaarde. (Een cel wordt geïndexeerd met een unieke rij en kolomcombinatie)
DataFrames bestaat uit drie essentiële componenten: gegevens, rijen en kolommen.
- Gegevens: het verwijst naar de werkelijke objecten / entiteiten die zijn opgeslagen in een cel in het DataFrame en de waarden die door deze entiteiten worden voorgesteld. Een object is van elk geldig python-gegevenstype, ingebouwd of door de gebruiker gedefinieerd.
- Rijen: verwijzingen die worden gebruikt om een bepaalde reeks observaties van de volledige gegevens die zijn opgeslagen in een DataFrame te identificeren (of te indexeren) worden de rijen genoemd. Om het duidelijk te maken, het vertegenwoordigt de gebruikte indices en niet alleen de gegevens in een bepaalde waarneming.
- Kolommen: verwijzingen die worden gebruikt om een set attributen voor alle waarnemingen in een DataFrame te identificeren (of te indexeren). Net als in het geval van rijen verwijzen deze naar de kolomindex (of de kolomkoppen) in plaats van alleen de gegevens in de kolom.
Laten we dus zonder verder oponthoud enkele manieren uitproberen om deze ontzettend krachtige structuren te maken.
Stappen voor het maken van Python Pandas DataFrames
Een Python Pandas DataFrame kan worden gemaakt met de volgende code-implementatie,
1. Panda's importeren
Om DataFrames te maken, moet de panda'sbibliotheek worden geïmporteerd (geen verrassing hier). We zullen het gemakkelijk importeren met een alias pd om naar referentieobjecten onder de module te verwijzen.
Code:
import pandas as pd
2. Het eerste DataFrame-object maken
Nadat de bibliotheek is geïmporteerd, zijn alle methoden, functies en constructors beschikbaar in uw werkruimte. Laten we dus proberen een vanille DataFrame te maken.
Code:
import pandas as pd
df = pd.DataFrame()
print(df)
Output:
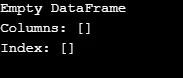
Zoals weergegeven in de uitvoer, retourneert de constructor een leeg DataFrame.
Laten we ons nu concentreren op het maken van DataFrames op basis van gegevens die zijn opgeslagen in enkele van de waarschijnlijke representaties.
- DataFrame from A Dictionary: Stel dat we een woordenboek hebben waarin een lijst met bedrijven in Software Domain wordt opgeslagen en het aantal jaren dat ze actief zijn.
Code:
import pandas as pd
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Infosys', 'Directi'),
'Age':('21', '23', '38', '22') ))
print (df)
Laten we de weergave van het geretourneerde DataFrame-object bekijken door het op de console af te drukken.
Output:

Zoals te zien is, wordt elke sleutel van het woordenboek behandeld als een kolom in het DataFrame en worden de rij-indexen automatisch gegenereerd vanaf 0. Vrij eenvoudig he!
Laten we zeggen dat u het een aangepaste index wilde geven in plaats van 0, 1, .. 4. U hoeft alleen de gewenste lijst als parameter door te geven aan de constructeur en panda's zullen het nodige doen.
Code:
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Yahoo', 'Infosys', 'Directi'),
'Age':('21', '23', '24', '38', '22') ),
index=('Alpha', 'Beta', 'Gamma', 'Delta'))
print(df)
Output:
Bedrijf leeftijd
Alpha Google 21
Beta Amazon 23
Gamma Infosys 38
Delta Directi 22
Nu kunt u rij-indexen op elke gewenste waarde instellen.
- DataFrame van een CSV-bestand: Laten we een CSV-bestand maken met dezelfde gegevens als in ons woordenboek. Laten we het bestand CompanyAge.csv noemen
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
Het bestand kan als volgt in een dataframe worden geladen (ervan uitgaande dat het in de huidige werkmap aanwezig is).
Code:
csv_df = pd.read_csv(
'CompanyAge.csv', names=('Company', 'Age'), header=None)
print(csv_df)
Output:
Bedrijf leeftijd
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
Door de parameternamen in te stellen , een zoeklijst te omzeilen, worden ze als kolomkoppen toegewezen in dezelfde volgorde als in de lijst. Op dezelfde manier kunnen rij-indices worden ingesteld door een lijst door te geven aan de indexparameter, zoals getoond in de vorige sectie. De kop = Geen duidt op ontbrekende kolomkoppen in het gegevensbestand.
Laten we zeggen dat de kolomnamen deel uitmaakten van het gegevensbestand. Dan stelt header = False het vereiste werk in.
3. CompanyAgeWithHeader.csv
Bedrijf, leeftijd
Google, 21
Amazon, 23
Infosys, 38
Directi, 22
De code zal veranderen in
csv_df = pd.read_csv(
'CompanyAgeWithHeader.csv', header=False)
print(csv_df)
Output:
Bedrijf leeftijd
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
- DataFrame van een Excel-bestand: vaak worden gegevens gedeeld in excel-bestanden omdat het de meest populaire tool blijft die door mensen wordt gebruikt voor adhoc-tracking. Daarom moet het niet worden genegeerd door onze discussie.
Laten we aannemen dat de gegevens, dezelfde als in CompanyAgeWithHeader.csv, nu worden opgeslagen in CompanyAgeWithHeader.xlsx, in een blad met de naam Company Age. Hetzelfde DataFrame als hierboven wordt aangemaakt door de volgende code.
Code:
excel_df= pd.read_excel('CompanyAgeWithHeader.xlsx', sheet_name='CompanyAge')
print(excel_df)
Output:
Bedrijf leeftijd
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
Zoals u kunt zien, kan hetzelfde DataFrame worden gemaakt door de bestandsnaam en de bladnaam door te geven.
Verder lezen en volgende stappen
De getoonde methoden vormen een zeer kleine subset in vergelijking met alle verschillende manieren waarop DataFrames kunnen worden gemaakt. Deze zijn gemaakt met de bedoeling er een te starten. U moet zeker de vermelde referenties verkennen en andere manieren proberen te verkennen, zoals verbinding maken met een database om gegevens rechtstreeks in een DataFrame te lezen.
Conclusie
Pandas DataFrame heeft bewezen een doorbraak te zijn in de wereld van Data Science en Data Analytics, en is ook handig voor ad-hoc kortetermijnprojecten. Het wordt geleverd met een hele reeks hulpmiddelen die in staat zijn om de gegevensset met extreem gemak te snijden en in blokjes te snijden. Hopelijk zal dit als een opstapje dienen in je komende reis.
Aanbevolen artikelen
Dit is een gids voor Python-Pandas DataFrame. Hier bespreken we de stappen om een dataframe voor python-panda's te maken, samen met de implementatie van de code. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Top 15 kenmerken van Python
- Verschillende soorten Python-sets
- Top 4 soorten variabelen in Python
- Top 6 editors van Python
- Arrays in gegevensstructuur