

Inleiding tot HBase Architecture
HBase is een open-source, gedistribueerd sleutel-waarde gegevensopslagsysteem en kolomgeoriënteerde database met hoge schrijfoutput en lage latentie random leesprestaties. Door HBase te gebruiken, kunnen we online realtime analyses uitvoeren. HBase-architectuur is sterk willekeurig leesbaar. In HBase worden gegevens fysiek verdeeld in zogenaamde regio's. Elke regio wordt gehost door een enkele regioserver en een of meer regio's zijn verantwoordelijk voor elke regioserver. De HBase-architectuur bestaat uit master-slave-servers. Het cluster HBase heeft één masterknooppunt genaamd HMaster en verschillende regioservers genaamd HRegion Server (HRegion Server). Er zijn meerdere regio's - regio's in elke regionale server.
HDFS-opslagmechanisme

In HDFS worden gegevens opgeslagen in de tabel zoals hierboven weergegeven.
Elke rij heeft een sleutel.
Kolom: het is een verzameling gegevens die tot één kolomfamilie behoort en die in de rij is opgenomen.
Kolomfamilie: elke kolomfamilie bestaat uit een of meer kolommen.
Elke tabel bevat een verzameling Kolomfamilies. Deze kolommen maken geen deel uit van het schema.
HBase heeft dynamische kolommen. Verschillende cellen kunnen verschillende kolommen hebben omdat kolomnamen in de cellen worden gecodeerd
Kolomkwalificatie: Kolomnaam staat bekend als Kolomkwalificatie.
HBase-architectuurcomponenten
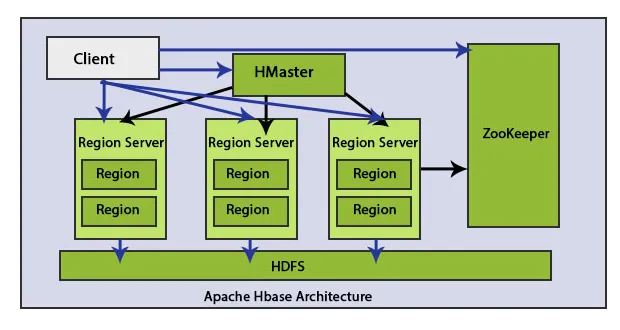
Er zijn hoofdelementen in de HBase-architectuur: HMaster en Region Server. Regionale HBase-gegevens opslaan.
1. HMaster
Het HMaster-knooppunt is lichtgewicht en wordt gebruikt voor het toewijzen van de regio aan de serverregio.
Er zijn enkele hoofdverantwoordelijkheden van Hmaster die zijn:
- Enkele beheertaken uitvoeren, zoals laden, balanceren, gegevens maken, bijwerken, verwijderen, enz.
Verantwoordelijk voor wijzigingen in het schema of wijzigingen in META-gegevens volgens de richting van de clienttoepassing
- Veel DDL-werk aan HBase-tafels wordt afgehandeld door HMaster.
Sommige van de methoden die HMaster Interface blootlegt, zijn hoofdzakelijk. META-gegevensgeoriënteerde methoden.
- Tabel (tabel maken, verwijderen, inschakelen, uitschakelen, verwijderen)
- ColumnFamily (voeg Kolom toe, wijzig Kolom)
- Regio (verplaatsen, toewijzen)
De client communiceert bidirectioneel met zowel HMaster als ZooKeeper. Het neemt rechtstreeks contact op met HRegion-servers voor lees- en schrijfbewerkingen. HMaster wijst regio's toe aan servers in de regio en controleert op zijn beurt de gezondheidsstatus van regionale servers.
2. Regioserver
We kunnen een ruw idee krijgen van de regioserver door een hieronder gegeven diagram.

Regioservers zijn werkende knooppunten die verzoeken van klanten om lezen, schrijven, bijwerken en verwijderen afhandelen. Region Server is licht van gewicht en draait op alle knooppunten van het cluster Hadoop. De hoofdtaak van de regioserver is het opslaan van de gegevens in gebieden en het uitvoeren van klantverzoeken. Een andere belangrijke taak van de HBase Region Server is om de Auto-Sharding-methode te gebruiken om load-balancing uit te voeren door de HBase-tabel dynamisch te distribueren wanneer deze te groot wordt na het invoegen van gegevens.
HMaster kan met meerdere HRegion-servers contact opnemen en de volgende functies uitvoeren:
- Hostings beheren en regio's
- Automatisch gesplitste regio's
- Behandeling van verzoeken om lezen en schrijven
- Directe communicatie met klanten
3. HDFS
HDFS staat voor het Hadoop Distributed File-systeem. Het slaat elk bestand op in verschillende blokken en repliceert blokken in een Hadoop-cluster om fouttolerantie te behouden. HDFS levert hoge fouttolerantie en werkt met goedkope materialen. Door goedkope basishardware te gebruiken om knooppunten aan het cluster toe te voegen en te verwerken en op te slaan, krijgt de klant betere resultaten dan de bestaande hardware. HDFS maakt contact met de componenten van HBase en bewaart veel gegevens op een gedistribueerde manier.
4. Zookeeper
Zookeeper is een open-source project. HMaster en HRegionServers registreren zichzelf bij ZooKeeper.
Het biedt verschillende services zoals het onderhouden van configuratie-informatie, naamgeving, het leveren van gedistribueerde synchronisatie, etc. Gedistribueerde synchronisatie is het proces van het leveren van coördinatiediensten tussen knooppunten voor toegang tot actieve applicaties. Het heeft kortstondige knooppunten die regioservers vertegenwoordigen. Masterservers gebruiken deze knooppunten om te zoeken naar beschikbare servers.
Deze knooppunten worden ook gebruikt om netwerkpartities en serverstoringen bij te houden. Zookeeper is het interactiemedium tussen de clientregioserver. Als een client met de regioserver wil communiceren, dan is zookeeper het communicatiemedium tussen hen.
Hoe zoeken wordt geïnitialiseerd in HBase-architectuur
Zoals u weet, wordt de META-tabellocatie opgeslagen door Zookeeper. Wanneer een klant aanvragen voor HBase benadert of schrijft, is de procedure als volgt.
De klant komt uit de ZooKeeper te weten hoe hij deze META-tafel moet plaatsen. De client vraagt vervolgens de juiste rijsleutel van de META-tabel om toegang te krijgen tot de regioserverlocatie. Met de META-tabellocatie bewaart de klant deze informatie. De klant verwijst niet naar de META-tabel totdat en of het gebied wordt verplaatst of verplaatst. Vervolgens wordt de META-server opnieuw aangevraagd en wordt de cache bijgewerkt. Zoals altijd verspillen klanten geen tijd aan het vinden van de Region Server-locatie op META Server, dus dit bespaart tijd en versnelt het zoekproces.
Kenmerken
Het is gemakkelijk te integreren vanaf de bron en de bestemming met Hadoop.
De gedistribueerde opslag zoals HDFS wordt ondersteund.
Het heeft een functie voor willekeurige toegang door een interne hashtabel te gebruiken om gegevens op te slaan voor snellere zoekopdrachten in HDFS-bestanden.
Voordelen van HBase Architecture
- Deze kunnen grote gegevenssets opslaan
- We kunnen de database delen
- Gigabytes tot petabytes kosteneffectief
- Hoge beschikbaarheid door replicatie en mislukking
Nadelen van HBase Architecture
- SQL-structuur ondersteunt niet
- Ondersteunt geen transactie
- Alleen met sleutel gesorteerd
- Cluster geheugenproblemen
Conclusie
HBase is een van de niet-SQL-kolomgeoriënteerde gedistribueerde database in apache. In vergelijking met Hadoop of Hive presteert HBase beter voor het ophalen van minder records. Dus in dit artikel hebben we HBase-architectuur en de belangrijke componenten ervan besproken.
Aanbevolen artikelen
Dit is een gids voor HBase Architecture geweest. Hier hebben we het concept, de componenten, functies, voordelen en nadelen besproken. U kunt ook onze andere voorgestelde artikelen doornemen voor meer informatie -
- Wat is big data-technologie?
- HDFS versus HBase Welke is beter
- Wat is assemblagetaal?
- Inleiding tot HTML