
Inleiding tot Hive Architecture
Hive Architecture is gebouwd bovenop het Hadoop-ecosysteem. Hive heeft vaak interacties met de Hadoop. Apache Hive kan het domein SQL-database-systeem en Map-reduce aan. Hive-toepassingen kunnen in verschillende talen worden geschreven, zoals Java, python. Bijenkorfarchitectuur laat zien hoe bijenkorfquerytaal wordt geschreven en hoe de interacties tussen de programmeur worden uitgevoerd met behulp van de opdrachtregelinterface. Hive query-taal doet het werk van het converteren van alle Hadoop-clustertaken door het verminderen van kaarten. Zoals we allemaal wisten dat Hadoop big data in een gedistribueerde omgeving moest verwerken en een open-source framework vormt. Met hive is het flexibel om de query te beheren en uit te voeren en een goede supporter om functies uit te voeren zoals inkapseling, ad-hocquery's. Dit artikel biedt een korte inleiding tot bijenkorfarchitectuur die zich op de Hadoop-laag bevindt om een samenvatting in big data te maken.
Hive Architecture met zijn componenten
Hive speelt een belangrijke rol in data-analyse en business intelligence-integratie en ondersteunt bestandsformaten zoals tekstbestand, rc-bestand. Hive gebruikt een gedistribueerd systeem om query's te verwerken en uit te voeren en de opslag wordt uiteindelijk op de schijf gedaan en uiteindelijk verwerkt met behulp van een map-reduce framework. Het lost het optimalisatieprobleem op dat wordt gevonden onder Map-verkleinen en uitvoeren van batchtaken die duidelijk worden uitgelegd in de workflow. Hier slaat een meta-winkel schema-informatie op. Een framework met de naam Apache Tez is ontworpen voor realtime queryprestaties.
De belangrijkste componenten van de Hive worden hieronder gegeven:
- Hive klanten
- Hive Services
- Hive opslag (Meta opslag)
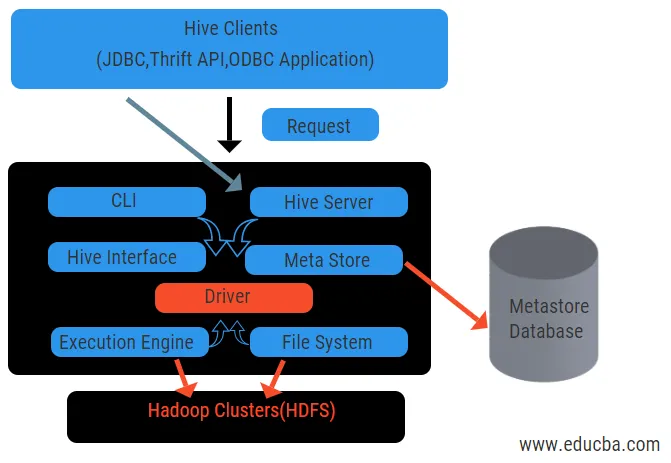
Het bovenstaande diagram toont de architectuur van de component en de samenstellende elementen.
Bijenkorf klanten:
Ze bevatten de Thrift-toepassing om eenvoudige hive-opdrachten uit te voeren die beschikbaar zijn voor python, ruby, C ++ en stuurprogramma's. Deze clienttoepassingsvoordelen voor het uitvoeren van query's op de component. Hive heeft drie soorten clientcategorie: thrift-clients, JDBC- en ODBC-clients.
Hive Services:
Voor het verwerken van alle vragen heeft Hive verschillende services. Alle functies worden gemakkelijk gedefinieerd door de gebruiker in de component. Laten we al deze services in het kort bekijken:
- Opdrachtregelinterface (gebruikersinterface): het maakt interactie mogelijk tussen de gebruiker en de component, een standaardshell. Het biedt een GUI voor het uitvoeren van bijenkorfopdrachtregel en bijenkorfinzicht. We kunnen ook webinterfaces (HWI) gebruiken om de vragen en interacties met een webbrowser in te dienen.
- Hive-stuurprogramma: het ontvangt query's van verschillende bronnen en clients zoals de thrift-server en slaat op en haalt het ODBC- en JDBC-stuurprogramma op dat automatisch met de component wordt verbonden. Deze component voert een semantische analyse uit bij het zien van de tabellen van de metastore die een query parseert. Het stuurprogramma neemt de hulp van de compiler en voert functies uit zoals een parser, Planner, uitvoering van MapReduce-taken en optimizer.
- Compiler: parseren en semantisch proces van de query wordt gedaan door de compiler. Het converteert de zoekopdracht in een abstracte syntax-structuur en opnieuw in DAG voor compatibiliteit. De optimizer splitst op zijn beurt de beschikbare taken. De taak van de uitvoerder is het uitvoeren van de taken en het bewaken van het pijplijnschema van de taken.
- Execution Engine: Alle vragen worden verwerkt door een execution engine. Een DAG-faseplannen worden uitgevoerd door de motor en helpen bij het beheer van de afhankelijkheden tussen de beschikbare fasen en voeren deze uit op een correct onderdeel.
- Metastore: het fungeert als een centrale opslagplaats om alle gestructureerde informatie van metagegevens op te slaan, het is ook een belangrijk aspect voor de component omdat het informatie heeft zoals tabellen en partitiedetails en de opslag van HDFS-bestanden. Met andere woorden, we zullen zeggen dat metastore fungeert als een naamruimte voor tabellen. Metastore wordt beschouwd als een afzonderlijke database die ook door andere componenten wordt gedeeld. Metastore heeft twee delen genaamd service- en achterstandsopslag.
Het bijenkorfgegevensmodel is gestructureerd in partities, emmers, tabellen. Al deze kunnen worden gefilterd, hebben partitiesleutels en om de query te evalueren. Hive query werkt op het Hadoop-framework, niet op de traditionele database. Hive-server is een interface tussen een client op afstand naar de Hive. De uitvoerings-engine is volledig ingebed in een componentenserver. Je zou bijenkorftoepassingen kunnen vinden in machine learning, business intelligence in het detectieproces.
Work Flow of Hive:
Hive werkt in twee soorten modi: interactieve modus en niet-interactieve modus. In de vorige modus kunnen alle bijenkorfopdrachten rechtstreeks naar de bijenkorf gaan, terwijl het latere type code in consolemodus uitvoert. Gegevens worden verdeeld in partities die verder worden opgesplitst in emmers. Uitvoeringsplannen zijn gebaseerd op aggregatie en data skew. Een bijkomend voordeel van het gebruik van component is dat het gemakkelijk een grote schaal van informatie kan verwerken en meer gebruikersinterfaces heeft.
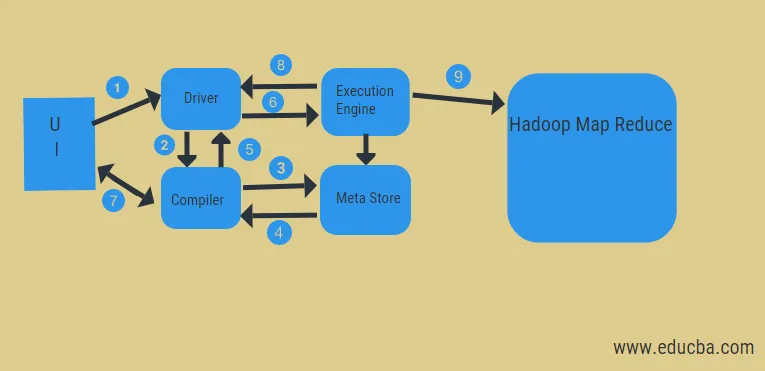
Uit het bovenstaande diagram kunnen we een glimp opvangen van de gegevensstroom in de component met het Hadoop-systeem.
De stappen omvatten:
- voer de Query uit vanuit de UI
- krijg een plan van de DAG-fasen van de chauffeurstaken
- haal metadata-verzoek op bij de meta store
- verzend metadata van de compiler
- het plan terugsturen naar de bestuurder
- Plan uitvoeren in de uitvoeringsmotor
- resultaten ophalen voor de juiste gebruikersquery
- resultaten bidirectioneel verzenden
- uitvoering engine-verwerking in HDFS met de map-verkleinen en ophalen van resultaten van de dataknooppunten gecreëerd door de job-tracker. het fungeert als een connector tussen Hive en Hadoop.
De taak van de uitvoeringsmotor is om met knooppunten te communiceren om de informatie in de tabel te bewaren. Hier worden SQL-bewerkingen zoals create, drop, alter uitgevoerd om toegang te krijgen tot de tabel.
Conclusie:
We hebben Hive Architecture en hun werkstroom doorlopen, hive voert feitelijk een hoeveelheid gegevens uit petabyte uit en daarom is het een datawarehouse-pakket op het Hadoop-platform. Omdat bijenkorf een goede keuze is voor het verwerken van een hoog datavolume, helpt het bij het voorbereiden van gegevens met de gids van SQL-interface om de MapReduce-problemen op te lossen. Apache hive is een ETL-tool om gestructureerde gegevens te verwerken. Het kennen van de werking van de bijenkorfarchitectuur helpt mensen uit het bedrijfsleven om de principiële werking van de bijenkorf te begrijpen en heeft een goede start met bijenkorfprogrammering.
Aanbevolen artikelen:
Dit is een gids voor Hive Architecture geweest. Hier bespreken we de componentarchitectuur, verschillende componenten en workflow van de component. u kunt ook de volgende artikelen bekijken voor meer informatie-
- Hadoop-architectuur
- Gebruik van Ruby
- Wat is C ++
- Wat is MySQL-database
- Bijenkorf sorteren op