

Data Supply Chain
Gegevens zijn de grootste troef van een bedrijf geworden. Hoe groter de gegevens, hoe complexer het wordt om ermee om te gaan. Het wordt een grotere uitdaging om de gegevens te beheren en te analyseren en wenselijk zakelijk inzicht te verkrijgen uit de gegevens. Het hoofddoel is om de zakenmensen in staat te stellen betere beslissingen te nemen op basis van de analyse van enorme datasets.
Als de gegevensstroom niet correct is, kan het bedrijf niet de maximale voordelen uit zijn gegevens halen. De gegevens moeten gemakkelijk door een organisatie en haar ecosystemen kunnen stromen.
Om deze reden is het belangrijk om een dataleveringsketen te creëren die ervoor zorgt dat de gegevens naar de bedrijfsdoelen werken en een omgeving creëren om die doelen te helpen bereiken.
Wat is een dataketen?
Voordat we in de dataketen terechtkomen. laten we eerst kijken wat een supply chain is?
Een grote dataketen is een proces waardoor iets een organisatie binnenkomt, een transformatie ondergaat en als iets van waarde komt dat door de mensen kan worden gebruikt.
Een data supply chain is ook hetzelfde als elke andere supply chain waar gegevens worden ingevoerd vanaf het ene uiteinde van het systeem en in de volgende stap worden deze getransformeerd met behulp van analyses. Ten slotte wordt het geleverd als een set nuttige inzichten over de organisatie die kunnen worden gebruikt voor verdere verbeteringen in het bedrijfsleven. Data supply chain analist zal de organisatie binnenkomen is afgeleid van verschillende bronnen zoals websites, sociale netwerken, mobiele apps, blogs, CRM en anderen. Data Supply chain is meer gerelateerd aan standaardisatie van gegevens.
Voordelen van dataleveringsketen
De belangrijkste voordelen van het gebruik van een dataketen zijn hieronder opgesomd
- Optimaliseert operationele efficiëntie
- Verbetert de bedrijfsflexibiliteit
- Vermindert gegevenslatentie
- Eenvoudig om nieuwe gegevensbronnen onder te brengen
- Aanpasbaar om grote gegevens in de toekomst te verwerken
- Verbetert de gegevenskwaliteit en voldoet tegelijkertijd aan de eisen van de klant
- Helpt bij het ontdekken van nieuwe modellen voor het genereren van inkomsten, waarbij gegevens dienen als een pluspunt
- Verwerkt de gegevens snel
- Verhoogt de omzet van het bedrijf door hen te helpen betere beslissingen te nemen.
- Klantrelatie verbeteren
Waarom is het bouwen van een grote dataketen belangrijker?
-
Kwaliteit van gegevens is belangrijker dan kwantiteit
Big data supply chain is de eenvoudigste manier om de effectiviteit van elke organisatie te verbeteren. Bedrijven moeten zich dus altijd concentreren op de kwaliteit van de gegevens en meer bronnen ontdekken waaruit kwaliteitsgegevens kunnen worden afgeleid.
-
Meer gegevens zijn belangrijk
Zoeken naar meer gegevens is in veel bedrijven een proces. Daarnaast moeten bedrijven ook proberen hun eigen gegevens te maken. Het creëren van nieuwe gegevensbronnen kan een groot voordeel voor het bedrijf zijn.
-
Focus op uw zakelijke doelen
Het belangrijkste is dat alle mensen in het bedrijf, van personeel tot CIO, de zakelijke doelen moeten kennen. De gegevens moeten gericht zijn op de bedrijfsdoelen. De supply chain van big data zal hierbij helpen.
-
Breed gebruik van gegevens
De supply chain voor big data die uit verschillende bronnen wordt verkregen, moet binnen de organisatie correct worden gebruikt. Om deze reden moet het bedrijf verschillende strategieën en technologieën gebruiken.
Componenten van dataketen
De belangrijke componenten van een dataketen worden hieronder gegeven
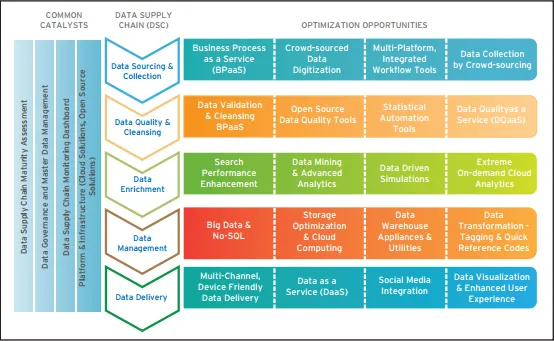
- Gegevensverzameling en -verzameling - Dit omvat Business Process as a Service, uitbesteding van bedrijfsprocessen en Crowdsourcing. Crowdsourcing wordt beschouwd als een vervanging voor de traditionele outsourcingmethode. Menigte betekent hier mensen met een gemeenschappelijk belang. Ze delen oplossingen ten behoeve van de organisatie die de crowdsourcer wordt genoemd
- Gegevenskwaliteit en -reiniging - Gegevens van hoge kwaliteit zijn een zeer waardevol bezit dat de gebruikerservaring verbetert. Om dergelijke ervaringen te verbeteren, moeten bedrijven op maat gemaakte oplossingen en leveranciers gebruiken om de beste resultaten te geven. Data Quality As a Service (DQaaS) moet een groot deel van de datakwaliteit uitmaken omdat het een gecentraliseerde aanpak volgt. Open source-tools zijn het beste om te werken met rommelige gegevenssets.
- Gegevensverrijking - Met behulp van big data-tools zoals Hadoop kunnen de gegevensverrijkingscomponenten de gegevens sneller verwerken en snellere en betere resultaten opleveren.
- Gegevensbeheer - Geavanceerde gegevensmagazijnfuncties gaan verder dan het traditionele gegevensmagazijn en bieden succesvolle bedrijfsinformatie. Ze zijn gemakkelijk en betaalbaar. Geclusterde open source-bestandssystemen zoals HDFS en andere kunnen enkele van de grootste uitdagingen van de gegevensleveringsketen oplossen.
- Datalevering - Datalevering omvat datavisualisatie, classificeren van databases, integratie van sociale media, gebruiksvriendelijke datalevering en Data As a Service (DaaS)
Data Supply Chain Analyst
Data supply chain analist is de architectuur voor het moderne data supply chain proces. Indien op de juiste manier gedaan, laat de dataleveringsketenanalist de bedrijven toe om meer databronnen te benutten en de data-ontdekking in grote mate te verbeteren. Data supply chain analist zal de organisatie helpen drie grote beperkingen onder ogen te zien. Ze worden besproken onder de onderwerpen van data supply chain analist:
-
Beweging
Om diepgaande kennis van de gegevens te krijgen, moeten bedrijven deze uit verschillende bronnen halen en vervolgens het juiste verwerkings- en opslagsysteem gebruiken. Tijdens het verplaatsen van gegevens mag er zelfs geen enkel gegevensverlies zijn en versnelling helpt daarbij. Het brengt nauwkeurige gegevens in de organisatie en zorgt ervoor dat deze snel kunnen worden verwerkt.
-
Verwerken
De verwerking van gegevens hangt voornamelijk af van het volume en het type gegevens. Organisaties verwachten dat het systeem sneller dan ooit berekeningen op de gegevens uitvoert. Data supply chain analist-technologie zal helpen om de gegevens die binnenkomen vooraf te verwerken en stroomlijnt de gegevens met de bestaande gegevens van de organisatie om slimmere beslissingen te nemen. Gegevensversnelling helpt bij de snelle verwerking van gegevens door de hardware- en softwarecomponenten te verbeteren en helpt bij het verbeteren van de efficiëntie.
-
interactiviteit
Interactiviteit betekent de bruikbaarheid van de gegevens. Er zijn veel oplossingen om verwachte resultaten van gegeven vragen te krijgen. Nu zijn er nieuwe programmeertalen ontwikkeld om de systemen te ondersteunen. Gegevensversnelling helpt de gebruikers om de kloof tussen de infrastructuur en applicaties te overbruggen. Dit helpt ook om de queryresultaten snel te leveren.
5 stappen om een dataleveringsketen te bouwen
Hier worden de 5 stappen genoemd om een dataleveringsketen te bouwen
-
Data Service Platform
De eerste en belangrijkste stap bij het creëren van een dataleveringsketen is om te beginnen met het selecteren van een datadienstenplatform dat het bedrijf helpt om gemakkelijk toegang te hebben tot de gegevens uit verschillende bronnen wanneer ze het nodig hebben. Via dit dataplatform hebben de gebruikers direct toegang tot een grote hoeveelheid gegevens. Het dataplatform kan worden gekocht bij een leverancier. Het kan een enkel gegevensplatform zijn of een combinatie van verschillende platforms die door verschillende leveranciers worden geleverd.
Tegenwoordig zijn er ook afzonderlijke dataplatforms die helpen bij het afleiden van gegevens uit één bepaalde bron. Maar al deze platforms werken via een gemeenschappelijk standaard toegangsprotocol. Sinds kort gebruiken veel organisaties API-beheerplatforms.
-
Gegevens versnellen via supply chain
De volgende stap in dit proces is het integreren van de gegevens uit verschillende bronnen. In het verleden maakten bedrijven onderscheid tussen de vaak gebruikte informatie en minder relevante gegevens. De meer relevante gegevens worden opgeslagen op goed presterende systemen en de minder relevante worden opgeslagen in traag presterende systemen. Maar nu kunnen organisaties de snelheid van de gegevens verhogen. De gegevens zijn met grote snelheid toegankelijk voor de mensen in de organisatie en dit helpt bij het verkrijgen van meer kennis uit de gegevens.
-
Bevordering van data-ontdekking
Traditionele BI-methoden vereisen meer details van de datawetenschappers of data-analyseprofessional om een antwoord te krijgen op een voorgeschreven zakelijke vraag. Maar nu vanwege de tools voor gegevensontdekking, voordat de bedrijven beginnen met vragen, onderscheiden ze hun eigen vragen die naar verwachting van de bedrijven zullen rijzen nadat ze de gegevens gedetailleerd hebben leren kennen.
-
Gegevenswaarde realiseren
In de laatste fase van de getransformeerde dataketen kan nu worden gedeeld en toegankelijk zijn. Bedrijven kunnen de gegevens beter begrijpen en er kennis van opdoen. Ze kunnen beslissingen nemen op basis van de gegevens. Om de waarde van de gegevens te vergroten, kunnen deze worden gedeeld met de leveranciers, partners en klanten van het bedrijf.
-
Cognitieve informatica
Cognitieve informatica is een methode waarbij de machine wordt geleerd om de gegevens te gebruiken, ervan te leren en uit te vinden wat ermee kan worden gedaan. Data supply chain biedt een oplossing voor de lange termijn. In een oudere methode kan een oplossing worden gevonden voor een specifieke taak of een afzonderlijke business case. Maar door middel van machine learning-systemen kunnen meer kennis uit gegevens worden gehaald als ervaring, het kan worden opgeslagen en ze kunnen het in de toekomst gebruiken wanneer zich dezelfde situatie voordoet.
Bouwen aan een betere dataketen
Een organisatie die beschikt over de infrastructuur om de gegevens in de supply chain vast te leggen, te verwerken, te analyseren en te distribueren, kan hun voorraden beheren zonder zakelijke kansen te verliezen. Klanten zijn tegenwoordig moeilijk te voorspellen. Als gevolg hiervan wenden veel ondernemingen zich tot vraaggestuurde productie. Gegevensleveringsketens die de vraag van het bedrijf kunnen identificeren en erop kunnen reageren, zullen hen helpen hun productieschema's, distributiemodellen te bereiken, hun marketingstrategieën te definiëren, enzovoort.
De dataketen moet eenvoudig en geïntegreerd blijven. Een grote uitdaging met data is het benaderen en analyseren van de data in verschillende formaten en structuren die zich in de lokale applicatie of in de cloud bevinden. Het is de grootste uitdaging voor de data-analisten op de lange termijn. De datawetenschapper of de data-analist moet bekend zijn met SQL om de kloof tussen deze uitdagingen te overbruggen en de complexe problemen in data op te lossen.
Besluitvormers in de supply chain vertrouwen ook meer op kwaliteitsgegevens. Kwaliteitsgegevens helpen om slimme beslissingen te nemen op basis van de beschikbare accurate informatie. De organisatie moet ervoor zorgen dat de gegevens die worden gebruikt in het besluitvormingsproces van de toeleveringsketen schoon en nauwkeurig zijn. Om het potentieel van de data supply chain leiders te maximaliseren, moeten deze eenvoudige stappen volgen.
-
Werk met nauwkeurige, realtime gegevens
De belangrijkste factor in het leveringsnetwerk is dataconsistentie. Gebrek aan gegevensconsistentie is een groot probleem waarmee de meeste bedrijven kampen. Een belangrijke methode om nauwkeurige gegevens te krijgen, is het analyseren van de timing van MRP-gegevens die de organisatie binnenkomen. Bedrijven kunnen ook workflows voor het vastleggen en valideren van gegevens gebruiken om onvolledige records in uw systeem te vinden. Er kan ook regelmatig worden gecontroleerd om fouten in gegevens te achterhalen.
Mobiele technologie helpt om de real-time gegevens te verbeteren en te integreren met de bevoorradingsnetwerken. Mobiele apparaten kunnen worden gebruikt om gegevens altijd en overal direct te verzenden en ontvangen.
-
Elimineer onnodige gegevens en processen
Onvolledige en onnodige gegevens zijn tijdverspilling in het supply chain-proces. Het bedrijf moet een onafhankelijke AP-automatiseringsoplossing hebben om de gegevens te controleren op driewegafstemming. Een manier om onnodige gegevens te achterhalen is het evalueren van de gebieden van het leveringsnetwerk waar meerdere processen worden gebruikt om de gegevens naar een geïntegreerd systeem te streamen. Dit helpt om de onnodige gegevens in de hele onderneming te segmenteren en de waardevolle gegevens op een regelmatige frequentie te segmenteren. Als gevolg hiervan zullen de gegevens consistenter en betrouwbaarder zijn om betere beslissingen te nemen.
-
Gecentraliseerde gegevensoplossing
De grote uitdaging van het netwerk voor de gegevensvoorziening is de toenemende hoeveelheid informatie die elke dag beschikbaar is. De waarheid is dat hoe meer gegevens altijd niet betekent betere gegevens. Door de fusies en overnames groeien de dataleveringsketennetwerken regelmatig. Organisaties moeten dus manieren vinden om gegevens uit verschillende bronnen en van een groot aantal leveranciers te combineren.
De beste oplossing is om een supply chain samenwerkingssysteem te implementeren waarmee u uw gegevens strategisch kunt bekijken. Deze weergave kan helpen bij het sorteren van gegevens in noodzakelijke onderdelen en het genereren van rapporten met realtime informatie.
Conclusie
Dataleveringsketen zal de komende jaren een grote focus van veel ondernemingen zijn. Het selecteren van de juiste sleutelelementen en diensten van Data Supply Chain zal helpen om de productiviteit te verhogen en het bedrijf te optimaliseren voor eventuele veranderingen in de markt.
gerelateerde artikelen
Dit is een leidraad geweest voor wat is een dataketen? Hier bespreken we ook de 5 stappen om een dataleveringsketen samen met de voordelen en de componenten ervan te bouwen. U kunt ook de supply chain voor grote gegevens lezen
- 9 Belangrijke manieren om supply chain management te verbeteren
- Data Scientist versus Data Engineer - 7 Verbazingwekkende vergelijkingen
- Data Scientist versus Business Analyst - Ontdek de 5 geweldige verschillen
- Ken het beste 7 verschil tussen datamining versus data-analyse