
Introductie tot Data Science
Data Science is een van de snelstgroeiende, uitdagende en goedbetaalde banen van dit decennium. Dus de vraag is wat is data science? data science is een interdisciplinair veld (het bestaat uit meer dan één studietak) dat statistieken, informatica en machine learning-algoritmen gebruikt om inzichten te verkrijgen uit zowel gestructureerde als ongestructureerde data. Volgens 'Economic Times' heeft India de vraag naar datawetenschappelijke professionals in verschillende industriële sectoren met meer dan 400 procent zien groeien op een moment dat het aanbod van dergelijk talent getuige is van een trage groei.
Hoofdcomponenten van Data Science
De belangrijkste componenten of processen die worden gevolgd in de inleiding tot Data Science zijn de volgende:
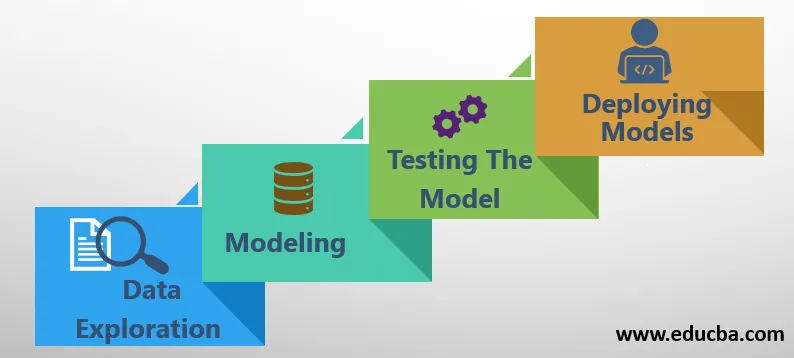
1. Gegevensverkenning
Het is de belangrijkste stap omdat deze stap de meeste tijd kost. Ongeveer 70 procent van de tijd wordt besteed aan data-exploratie. Het hoofdingrediënt voor data science is data, dus als we data krijgen, is het zelden dat data in een correcte gestructureerde vorm is. Er is veel ruis aanwezig in de gegevens. Ruis betekent hier veel ongewenste gegevens die niet vereist zijn. Dus wat doen we in deze stap? Deze stap omvat bemonstering en transformatie van gegevens waarbij we de waarnemingen (rijen) en kenmerken (kolommen) controleren en de ruis verwijderen met behulp van statistische methoden. Deze stap wordt ook gebruikt om de relatie tussen verschillende functies (kolommen) in de gegevensset te controleren, met de relatie bedoelen we of de functies (kolommen) van elkaar afhankelijk zijn of onafhankelijk van elkaar, of er waarden ontbreken in de gegevens of niet. Dus in feite worden de gegevens getransformeerd en gereedgemaakt voor verder gebruik. Daarom is dit een van de meest tijdrovende stappen.
2. Modelleren
Dus nu zijn onze gegevens gereed en klaar voor gebruik. Dit is de tweede stap waarbij we eigenlijk Machine Learning-algoritmen gebruiken. Hier passen we de gegevens eigenlijk in het model. De selectie van een model is afhankelijk van het type gegevens dat we hebben en de zakelijke vereiste. De modelselectie voor het aanbevelen van een artikel aan een klant is bijvoorbeeld anders dan het model dat nodig is om het aantal artikelen te voorspellen dat op een bepaalde dag zal worden verkocht. Zodra het model is bepaald, passen we de gegevens in het model.
3. Het model testen
Het is de volgende stap en erg belangrijk met betrekking tot de prestaties van het model. Het model wordt getest met testgegevens om de nauwkeurigheid en andere kenmerken van het model te controleren en de vereiste wijzigingen in het model aan te brengen om het gewenste resultaat te krijgen. Als we niet de gewenste nauwkeurigheid krijgen, kunnen we opnieuw naar stap 2 (modellering) gaan, een ander model selecteren en dan dezelfde stap 3 herhalen en het model kiezen dat het beste resultaat volgens de zakelijke vereiste geeft.
4. Modellen implementeren
Zodra we het gewenste resultaat hebben bereikt door een goede test volgens de bedrijfsvereisten, voltooien we het model dat ons het beste resultaat geeft volgens de testresultaten en implementeren we het model in de productieomgeving.
Kenmerken van Data Science
De kenmerken van een datawetenschapper zijn als volgt:
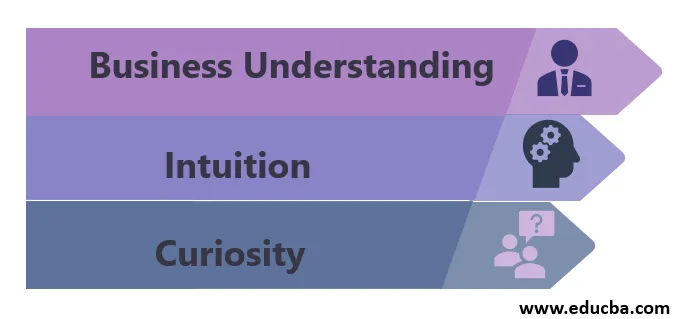
1. Zakelijk begrip
Het is het belangrijkste kenmerk, want tenzij u de business begrijpt, kunt u geen goed model maken, zelfs als u een goede kennis heeft van algoritmen voor machine learning of statistische vaardigheden. Een gegevenswetenschapper moet de bedrijfsvereisten begrijpen en analyses ontwikkelen op basis daarvan. Domeinkennis van het bedrijf wordt dus ook belangrijk of nuttig.
2. Intuïtie
Hoewel de betrokken wiskunde bewezen en fundamenteel is, moet een datawetenschapper het juiste model kiezen met de juiste nauwkeurigheid. Omdat niet alle modellen exact dezelfde resultaten zullen geven. Een datawetenschapper moet dus voelen wanneer een model klaar is voor productie-implementatie. Ze hebben ook de intuïtie nodig om te weten op welk moment het productiemodel oud is en refactoring nodig heeft om te reageren op veranderende bedrijfsomgeving.
3. Nieuwsgierigheid
Data Science is geen nieuw veld. Het is er ook al eerder geweest, maar de vooruitgang die op dit gebied wordt geboekt, is erg snel en er worden voortdurend nieuwe methoden ontwikkeld om bekende problemen op te lossen, omdat nieuwsgierigheid van gegevenswetenschappers om opkomende technologieën te leren erg belangrijk wordt.
toepassingen
Hier in de inleiding tot data science hebben we over de toepassingen van data science duidelijk gemaakt dat het enorm is. Het is vereist in elk veld. Hier zijn voorbeelden van enkele sectoren waar data science kan worden gebruikt of actief wordt gebruikt.
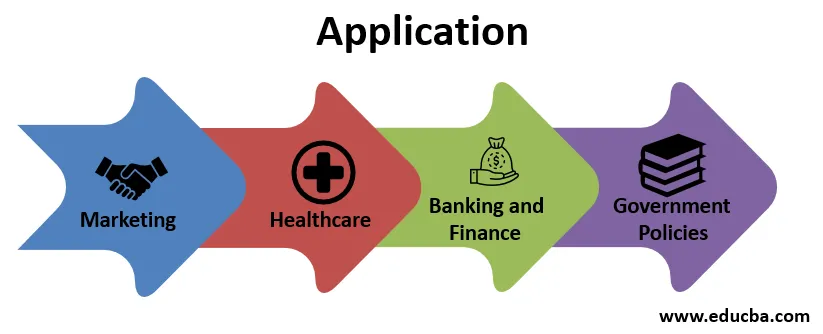
1. Marketing
Er is een enorme reikwijdte in marketing, bijvoorbeeld Verbeterde prijsstrategie Bedrijven zoals Uber, e-commercebedrijven kunnen data science-driven prijzen gebruiken waarmee ze hun winst kunnen verhogen.
2. Gezondheidszorg
Wearable data gebruiken om gezondheidsproblemen te voorkomen en te monitoren. De gegevens die door het lichaam worden gegenereerd, kunnen in de gezondheidszorg worden gebruikt om toekomstige noodsituaties te voorkomen.
3. Bank- en Financiewezen
Zoals we de introductie van data science nu hebben besproken, zullen we doorgaan met de toepassing van data science-toepassingen in de banksector voor fraudedetectie, wat kan helpen bij het verminderen van de niet-uitvoerende activa van banken.
4. Overheidsbeleid
De overheid kan gegevenswetenschap gebruiken om beter beleid voor te bereiden om beter in te spelen op de behoeften van de mensen en wat ze willen met behulp van de gegevens die ze kunnen verkrijgen door enquêtes en andere uit andere officiële bronnen te houden.
Voor- en nadelen van Data Science
Na alle componenten, kenmerken en de brede inleiding tot Data Science te hebben doorlopen, gaan we de voor- en nadelen van Data Science onderzoeken:
voordelen
In dit onderwerp van Inleiding tot Data Science laten we u ook de voordelen van Data Science zien. Sommigen van hen zijn als volgt:
- Het helpt ons om inzichten te verkrijgen uit de historische gegevens met zijn krachtige tools.
- Het helpt het bedrijf te optimaliseren, de juiste personen in te huren en meer inkomsten te genereren, omdat het gebruik van data science u helpt om betere toekomstige beslissingen voor het bedrijf te nemen.
- Bedrijven kunnen hun producten beter ontwikkelen en op de markt brengen, omdat ze hun doelklanten beter kunnen selecteren.
- Inleiding tot Data Science helpt consumenten ook bij het zoeken naar betere goederen, vooral in e-commerce sites op basis van het gegevensgestuurde aanbevelingssysteem.
nadelen
Terwijl we de introductie van data science nu bestudeerden, gaan we verder met de nadelen van data science:
De nadelen zijn over het algemeen wanneer data science wordt gebruikt voor klantprofilering en inbreuk op de privacy van klanten, aangezien hun informatie, zoals transacties, aankopen en abonnementen, zichtbaar is voor hun moederbedrijven. De informatie verkregen met behulp van data science kan worden gebruikt tegen een bepaalde groep, persoon, land of gemeenschap.
Aanbevolen artikelen
Dit is een handleiding geweest voor Inleiding tot Data Science. Hier hebben we de introductie tot data science besproken met de belangrijkste componenten en kenmerken van de introductie tot data science. U kunt ook de volgende artikelen bekijken:
- Data Science versus Data Visualization
- Sollicitatievragen voor Data Science
- Data Science versus Data Analytics
- Voorspellende analyse versus gegevenswetenschap
- Data Science Algorithms | Types