

Hoe Apache te installeren
Voordat we ingaan op het installeren van het Apache-gedeelte, hebben we eerst een algemeen overzicht van Apache en hoe het wordt gebruikt in de gegevenswetenschap.
Wat is Apache?

Apache Web Server is een HTTP-server die websites presenteert aan bezoekers die naar uw server komen. Dus als u een website voor een bedrijf of uw organisatie wilt implementeren, zou u daar waarschijnlijk Apache voor gebruiken.
Er zijn andere HTTP-servers, zoals IIS, maar Apache is de standaard die de meeste mensen gebruiken, of ze nu op Linux, Windows of Mac zijn. Apache is de standaard waar de meeste mensen naartoe gaan omdat het bekend is, het is zeer betrouwbaar en het is gratis.
Eén ding dat je je moet realiseren met Apache is dat het een HTTP-server is, dus als je dit op Linux of Windows of Mac installeert, zou je alleen statische websites mogen presenteren aan bezoekers die naar je server komen. Als u dus een HTML-website codeert zonder andere programmeertalen dan JavaScript, kunt u die gebruiken met alleen een Apache-server. U kunt al uw tags op de Apache-server aansluiten en aan uw bezoekers presenteren.
Hoe gebruikte Apache in Data Science?
Data Science is het meest gevraagde studiegebied in de moderne wereld. Data Scientist wordt beschouwd als de meest sexy baan in de 21ste eeuw waarbij professionals uit verschillende disciplines willen leren en Data Scientist willen worden. Apache speelt een cruciale rol in elke liefhebber van data science, omdat ze voldoende kennis van het Apache Hadoop Ecosysteem nodig hebben.
Apache Hadoop Ecosysteem
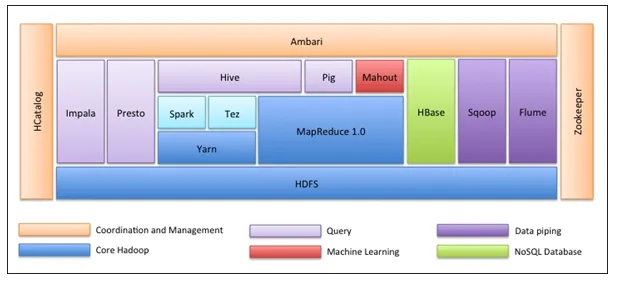
Het allereerste ding is dat het Hadoop-ecosysteem niet één hulpmiddel is. Het is geen programmeertaal of een enkel kader. Het is een groep tools die door verschillende bedrijven in verschillende domeinen samen voor meerdere taken worden gebruikt. We zullen elke tool hieronder een voor een doorlopen: -
- Apache HDFS (Hadoop Distributed File System) is de opslageenheid van Hadoop die gestructureerde, semi-gestructureerde en ongestructureerde gegevens kan opslaan. HDFS heeft metadata die het logbestand bijhoudt over de opgeslagen gegevens. Het heeft twee componenten - NameNode en DataNode.
- Apache Yarn is de resourceonderhandelaar die alle verwerkingsactiviteiten uitvoert, zoals het plannen van taken, het toewijzen van resources, enz. Het heeft twee services: ten eerste is de Resource Manager die applicaties plant die op Garen draaien. Ten tweede is de Node Manager die het gebruik van bronnen bewaakt .
- Apache Map Reduce is de component Gegevensverwerking van Hadoop die grote datasets verwerkt met behulp van gedistribueerde en parallelle computing op basis van de functies Map, Sort en Shuffle en Reduce. Met de kaartfunctie worden de gegevens gefilterd, vervolgens gesorteerd en geschakeld en aan het einde worden de functie-aggregaten verkleind en wordt het resultaat samengevat.
- Apache Pig wordt meestal in ETL gebruikt. Het bestaat uit twee delen - Pig Latin en de Pig runtime. Pig Latin is de taal die wordt gebruikt voor gegevensverwerking met behulp van een query, terwijl Pig runtime de uitvoeringsomgeving is. Eén regel Pig Latin is bijna gelijk aan 100 regels Map Reduce-code. Het proces omvat eerst het laden van de gegevens en vervolgens groeperen, sorteren, filteren en opslaan in HDFS.
- Apache Hive gebruikt een SQL-achtige query om gegevens in een gedistribueerde omgeving te analyseren. Het heeft twee componenten - de Hive-opdrachtregel en de JDBC / ODBC-server en de gebruikte taal wordt HiveQL genoemd.
- Apache Mahout is de Machine Learning-bibliotheek geschreven in Java en gebruikt om machine learning-applicaties te maken zoals clustering, classificatie of regressie. Het heeft verschillende algoritmen ingebouwd voor verschillende gebruikssituaties.
- Apache HBase is een NoSQL-database geschreven in Java die over Hadoop loopt. Het is gebaseerd op de BigTable van Google en kan alle soorten gegevens verwerken.
- Apache Sqoop is een tool voor het opnemen van gegevens die wordt gebruikt voor gestructureerde bulkoverdracht van gegevens tussen RDBMS en Hadoop.
- Apache Flume is een ander hulpmiddel voor het opnemen van gegevens dat wordt gebruikt voor semi-gestructureerde en ongestructureerde gegevensoverdracht tussen Hadoop en andere gegevensbronnen.
- ZooKeeper is de coördinator die zorgt voor coördinatie tussen verschillende tools in het Hadoop-ecosysteem.
- Apache Ambari is een Cluster Manager die voorzieningen heeft, Hadoop-clusters beheert en ook hun gezondheid en status bewaakt.
- Apache Tez is een nieuw hulpmiddel in het Hadoop-ecosysteem dat de Query-verwerking van Hadoop versnelt.
- Apache Presto is een open source gedistribueerde SQL-query-engine die platformonafhankelijke query-mogelijkheden mogelijk maakt.
- Apache HCatalog is een metadata- en tafelbeheersysteem voor Hadoop dat interoperabiliteit tussen gegevensverwerkingstools mogelijk maakt. Het helpt gebruikers ook bij het kiezen van de beste tools voor hun omgeving.
- Apache Spark is het meest gebruikte en populaire framework onder de Data Scientist. Het is een high-speed clustercomputersysteem dat het gebruik van resources optimaliseert in geval van veel iteratieve taken. Het biedt flexibiliteit voor zowel batchverwerking als realtime gegevensanalyse.
Hieronder zijn de stappen om Apache te installeren
Tot nu toe hebben we geleerd over Apache en hoe het nuttig is voor iedereen die Data Science of Big Data Analytics wil leren. Nu zullen we naar beneden duiken en apache op Windows installeren op basis van de onderstaande stappen.
- Ga naar https://httpd.apache.org/ en klik op de koppeling Downloaden onder de sectie Apache httpd 2.4.38 Released.

- U gaat naar de volgende pagina en klik vervolgens op Bestanden voor Microsoft Windows.
- Klik op Apache Lounge.

- U kunt 32-bits of 64-bits van het zip-bestand downloaden op basis van uw Windows-besturingssysteem. We zullen de 64-bits versie hier downloaden. Klik op de overeenkomstige .zip-link om te downloaden.

- Nu vereist het C ++ Redistributable Visual Studio 2017. Dus we zullen het downloaden van de overeenkomstige 32-bit of 64-bit link

- Nadat beide bestanden zijn gedownload, gaan we naar de gedownloade locatie en installeren eerst C ++ Redistributable Visual Studio 2017. Dubbelklik op het .exe-bestand.

- Vink 'Ik ga akkoord' aan en klik op Installeren.

- De installatie van Apache is bezig.
- Als het eenmaal is voltooid, ontvangt u een bericht als dit. Klik op Sluiten om de installatie te voltooien.
- Ga nu naar de map waar u het Apache-zipbestand downloadt. Klik er met de rechtermuisknop op en selecteer hier extract.
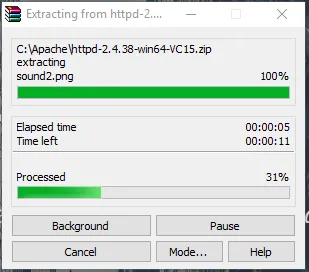
- Nu hebben we een map Apache24 aangemaakt. Kopieer deze map naar C-station en dan voegen we een pad toe naar systeemomgevingsvariabelen.
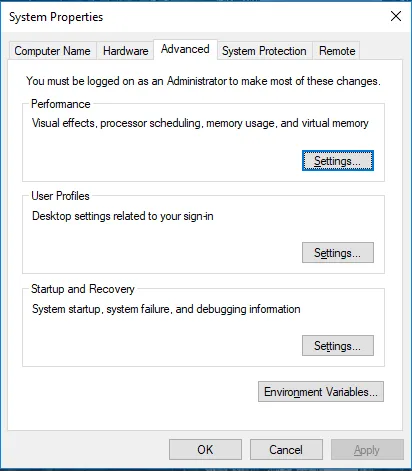
Ga naar Systeemeigenschappen -> tabblad Geavanceerd -> Klik hieronder op de knop Omgevingsvariabelen.
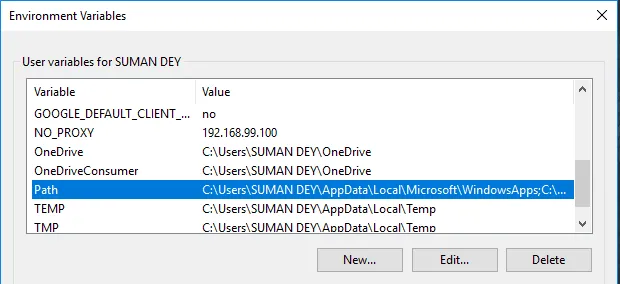
- Zoek in Variabelen Pad en klik op Bewerken.
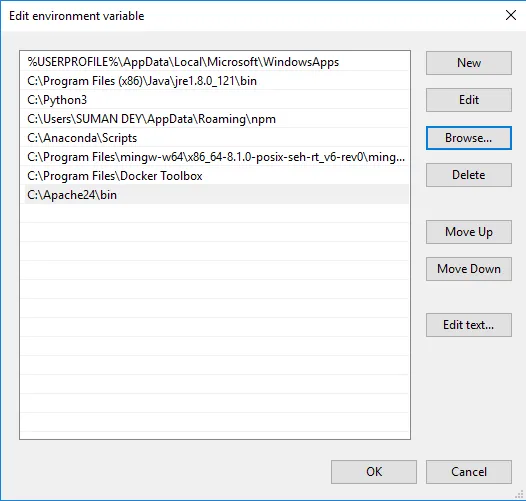
- Klik op Bladeren -> Ga naar map C-drive Apache24 -> Selecteer map bin -> Klik op OK.
- We zullen Apache installeren als een Windows-service. Voer opdrachtprompt uit als beheerder. Typ httpd –k install en druk op enter.
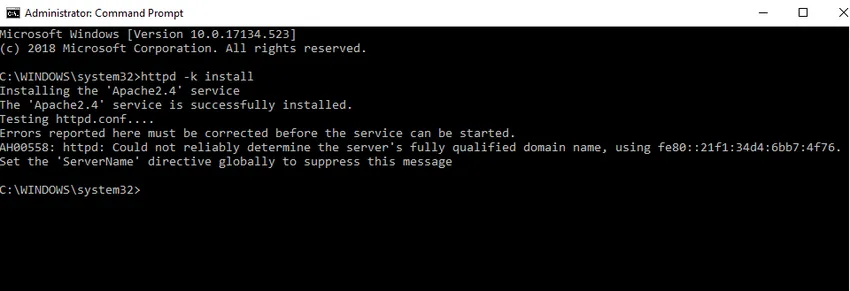
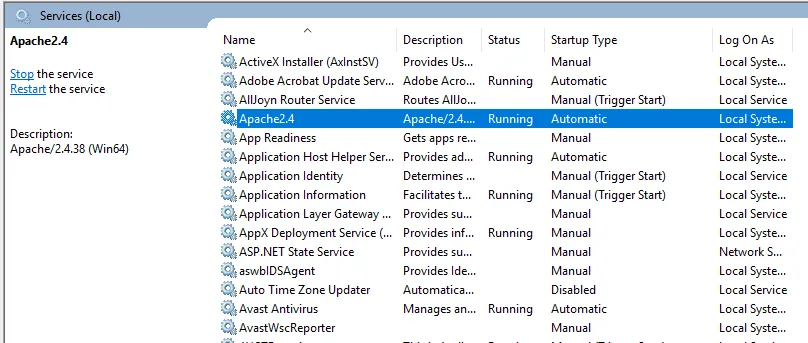
- We controleren de installatie van Apache-service. Klik op het Windows-pictogram en typ services. Klik op de app Services en zoek een service met de naam Apache24.

- Klik met de rechtermuisknop op de Apache-server en klik op start. De status verandert in 'Actief'.
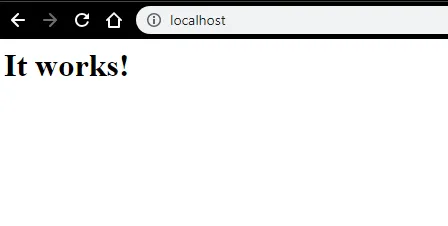
- We kunnen testen met een browser. Open een browser en navigeer naar http: // localhost en druk op enter. Een bericht waarin staat: 'Het werkt!' zal verschijnen om de succesvolle installatie van Apache te bevestigen.
Aanbevolen artikelen
Dit is een handleiding geweest voor het installeren van Apache. Hier hebben we de instructies en verschillende stappen besproken om Apache te installeren. U kunt ook het volgende artikel bekijken voor meer informatie -
- Sollicitatievragen voor Apache
- Apache Spark vs Apache Flink
- Apache Hadoop vs Apache Spark
- Apache Kafka tegen Flume
- Kafka vs Kinesis | Topverschillen