
Inleiding tot Poisson-regressie in R
Poisson-regressie is een type regressie die vergelijkbaar is met meervoudige lineaire regressie, behalve dat de respons of de afhankelijke variabele (Y) een telvariabele is. De afhankelijke variabele volgt de Poisson-verdeling. De voorspeller of onafhankelijke variabelen kunnen continu of categorisch van aard zijn. In zekere zin lijkt het op Logistieke regressie, die ook een discrete responsvariabele heeft. Voorafgaand begrip van de Poisson-verdeling en de wiskundige vorm ervan is zeer essentieel om deze te gebruiken voor voorspelling. In R kan Poisson-regressie op een zeer effectieve manier worden geïmplementeerd. R biedt een uitgebreide set functionaliteiten voor de implementatie ervan.
Poisson-regressie implementeren
We zullen nu gaan begrijpen hoe het model wordt toegepast. De volgende sectie geeft een stapsgewijze procedure voor hetzelfde. Voor deze demonstratie overwegen we de "gala" -dataset uit het "verre" pakket. Het heeft betrekking op de soortendiversiteit op de Galapagos-eilanden. Er zijn in totaal 7 variabelen in de gegevensset. We gebruiken Poisson-regressie om een relatie te definiëren tussen het aantal plantensoorten (soorten) en andere variabelen in de gegevensset.
1. Laad eerst het "verre" pakket. Als het pakket niet aanwezig is, download het dan met behulp van de functie install.packages ().
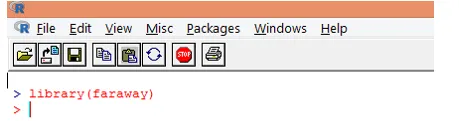
2. Nadat het pakket is geladen, laadt u de 'gala'-gegevensset in R met de functie data () zoals hieronder wordt getoond.
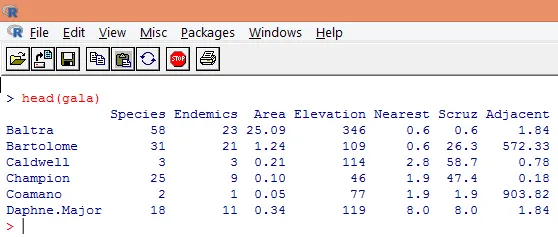
3. De geladen gegevens moeten worden gevisualiseerd om de variabele te bestuderen en te controleren of er verschillen zijn. We kunnen de volledige gegevens of alleen de eerste paar rijen ervan visualiseren met behulp van de functie head (), zoals weergegeven in de onderstaande schermafbeelding.
4. Om meer inzicht in de dataset te krijgen, kunnen we helpfunctionaliteit in R gebruiken zoals hieronder. Het genereert de R-documentatie zoals getoond in de screenshot volgend op de onderstaande screenshot.


5. Als we de gegevensset bestuderen zoals vermeld in de voorgaande stappen, kunnen we vaststellen dat Species een responsvariabele is. We zullen nu een basisoverzicht van de voorspellende variabelen bestuderen.
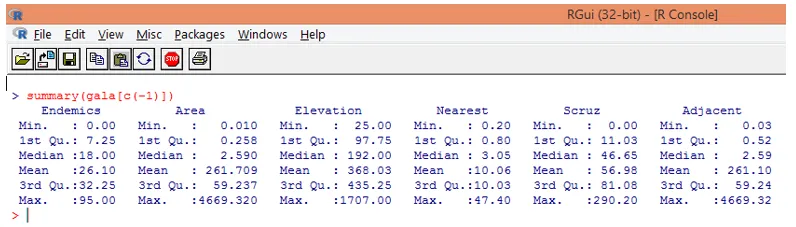
Let op, zoals hierboven te zien is, hebben we de variabele Species uitgesloten. De samenvattingfunctie geeft ons basisinzichten. Let gewoon op de mediaanwaarden voor elk van deze variabelen, en we kunnen vaststellen dat er een enorm verschil bestaat, in termen van het bereik van waarden, tussen de eerste helft en de tweede helft, bijvoorbeeld voor de mediaanwaarde van de variabele van het gebied is 2, 59, maar de maximale waarde is 4669.320.
6. Nu we klaar zijn met basisanalyse, genereren we een histogram voor Soorten om te controleren of de variabele de Poisson-verdeling volgt. Dit wordt hieronder geïllustreerd.

De bovenstaande code genereert een histogram voor soortenvariabele samen met een dichtheidscurve die eroverheen wordt gelegd.
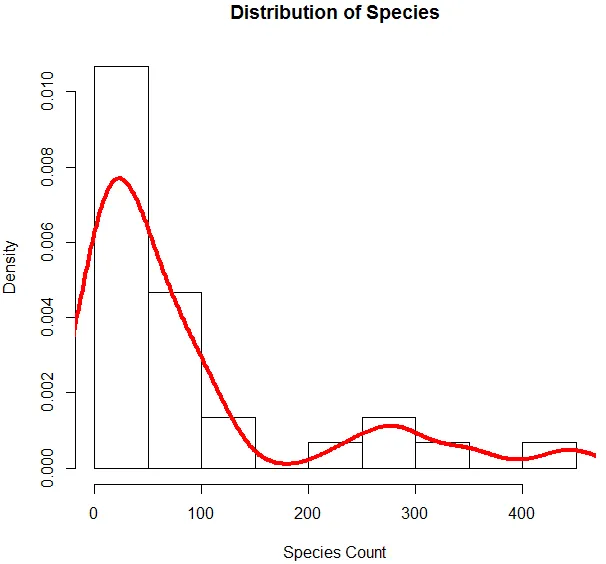
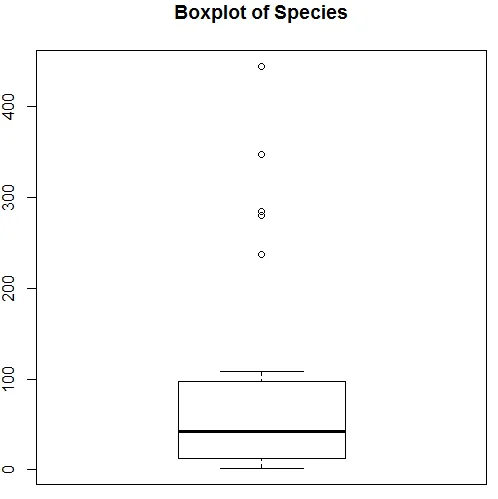
De bovenstaande visualisatie laat zien dat Soort een Poisson-verdeling volgt, omdat de gegevens scheef staan. We kunnen ook een boxplot genereren om meer inzicht te krijgen in het distributiepatroon zoals hieronder weergegeven.
7. Na de voorlopige analyse hebben we nu de Poisson-regressie toegepast zoals hieronder weergegeven
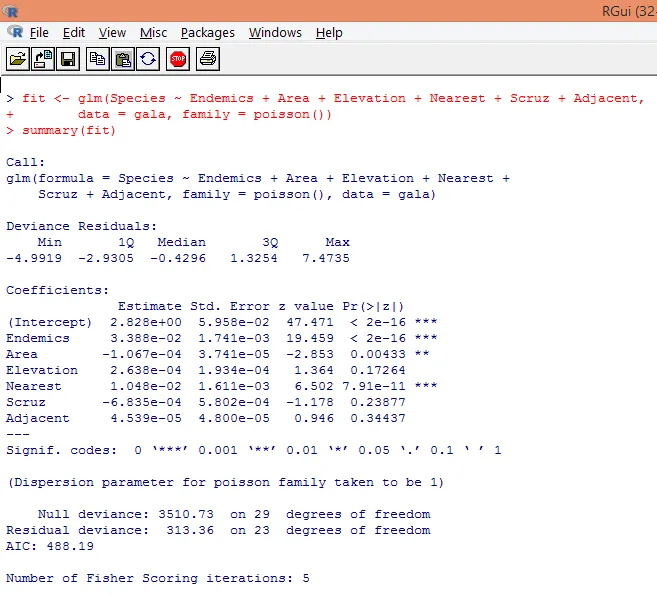
Op basis van de bovenstaande analyse zien we dat de variabelen Endemics, Area en Dichtstbijzijnde significant zijn en alleen hun opname voldoende is om het juiste Poisson-regressiemodel te bouwen.
8. We zullen een gemodificeerd Poisson-regressiemodel bouwen waarbij we alleen rekening houden met drie variabelen. Endemics, Area en Dichtstbijzijnde. Laten we kijken welke resultaten we behalen.
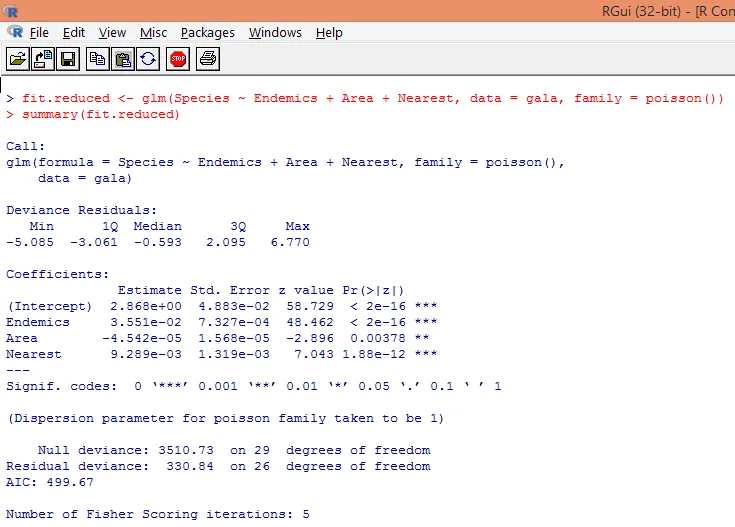
De uitvoer produceert afwijkingen, regressieparameters en standaardfouten. We kunnen zien dat elk van de parameters significant is op p <0, 05 niveau.
9. De volgende stap is het interpreteren van de modelparameters. De modelcoëfficiënten kunnen worden verkregen door Coëfficiënten in de bovenstaande uitvoer te onderzoeken of door de functie coef () te gebruiken.
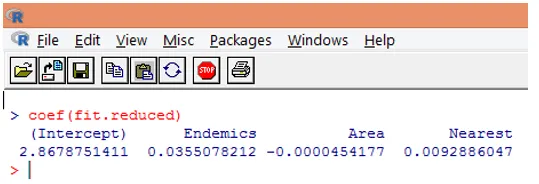
In Poisson-regressie wordt de afhankelijke variabele gemodelleerd als het logboek van de voorwaardelijke gemiddelde loge (l). De regressieparameter van 0.0355 voor Endemics geeft aan dat een toename van één variabele in de variabele is gekoppeld aan een toename van het logische gemiddelde aantal soorten met 0, 04, waarbij andere variabelen constant worden gehouden. Het onderscheppen is een loggemiddeld aantal soorten wanneer elk van de voorspellers gelijk is aan nul.
10. Het is echter veel eenvoudiger om de regressiecoëfficiënten te interpreteren in de oorspronkelijke schaal van de afhankelijke variabele (aantal soorten, in plaats van log aantal soorten). De exponentiatie van de coëfficiënten maakt een eenvoudige interpretatie mogelijk. Dit gebeurt als volgt.
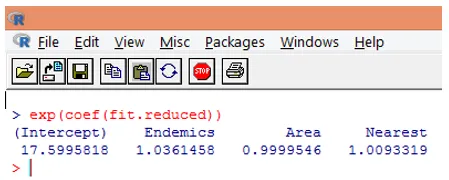
Uit de bovenstaande bevindingen kunnen we zeggen dat een eenheidstoename in Area het verwachte aantal soorten vermenigvuldigt met 0, 99, en een eenheidstoename van het aantal endemische soorten vertegenwoordigd door Endemics vermenigvuldigt het aantal soorten met 1, 0361. Het belangrijkste aspect van Poisson-regressie is dat exponentiële parameters een multiplicatief in plaats van een additief effect hebben op de responsvariabele.
11. Met behulp van de bovenstaande stappen hebben we een Poisson-regressiemodel verkregen voor het voorspellen van het aantal plantensoorten op de Galapagos-eilanden. Het is echter heel belangrijk om te controleren op overdispersie. In Poisson-regressie zijn de variantie en gemiddelden gelijk.
Overdispersie treedt op wanneer de waargenomen variantie van de responsvariabele groter is dan zou worden voorspeld door de Poisson-verdeling. Het analyseren van overdispersie wordt belangrijk omdat dit gebruikelijk is bij telgegevens en dit een negatieve invloed kan hebben op de uiteindelijke resultaten. In R kan overdispersie worden geanalyseerd met behulp van het "qcc" -pakket. De analyse wordt hieronder geïllustreerd.
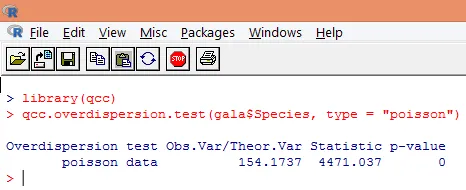
De bovenstaande significante test toont aan dat de p-waarde minder is dan 0, 05, hetgeen sterk de aanwezigheid van overdispersie suggereert. We proberen een model aan te passen met behulp van de functie glm (), door family = "Poisson" te vervangen door family = "quasipoisson". Dit wordt hieronder geïllustreerd.
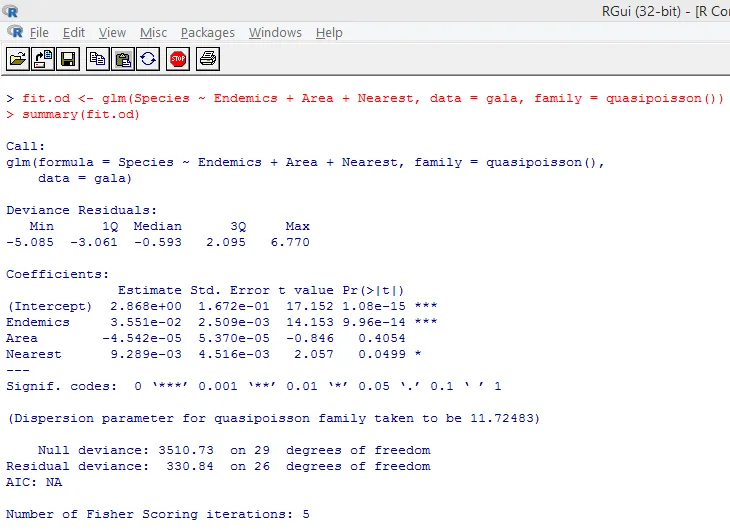
Als we de uitvoer uitvoerig bestuderen, kunnen we zien dat de parameterschattingen in de quasi-Poisson-benadering identiek zijn aan die geproduceerd door de Poisson-benadering, hoewel de standaardfouten verschillend zijn voor beide benaderingen. Bovendien is in dit geval voor Area de p-waarde groter dan 0, 05, wat te wijten is aan een grotere standaardfout.
Het belang van Poisson-regressie
- Poisson-regressie in R is nuttig voor correcte voorspellingen van de discrete / count variabele.
- Het helpt ons die verklarende variabelen te identificeren die een statistisch significant effect hebben op de responsvariabele.
- Poisson-regressie in R is het meest geschikt voor gebeurtenissen van 'zeldzame' aard, omdat ze de neiging hebben een Poisson-verdeling te volgen in tegenstelling tot gewone gebeurtenissen die meestal een normale verdeling volgen.
- Het is geschikt voor toepassing in gevallen waarin de responsvariabele een klein geheel getal is.
- Het heeft brede toepassingen, omdat het voorspellen van discrete variabelen in veel situaties cruciaal is. In de geneeskunde kan het worden gebruikt om de impact van het medicijn op de gezondheid te voorspellen. Het wordt veel gebruikt in overlevingsanalyses zoals de dood van biologische organismen, het falen van mechanische systemen, enz.
Conclusie
Poisson-regressie is gebaseerd op het concept van Poisson-verdeling. Het is een andere categorie die behoort tot de reeks regressietechnieken die de eigenschappen van zowel lineaire als logistieke regressies combineert. In tegenstelling tot Logistische regressie die alleen binaire uitvoer genereert, wordt het echter gebruikt om een discrete variabele te voorspellen.
Aanbevolen artikelen
Dit is een gids voor Poisson Regression in R. Hier bespreken we de introductie Implementatie van Poisson Regression en het belang van Poisson Regression. U kunt ook onze andere voorgestelde artikelen doornemen voor meer informatie–
- GLM in R
- Willekeurige nummergenerator in R
- Regressie Formule
- Logistieke regressie in R
- Lineaire regressie versus logistieke regressie | Topverschillen