

Verschil tussen data mining en web mining
Datamining : het is een concept om een significant patroon uit de gegevens te identificeren dat een beter resultaat geeft. Waarin patronen identificeren? Van de gegevens die worden gegenereerd uit de systemen.
Web mining : het proces van het uitvoeren van Data mining op het web wordt Web mining genoemd. De webdocumenten extraheren en de patronen ervan ontdekken.
Voorbeeld: technieken toegepast voor voorspellende analyse. (Weersvoorspelling op basis van het identificeren van de patronen uit de geschiedenisgegevens)
Laten we in dit bericht de belangrijkste verschillen tussen datamining en webmining gedetailleerd begrijpen.
Analogie
Goud wordt geproduceerd door het proces dat goudwinning wordt genoemd. Het wordt gewonnen en geraffineerd uit het erts. Het uiteindelijke resultaat van goudwinning is het edelmetaal. Hetzelfde,
om sleutelinformatie (data die de moeite waard is) uit een ruwe bron te halen, wordt dataminingtechniek toegepast. Hier wordt het patroon dat is ontdekt uit de onbewerkte gegevensbron waardevol geacht voor de gegevensanalist / gegevenswetenschappers om door te gaan met de besluitvorming die de bedrijfswaarde beïnvloedt.
Datamining
Simpel gezegd, datamining is een concept van mijnkennis uit verschillende datasets. De verkregen kennis wordt verder gebruikt om voorspellingen of aanbevelingen te doen. De te minderen gegevens zijn beschikbaar in het datawarehouse of andere externe systemen. Gegevens kunnen beschikbaar zijn op verschillende tabellen met hun verschillende gedrag of attributen. Om het patroon te identificeren, moet de correlatie tussen meerdere gegevenssets worden geïdentificeerd.
Stappen in datamining
Aangezien datamining een abstract is, is hier de lijst met stappen,
- Data voorbereiding
- Patroon ontdekking
- Bouw modellen om te voorspellen / aan te bevelen (om enkele gevallen te noemen)
- Samenvatting van de modelwaarde
Web mining
Web mining is een abstract omdat er drie verschillende soorten mijnbouwtechnieken zijn.
- Web content mining
- Webstructuur mijnbouw
- Webgebruik mining
Web mining klassen voor het verzamelen van informatie 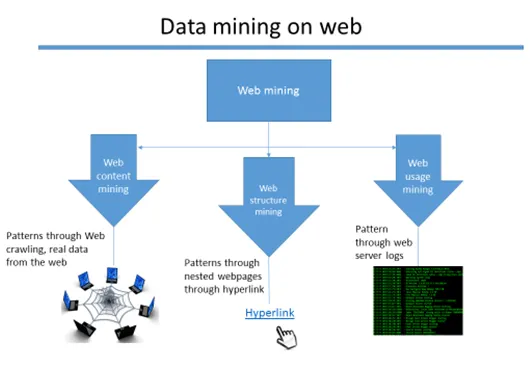
Web content mining
Gegevens van de webpagina's worden geëxtraheerd om verschillende patronen te ontdekken die een aanzienlijk inzicht geven. Er zijn veel technieken om de gegevens te extraheren, zoals webscraping (bijvoorbeeld - scrapy en Octoparse zijn de bekende tools die het proces van webcontentmining uitvoeren.
Een van de beste voorbeelden - Om een evenement of een programma uit te voeren, analyseert de organisatie eerst de locaties (welke locatie is het meest geschikt om het programma uit te voeren, zodat er volledige aanwezigheid is). Om deze analyses uit te voeren, moet men locatiespecifieke informatie verzamelen over de stad, de staat en hoe ver het evenement zich van de genodigde bevindt. Alle locatiespecifieke gegevens kunnen van het web worden geëxtraheerd. Dat is waar de webcontent-mining in beeld komt.
Webstructuur mining
Gegevens van hyperlinks die naar verschillende pagina's leiden, worden verzameld en voorbereid om een patroon te ontdekken. Om het openbare profiel van een persoon van een blog of een andere webpagina te bekijken, zijn er kansen dat deze hun sociale media-links insluiten. De gegevens worden dus niet alleen uit één bron gehaald, maar ook uit de geneste pagina's via de hyperlinks die aan elke pagina zijn gekoppeld. Er zijn verschillende algoritmen om dit uit te voeren. (Voorbeeld: PageRank-algoritme)
Webgebruik mining:
Wanneer een webtoepassing wordt gehost, worden er veel webserverlogboeken gegenereerd over de webactiviteit van de toepassing van de toepassing. Deze logs worden beschouwd als onbewerkte gegevens, in ruil daarvoor worden betekenisvolle gegevens geëxtraheerd en patronen geïdentificeerd.
Bijvoorbeeld, voor elk e-commercebedrijf, wanneer ze de reikwijdte van het bedrijf willen vergroten of een verbetering willen toevoegen voor een betere klantervaring, worden de webactiviteiten van gebruikers via de applicatielogboeken gecontroleerd en wordt datamining daarop toegepast.
Web mining en data mining zijn min of meer vergelijkbare technieken, maar web mining draait allemaal om analyse op het web. Datamining is niet beperkt tot internet. Het is een traditioneel proces dat plaatsvindt voor elke data-analyse.
Over de gegevens van internet gesproken, er zijn verschillende gegevens die kunnen worden waargenomen. Het kunnen gestructureerde gegevens zijn (databasegegevens worden via API opgehaald als deze openbaar worden gemaakt). Semi-gestructureerde gegevens - alle webactiviteit gerelateerde of zelfs serverlogboeken. Of zelfs ongestructureerde gegevens zoals afbeeldingen enz. (Als er een analyse op afbeeldingen wordt uitgevoerd)
Head-to-head vergelijking tussen datamining versus webmining (infographics)
Hieronder vindt u de Top 7-vergelijkingen tussen datamining en webmining

Belangrijkste verschillen tussen datamining versus webmining
Het volgende is het verschil tussen datamining en webmining als volgt
Web mining en datamining zijn beide bijna hetzelfde als het gaat om het identificeren van de patronen. Maar waar en wat is het verschil in web mining van datamining. Wat voor soort gegevens en gegevens worden waar geëxtraheerd? Dit zijn de twee ultieme aspecten die het verschil maken tussen Data mining en Web mining.
Web mining valt onder datamining, maar dit is beperkt tot webgerelateerde gegevens en het identificeren van de patronen. Datamining is een enorm concept dat uit meerdere stappen bestaat, van het voorbereiden van de gegevens tot het valideren van de eindresultaten die leiden tot het besluitvormingsproces voor een organisatie.
Datamining versus Web mining Vergelijkingstabel
| Basis voor vergelijking | Datamining | Web mining |
| Concept | Patroonidentificatie van gegevens die beschikbaar zijn in alle systemen. | Patroonidentificatie van webgegevens. |
| Toepassing / gebruikscasussen | Weersverwachting met historische weerrapporten | Gegevens crawlen HITS / PageRank-technieken |
| Wie doet dit? | Data wetenschappers Data-ingenieurs | Gegevenswetenschappers / gegevensanalisten Data-ingenieurs |
| Werkwijze | Gegevensextractie -> Patroonontdekking -> De functie ontwikkelen / oplossen (algoritme) | Hetzelfde proces maar op internet met behulp van de webdocumenten |
| Gereedschap | Machine learning algoritmen | Scrappy, Paginabeoordeling, Apache-logboeken |
| Hoe belangrijk | Veel organisaties vertrouwen op gegevenswetenschappelijke resultaten voor het nemen van beslissingen. | Webgerelateerde datatrekking zou het bestaande dataminingproces beïnvloeden. |
| Vaardigheden | Technieken voor het opschonen van gegevens, algoritmen voor machine learning, statistieken, waarschijnlijkheid | Kennis op applicatieniveau, Data engineering, statistieken, waarschijnlijkheid |
Conclusie - Data mining versus Web mining
Alle mijnbouwtechnieken met de gegevens zijn om de kennis te ontdekken en hoe goed deze kan worden gebruikt om een beter resultaat te bereiken. Organisaties die graag hun bedrijf willen verbeteren en veel winst willen maken, hebben veel beslissingen nodig op basis van de gegevens die grotendeels beschikbaar zijn in hun systemen die in gigantisch volume zijn gegenereerd. Niet alle gegevens worden beschouwd als kennis en inzichten. Welke, waarom en wat zijn de belangrijkste vragen waar data-wetenschappers / data-analisten aan moeten denken als ze zich voorbereiden om de patronen te identificeren. In de term van een leek is datamining als een proces waarbij de melk wordt geroerd om boter te maken.
Aanbevolen artikel
Dit is een leidraad geweest voor Data mining versus Web mining, hun Betekenis, Head to Head Compare, Key Differences, Comparision Table en Conclusie. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Datamining versus statistieken - welke beter is
- 10 krachtige stappen voor effectieve webdesignplanning
- Datamining versus machinaal leren - 10 beste dingen die u moet weten
- Beste 3 dingen om te leren over datamining versus tekstmining
- Hulpmiddelen en technieken die worden gebruikt in het dataminingproces