
Verschil tussen machinaal leren en voorspellende analyses
Machinaal leren is een gebied in de informatica, dat tegenwoordig steeds groter wordt. Recente vooruitgang in hardwaretechnologieën die resulteerde in een enorme toename van rekenkracht zoals GPU (grafische verwerkingseenheden) en vooruitgang in neurale netwerken, machine learning is een modewoord geworden. In wezen kunnen we met behulp van machine learning-technieken algoritmen bouwen om gegevens te extraheren en er belangrijke verborgen informatie uit te zien. Voorspellende analyses maken ook deel uit van het machine learning-domein dat beperkt is om de toekomstige resultaten van gegevens op basis van eerdere patronen te voorspellen. Hoewel voorspellende analyses al meer dan twee decennia worden gebruikt, voornamelijk in de bank- en financiële sector, heeft de toepassing van machine learning de laatste tijd een prominente plaats ingenomen met algoritmen zoals objectdetectie van afbeeldingen, tekstclassificatie en aanbevelingssystemen.
Machine leren
Machine learning gebruikt intern statistieken, wiskunde en informatica om logica te bouwen voor algoritmen die classificatie, voorspelling en optimalisatie kunnen uitvoeren, zowel in realtime als in batchmodus. Classificatie en regressie zijn twee hoofdklassen van een probleem bij machinaal leren. Laten we zowel Machine Learning als Predictive Analytics in detail begrijpen.
Classificatie
Onder deze emmers van een probleem, hebben we de neiging om een object op basis van de verschillende eigenschappen in een of meer klassen in te delen. Bijvoorbeeld, het classificeren van een bankklant om in aanmerking te komen voor een woningkrediet of niet op basis van zijn / haar kredietgeschiedenis. Meestal hebben we transactiegegevens beschikbaar voor de klant, zoals zijn leeftijd, inkomen, opleidingsachtergrond, zijn werkervaring, branche waarin hij werkt, aantal personen ten laste, maandelijkse uitgaven, eventuele eerdere leningen, zijn uitgavenpatroon, kredietgeschiedenis, enz. en op basis van deze informatie zouden we de neiging hebben om te berekenen of hij een lening moet krijgen of niet.
Er zijn veel standaard machine learning-algoritmen die worden gebruikt om het classificatieprobleem op te lossen. Logistieke regressie is zo'n methode, waarschijnlijk de meest gebruikte en meest bekende, ook de oudste. Afgezien daarvan hebben we ook enkele van de meest geavanceerde en gecompliceerde modellen, variërend van beslissingsboom tot random forest, AdaBoost, XP boost, ondersteuning van vectormachines, naïef baize en neuraal netwerk. Sinds de laatste jaren loopt diep leren voorop. Doorgaans worden neuraal netwerk en diep leren gebruikt om afbeeldingen te classificeren. Als er honderdduizend afbeeldingen van katten en honden zijn en u wilt een code schrijven die automatisch afbeeldingen van katten en honden kan scheiden, wilt u misschien voor diepgaande leermethoden zoals een convolutioneel neuraal netwerk. Torch, cafe, sensor flow, etc. zijn enkele van de populaire bibliotheken in python om diep te leren.
Om de nauwkeurigheid van regressiemodellen te meten, worden metrieken zoals fout-positieve snelheid, fout-negatieve snelheid, gevoeligheid, enz. Gebruikt.
regressie
Regressie is een andere klasse problemen in machine learning, waarbij we proberen de continue waarde van een variabele te voorspellen in plaats van een klasse, anders dan bij classificatieproblemen. Regressietechnieken worden meestal gebruikt om de aandelenkoers van een aandeel, verkoopprijs van een huis of auto, een vraag naar een bepaald item, enz. Te voorspellen. Wanneer eigenschappen uit de tijdreeks ook een rol spelen, worden regressieproblemen zeer interessant om op te lossen. Lineaire regressie met gewoon kleinste kwadraat is een van de klassieke algoritmen voor machine learning in dit domein. Voor op tijdreeksen gebaseerd patroon worden ARIMA, exponentieel voortschrijdend gemiddelde, gewogen voortschrijdend gemiddelde en eenvoudig voortschrijdend gemiddelde gebruikt.
Om de nauwkeurigheid van regressiemodellen te meten, worden metrieken zoals kwadratische fout, absoluut gemiddelde kwadratische fout, wortelmaat kwadratische fout, etc. gebruikt.
Voorspellende analyse
Er zijn enkele overlappingsgebieden tussen machine learning en voorspellende analyse. Terwijl gebruikelijke technieken zoals logistieke en lineaire regressie zowel onder machine learning als voorspellende analyse vallen, zijn geavanceerde algoritmen zoals een beslissingsboom, random forest, etc. in wezen machine learning. Bij voorspellende analyses blijft het doel van de problemen zeer beperkt, waarbij het de bedoeling is om de waarde van een bepaalde variabele op een later tijdstip te berekenen. Voorspellende analyses bevatten veel statistieken, terwijl machine learning meer een combinatie is van statistieken, programmeren en wiskunde. Een typische voorspellende analist besteedt zijn tijd aan het berekenen van t kwadraat, f statistiek, Innova, chikwadraat of gewoon kleinste kwadraat. Vragen als of de gegevens normaal worden gedistribueerd of scheef, als de t-verdeling van de student wordt gebruikt of de klokkencurve worden gebruikt, moet alfa altijd worden genomen met 5% of 10%. Ze zoeken de duivel in details. Een machine learning engineer houdt zich niet bezig met veel van deze problemen. Hun hoofdpijn is compleet anders, ze zitten vast aan nauwkeurigheidsverbetering, fout-positieve snelheidsminimalisatie, uitbijterbehandeling, bereiknormalisatie of k-voudige validatie.
Een voorspellende analist gebruikt meestal tools zoals excel. Scenario of doel zoeken zijn hun favoriet. Ze gebruiken af en toe VBA of micro's en schrijven nauwelijks lange code. Een machine learning engineer besteedt al zijn tijd aan het schrijven van gecompliceerde code buiten het normale begrip, hij gebruikt tools zoals R, Python, Saas. Programmeren is hun belangrijkste werk, het oplossen van bugs en het testen van de verschillende landschappen in een dagelijkse routine.
Deze verschillen brengen ook een groot verschil in vraag en salaris met zich mee. Terwijl voorspellende analisten dat gisteren zijn, is machine learning de toekomst. Een typische machineleertechnicus of datawetenschapper (zoals tegenwoordig meestal wordt genoemd) wordt 60-80% meer betaald dan een typische software-ingenieur of een voorspellende analist en ze zijn de belangrijkste drijfveer in de wereld van de technologie die vandaag de dag mogelijk is. Uber, Amazon en nu zelfrijdende auto's zijn ook alleen vanwege hen mogelijk.
Head to Head-vergelijking tussen machine learning versus voorspellende analyses (infographics)
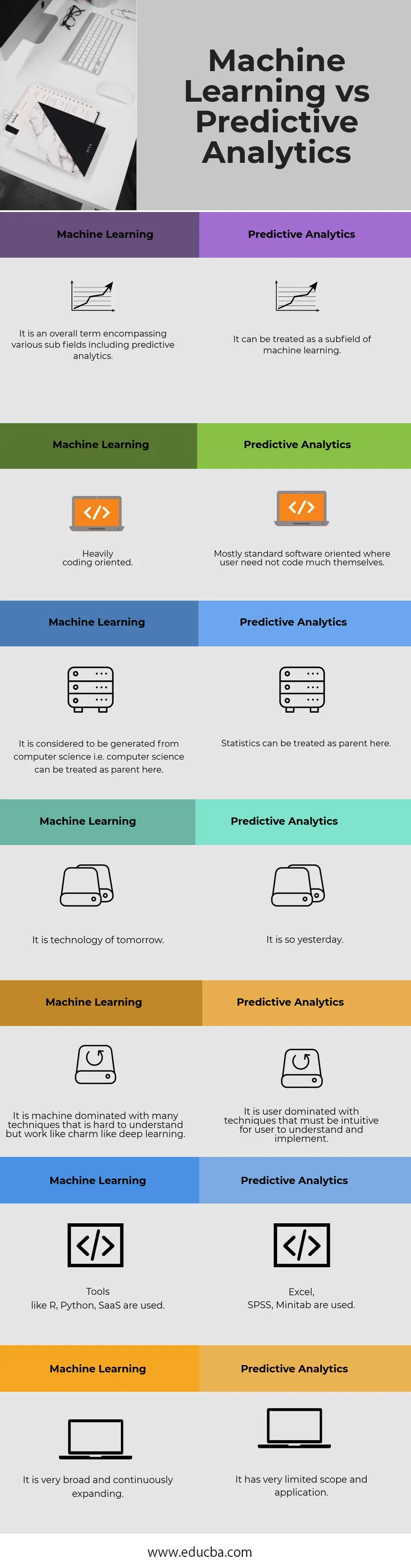
Hieronder staat de top 7 vergelijking tussen machinaal leren en voorspellende analyses
Machine Learning versus Predictive Analytics-vergelijkingstabel
Hieronder vindt u de gedetailleerde uitleg over Machine Learning versus Predictive Analytics
| Machine leren | Voorspellende analyse |
| Het is een algemene term die verschillende subvelden omvat, waaronder voorspellende analyses. | Het kan worden behandeld als een deelgebied van machine learning. |
| Sterk codeergericht. | Meestal standaard software georiënteerd waarbij een gebruiker niet veel zelf hoeft te coderen |
| Het wordt verondersteld te zijn gegenereerd door informatica, dwz dat informatica hier als de ouder kan worden behandeld. | Statistieken kunnen hier als een ouder worden behandeld. |
| Het is de technologie van morgen. | Het is zo gisteren. |
| Het is een machine die wordt gedomineerd door vele technieken die moeilijk te begrijpen zijn, maar werken als charme zoals diep leren. | Het wordt gedomineerd door de gebruiker met technieken die intuïtief moeten zijn voor een gebruiker om te begrijpen en te implementeren. |
| Tools zoals R, Python, SaaS worden gebruikt. | Excel, SPSS, Minitab worden gebruikt. |
| Het is zeer breed en wordt voortdurend uitgebreid. | Het heeft een zeer beperkte reikwijdte en toepassing. |
Conclusie - Machine Learning versus Predictive Analytics
Uit de bovenstaande discussie over zowel Machine Learning als Predictive Analytics, is het duidelijk dat voorspellende analyse in feite een subveld van machine learning is. Machine learning is veelzijdiger en kan een breed scala aan problemen oplossen.
Aanbevolen artikel
Dit is een leidraad geweest voor Machine Learning versus Predictive Analytics, hun betekenis, Head to Head Comparison, Key Differences, Comparision Table en Conclusie. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Leer Big Data versus machine learning
- Verschil tussen data science versus machine learning
- Vergelijking tussen voorspellende analyses en gegevenswetenschap
- Data Analytics versus Predictive Analytics - Welke is nuttig