

Inleiding tot XPath
XPath is een primair en kerncomponent van de XSLT-standaard. XPath kan worden gebruikt om de elementen, attributen, tekst, verwerkingsinstructie, commentaar, naamruimte en document te doorlopen in een XML-document (Extensible Markup Language). Het is een W3C-aanbeveling die een bibliotheek bevat met meer dan 200 ingebouwde functies. XPath is de syntaxis voor het definiëren van delen van een XML-document. XSLT is de stijlbladtaal voor XML-bestanden. Met XSLT kunt u XML-documenten omzetten in andere formaten, zoals XHTML. XQuery gaat over het opvragen van XML-gegevens. XQuery is ontworpen om alles op te vragen dat als XML kan verschijnen, inclusief databases. Koppeling in XML is verdeeld in twee delen: XLink en XPointer. XLink en XPointer definiëren een standaardmanier om hyperlinks in XML-documenten te maken.
Expressie van XPath
Met XPath kunnen verschillende soorten expressies relevante informatie uit het XML-document ophalen. XPath richt zich op een specifiek deel van het document. Het modelleert een XML-document als een boom met knooppunten. Een uitdrukking van XPath is een techniek voor het navigeren door en selecteren van knooppunten in het document.
XPath-expressies kunnen worden gebruikt in C, C ++, Python, Java, JavaScript, PHP, XML Schema en vele andere talen. Een XPath-expressie verwijst naar een patroon om een set knooppunten te selecteren. XPointer gebruikt deze patronen voor het adresseren van doel of voor het uitvoeren van transformaties door XSLT. De XPath-expressie geeft zeven typen knooppunten aan die het gevolg kunnen zijn van uitvoering.
1. Root
Root-element van een XML-document. Op de volgende manieren kunnen root-elementen worden gevonden.
- Gebruik jokerteken (/ *): om het hoofdknooppunt te selecteren
- Gebruik naam (/ klasse): om het hoofdknooppunt op naam te selecteren
- Gebruik naam met een jokerteken (/ class / *): om alle elementen onder het hoofdknooppunt te selecteren
Code:
2. Element
Elementknooppunt van een XML-document. Hieronder staan de manieren om elementen te vinden
- / class / *: wordt gebruikt om alle elementen onder het hoofdknooppunt te selecteren.
- / class / library: wordt gebruikt om alle bibliotheekelementen uit het hoofdknooppunt te selecteren.
- // bibliotheek: wordt gebruikt om het volledige bibliotheekelement uit het document te selecteren.
Code:
3. Attributen
Een kenmerk van een elementknooppunt in het XML-document opgehaald en gecontroleerd met behulp van de @ attribuutnaam van een element.
Code:
4. Tekst
Tekst van een elementknooppunt in het XML-document, opgehaald en gecontroleerd op naam van een element.
Code:
5. Commentaar
Voorbeeld van commentaar
Code:
Knooppunt of lijst van het knooppunt van XML
Hieronder volgt de lijst met nuttige uitdrukkingen om een knooppunt of een lijst van het knooppunt uit een XML-document te selecteren.
- '/': Gebruik deze selectie vanaf het hoofdknooppunt.
- '//': het gebruik van deze selectie begint bij het huidige knooppunt dat overeenkomt met de selectie
- '.': Om deze gebruikte uitdrukking te selecteren.
- '..': om het bovenliggende knooppunt van het huidige knooppunt te selecteren.
- '@': Om attributen te selecteren.
Voorbeeld van XPath
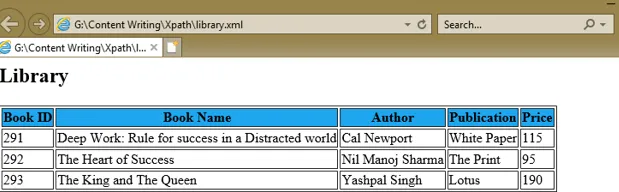
Om een XPath-expressie te begrijpen, hebben we een XML-document, library.xml en het stylesheet-document library.xsl gemaakt dat de XPath-expressies gebruikt onder het select attribuut van verschillende XSL-tags om de waarden van boek-id, boeknaam, auteur, publicatie en prijs van elk boekknooppunt.
1. library.xml
Code:
Deep Work: Rule for success in a Distracted world
Cal Newport
White Paper
115
The Heart of Success
Nil Manoj Sharma
The Print
95
The King and The Queen
Yashpal Singh
Lotus
190
2. library.xsl
Code:
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
| | | | |
|---|---|---|---|---|
xmlns:xsl = "http://www.w3.org/1999/XSL/Transform">
Library
Book ID
Book Name
Author
Publication
Price
Output:
Voordelen van XPath
Hieronder staan de voordelen van Xpath:
- XPath-zoekopdrachten zijn eenvoudig te typen en te lezen en zijn ook compact.
- XPath-syntaxis is eenvoudig voor de gewone en eenvoudige gevallen.
- De queryreeksen zijn eenvoudig ingebed in scripts, programma's en HTML- of XML-attributen.
- De XPath-zoekopdrachten kunnen eenvoudig worden geanalyseerd.
- Elk knooppunt kan uniek herkennen in een XML-document.
- In een XML-document kan het voorkomen van elk pad of elke set voorwaarden voor de knooppunten in het pad worden opgegeven.
- Query's retourneren een willekeurig aantal resultaten, inclusief nul.
- In een XML-document kunnen queryvoorwaarden op elk niveau worden berekend en worden niet verondersteld door het bovenste knooppunt van een XML-document te gaan.
- De XPath-query's retourneren unieke knooppunten, geen herhaalde knooppunten.
- In veel contexten wordt XPath gebruikt om koppelingen naar knooppunten te bieden, voor het vinden van opslagplaatsen en vele andere toepassingen.
- Voor de programmeurs zijn XPath-vragen niet procedureel, maar meer verklarend. Ze bepalen hoe elementen moeten worden doorlopen. Voor efficiënte resultaten moeten indexen en andere structuren gratis worden gebruikt door een query-optimizer.
Conclusie
XPath is een zoektaal die wordt gebruikt om elementen, attributen en tekst door een XML-document te verplaatsen. XPath wordt veel gebruikt om bepaalde elementen of attributen met overeenkomende patronen te vinden. Wanneer een query is gedefinieerd, kunnen die XML-gegevens worden weergegeven als een boomstructuur. De hiërarchische weergave van XML-gegevens wordt een boom genoemd. De bovenkant van de boom is een wortelknoop. In een boom komt elk kenmerk, elementen, tekst, opmerkingen, tekenreeks en verwerkingsinstructie overeen met één knooppunt. De relaties tussen de knooppunten kunnen worden weergegeven door de boom.
Aanbevolen artikelen
Dit is een gids voor Wat is XPath ?. Hier bespreken we uitdrukking, lijst, voorbeelden en voordelen van Xpath. U kunt ook onze andere gerelateerde artikelen doornemen voor meer informatie-
- Wat is XPath in Selenium?
- Wat is XML?
- Nieuw carrièrepad
- Carrièrepad voor informatiebeveiliging
- Voorbeelden van ingebouwde Python-functies