
Inleiding tot begeleid leren
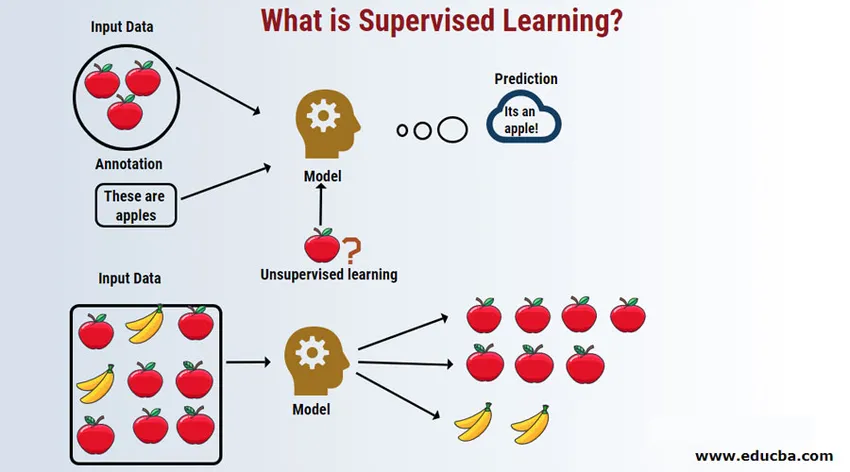
Supervised Learning is een gebied van machine learning waar we werken aan het voorspellen van de waarden met behulp van gelabelde gegevenssets. De gelabelde invoergegevenssets worden de onafhankelijke variabele genoemd, terwijl de voorspelde resultaten de afhankelijke variabele worden genoemd omdat ze voor hun resultaten afhankelijk zijn van de onafhankelijke variabele. We hebben bijvoorbeeld allemaal een spammap in ons e-mailaccount (bijvoorbeeld voor Gmail) die automatisch de meeste spam- / fraude-e-mails voor u detecteert met een nauwkeurigheid van meer dan 95%. Het werkt op basis van een begeleid leermodel waarbij we een trainingsset met gelabelde gegevens hebben, in dit geval gelabelde spam-e-mail gemarkeerd door gebruikers. Deze trainingssets worden gebruikt om te leren, die later zullen worden gebruikt voor het categoriseren van nieuwe e-mails als spam als deze in de categorie passen.
Werken aan Supervised Machine Learning
Laten we aan de hand van een voorbeeld toezicht houden op machinaal leren. Laten we zeggen dat we een fruitmand hebben die gevuld is met verschillende soorten fruit. Het is onze taak om fruit te categoriseren op basis van hun categorie.
In ons geval hebben we vier soorten fruit overwogen en dat zijn Apple, Banaan, Druiven en Sinaasappels.
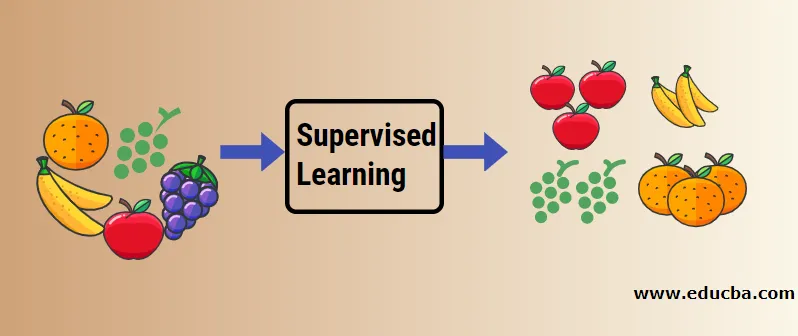
Nu zullen we proberen enkele van de unieke kenmerken van deze vruchten te noemen die ze uniek maken.
|
S Nee. | Grootte | Kleur | Vorm |
Voornaam |
|
1 | Klein | Groen | Rond tot ovaal, bosvorm cilindrisch |
Druif |
|
2 | Groot | Rood | Afgeronde vorm met een verdieping aan de bovenkant |
appel |
|
3 | Groot | Geel | Lange gebogen cilinder |
Banaan |
| 4 | Groot | Oranje | Afgeronde vorm |
Oranje |
Laten we nu zeggen dat je een fruit uit de fruitmand hebt geplukt, je hebt gekeken naar de kenmerken ervan, bijvoorbeeld de vorm, de grootte en de kleur, en dan concludeer je dat de kleur van deze vrucht rood is, de maat als groot, de vorm is afgerond met een holte bovenaan, vandaar dat het een appel is.
- Op dezelfde manier doe je hetzelfde voor alle andere overgebleven vruchten.
- De meest rechtse kolom ('Fruitnaam') staat bekend als de responsvariabele.
- Dit is de manier waarop we een begeleid leermodel formuleren, nu is het voor iedereen die nieuw is (laten we zeggen een robot of een alien) met bepaalde eigenschappen gemakkelijk om eenvoudig hetzelfde soort fruit te groeperen.
Soorten onder toezicht gehouden machinealgoritme
Laten we verschillende soorten machine learning-algoritmen bekijken:
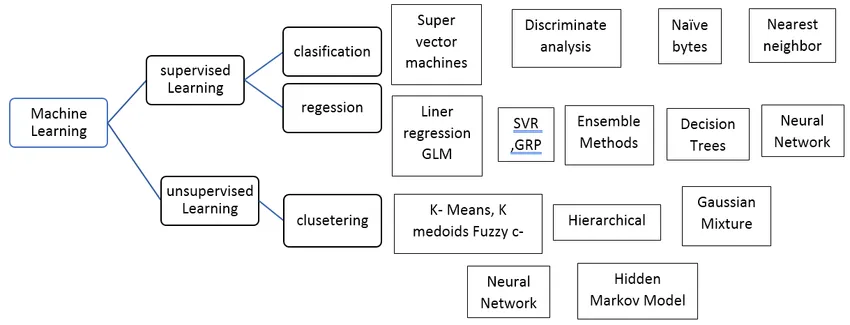
regressie:
Regressie wordt gebruikt om een enkele waarde-uitvoer te voorspellen met behulp van de trainingsdataset. De uitgangswaarde wordt altijd de afhankelijke variabele genoemd, terwijl de ingangen de onafhankelijke variabele worden genoemd. We hebben verschillende soorten regressie in Supervised Learning, bijvoorbeeld,
- Lineaire regressie - hier hebben we slechts één onafhankelijke variabele die wordt gebruikt voor het voorspellen van de output, dwz afhankelijke variabele.
- Meerdere regressie - hier hebben we meer dan één onafhankelijke variabele die wordt gebruikt voor het voorspellen van de output, dwz de afhankelijke variabele.
- Polynoomregressie - Hier volgt de grafiek tussen de afhankelijke en onafhankelijke variabelen een polynoomfunctie. Want bijvoorbeeld, eerst neemt het geheugen toe met de leeftijd, dan bereikt het een drempel op een bepaalde leeftijd, en dan begint het af te nemen naarmate we oud worden.
Classificatie:
De classificatie van begeleide leeralgoritmen wordt gebruikt om vergelijkbare objecten in unieke klassen te groeperen.
- Binaire classificatie - Als het algoritme 2 verschillende groepen klassen probeert te groeperen, wordt het binaire classificatie genoemd.
- Classificatie van meerdere klassen - Als het algoritme objecten in meer dan 2 groepen probeert te groeperen, wordt het classificatie van meerdere klassen genoemd.
- Sterkte - Classificatie-algoritmen presteren meestal erg goed.
- Nadelen - Gevoelig voor overfitting en mogelijk ongedwongen. Bijvoorbeeld - Email Spam classifier
- Logistische regressie / classificatie - Wanneer de Y-variabele een binaire categorie is (bijv. 0 of 1), gebruiken we Logistische regressie voor de voorspelling. Bijvoorbeeld - Voorspellen of een bepaalde creditcardtransactie fraude is of niet.
- Naïve Bayes Classifiers - De Naïve Bayes classifier is gebaseerd op de Bayesiaanse stelling. Dit algoritme is meestal het meest geschikt wanneer de dimensionaliteit van de ingangen hoog is. Het bestaat uit acyclische grafieken met één ouder en veel kinderknooppunten. De kindknopen zijn onafhankelijk van elkaar.
- Beslisbomen - Een beslissingsboom is een boomdiagramachtige structuur die bestaat uit een interne knoop (test op kenmerk), tak die de uitkomst van de test aangeeft en de bladknopen die de verdeling van klassen vertegenwoordigen. Het root-knooppunt is het bovenste knooppunt. Het is een veel gebruikte techniek die wordt gebruikt voor classificatie.
- Support Vector Machine - Een support vector machine is of een SVM doet het werk van classificatie door het hyperplane te vinden dat de marge tussen 2 klassen zou moeten maximaliseren. Deze SVM-machines zijn verbonden met de kernelfuncties. Velden, waar SVM's op grote schaal worden gebruikt, zijn biometrie, patroonherkenning, etc.
voordelen
Hieronder staan enkele voordelen van modellen voor machinaal leren onder toezicht:
- De prestaties van modellen kunnen worden geoptimaliseerd door de gebruikerservaringen.
- Begeleid leren levert resultaten op met eerdere ervaringen en stelt u ook in staat om gegevens te verzamelen.
- Supervised machine learning-algoritmen kunnen worden gebruikt voor het implementeren van een aantal echte problemen.
nadelen
Nadelen van Supervised Learning zijn als volgt:
- De inspanning om modellen voor machinaal leren onder toezicht te trainen, kan veel tijd kosten als de gegevensset groter is.
- De classificatie van big data vormt soms een grotere uitdaging.
- Men kan te maken krijgen met de problemen van overfitting.
- We hebben veel goede voorbeelden nodig als we willen dat het model goed presteert terwijl we de classifier trainen.
Goede praktijken bij het bouwen van leermodellen
Het is een goede gewoonte om een Supervised Learning Machine-modellen te bouwen: -
- Voordat een goed machine learning-model wordt gebouwd, moet het proces van voorverwerking van gegevens worden uitgevoerd.
- Men moet beslissen welk algoritme het meest geschikt is voor een bepaald probleem.
- We moeten beslissen welk type gegevens zal worden gebruikt voor de trainingsset.
- Moet beslissen over de structuur van het algoritme en de functie.
Conclusie
In ons artikel hebben we geleerd wat begeleid leren is en we zagen dat we hier het model trainen met behulp van gelabelde gegevens. Daarna gingen we in op de werking van de modellen en hun verschillende typen. We zagen eindelijk de voor- en nadelen van deze bewaakte machine learning-algoritmen.
Aanbevolen artikelen
Dit is een handleiding voor wat Supervised Learning is. Hier bespreken we de concepten, hoe het werkt, types, voor- en nadelen van Supervised Learning. U kunt ook onze andere voorgestelde artikelen doornemen voor meer informatie -
- Wat is diep leren
- Begeleid leren versus diep leren
- Wat is synchronisatie in Java?
- Wat is webhosting?
- Manieren om beslissingsboom met voordelen te creëren
- Polynomiale regressie | Gebruik en functies