

Inleiding tot Apache Flume
Apache Flume is Data Ingestion Framework dat op gebeurtenissen gebaseerde gegevens schrijft naar het Hadoop Distributed File System. Het is een bekend feit dat Hadoop Big data verwerkt, de vraag rijst hoe de gegevens die zijn gegenereerd door verschillende webservers worden overgebracht naar Hadoop File System? Het antwoord is Apache Flume. Flume is ontworpen voor het innemen van grote hoeveelheden gegevens naar Hadoop van op gebeurtenissen gebaseerde gegevens.
Overweeg een scenario waarbij het aantal webservers logbestanden genereert en deze logbestanden naar het Hadoop-bestandssysteem moeten verzenden. Flume verzamelt die bestanden als evenementen en neemt ze op in Hadoop. Hoewel Flume wordt gebruikt om te verzenden naar Hadoop, is er geen rigide regel dat de bestemming Hadoop moet zijn. Flume is in staat om te schrijven naar andere Frameworks zoals Hbase of Solr.
Gootarchitectuur
Over het algemeen bestaat de Apache Flume-architectuur uit de volgende componenten:
- Gootbron
- Flume Channel
- Gootsteen
- Flume-agent
- Flume-evenement
Laten we elk Flume-onderdeel kort bekijken
1. Gootbron
Een Flume-bron is aanwezig op gegevensgenerators zoals Face Book of Twitter. Source verzamelt gegevens van de generator en draagt die gegevens over naar Flume Channel in de vorm van Flume Events. Flume ondersteunt verschillende soorten bronnen, zoals Avro Flume Source - maakt verbinding via Avro-poort en ontvangt gebeurtenissen van externe Avro-client, Thrift Flume Source- maakt verbinding via Thrift-poort en ontvangt gebeurtenissen van externe Thrift-clientstreams, Spooling Directory Source en Kafka Flume Source.
2. Flume Channel
Een tussenopslag die de gebeurtenissen buffert die door Flume Source zijn verzonden totdat ze door Sink worden verbruikt, wordt Flume Channel genoemd. Kanaal fungeert als een tussenbrug tussen Source en Sink. Flume-kanalen hebben een transactiekarakter.
Flume biedt ondersteuning voor het bestandskanaal en het geheugenkanaal. Het bestandskanaal is duurzaam van aard, wat betekent dat zodra de gegevens naar het kanaal zijn geschreven, deze niet verloren gaan, hoewel de agent opnieuw wordt opgestart. In het geheugen worden kanaalgebeurtenissen in het geheugen opgeslagen, dus het is niet duurzaam maar erg snel van aard.
3. Gootsteen
Een Flume Sink is aanwezig op gegevensrepository's zoals HDFS, HBase. Flume sink verbruikt evenementen van Channel en slaat deze op in Destination-winkels zoals HDFS. Er is geen regel dat de sink evenementen naar Store moet afleveren, in plaats daarvan kunnen we het zo configureren dat een sink evenementen naar een andere agent kan afleveren. Flume ondersteunt verschillende wastafels zoals HDFS Sink, Hive Sink, Thrift Sink, Avro Sink.
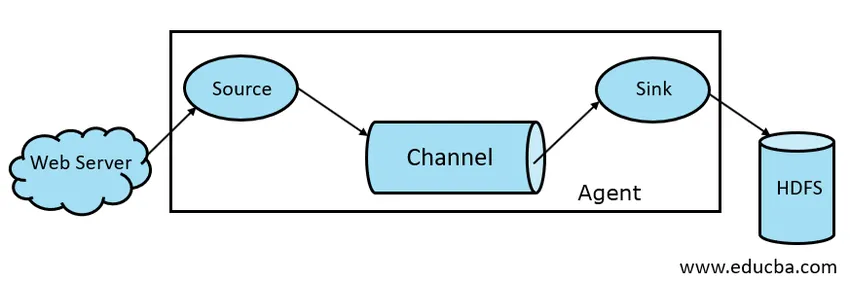
Fig 1.1 Basic Flume Architecture
4. Flume-agent
Een Flume-agent is een langlopend Java-proces dat wordt uitgevoerd op Bron - Kanaal - Sink Combinatie. Flume kan meer dan één agent hebben. We kunnen Flume beschouwen als een verzameling verbonden Flume-agenten die in de natuur worden verspreid.
5. Flume-gebeurtenis
Een gebeurtenis is de eenheid van gegevens die worden getransporteerd in Flume . Algemene weergave van een gegevensobject in Flume wordt gebeurtenis genoemd. De gebeurtenis bestaat uit een lading van een bytearray met optionele headers.
Werken van Flume
Een Flume-agent is een Java-proces dat bestaat uit Source - Channel - Sink in zijn eenvoudigste vorm. Source verzamelt gegevens van datagenerator in de vorm van Evenementen en levert deze aan Channel. Een Bron kan naar behoefte meerdere kanalen leveren. Fan out is het proces waarbij een enkele bron naar meerdere kanalen schrijft, zodat deze naar meerdere wastafels kunnen leveren.
Een gebeurtenis is de basiseenheid van gegevens die worden verzonden in Flume. Kanaal buffert de gegevens totdat deze door Sink worden ingenomen. Sink verzamelt de gegevens van Channel en levert deze af aan gecentraliseerde gegevensopslag zoals HDFS of Sink kan die gebeurtenissen naar behoefte doorsturen naar een andere Flume-agent.
Flume ondersteunt transacties. Om Betrouwbaarheid te bereiken, gebruikt Flume afzonderlijke transacties van bron naar kanaal en van kanaal naar gootsteen. Als gebeurtenissen niet worden afgeleverd, wordt de transactie teruggedraaid en later opnieuw afgeleverd.
Om de werking van Flume te begrijpen, laten we een voorbeeld nemen van de Flume-configuratie waarbij de bron de directory in de wachtrij plaatst en de sink Hdf's is. In dit voorbeeld is de Flume-agent in de eenvoudigste vorm, dat wil zeggen single source - channel - sink topology die is geconfigureerd met behulp van een java-eigenschappenbestand.
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.channels.channel1.type = file
In het bovenstaande configuratievoorbeeld is agent de basis waarmee we andere eigenschappen definiëren. source1 en sink1 en channel1 zijn respectievelijk de namen van bron, sink en kanaal en hun typen en locaties worden ook dienovereenkomstig vermeld.
Voordelen van Apache Flume
- Flume is schaalbaar, betrouwbaar en fouttolerant van aard. Deze eigenschappen worden hieronder in detail besproken
- Schaalbaar - Flume is horizontaal schaalbaar, dat wil zeggen dat we nieuwe knooppunten kunnen toevoegen volgens onze vereisten
- Betrouwbaar - Apache Flume biedt ondersteuning voor transacties en zorgt ervoor dat tijdens het verzenden van gegevens geen gegevens verloren gaan. Het heeft verschillende transacties van bron tot kanaal en van kanaal tot bron.
- Flume is aanpasbaar en biedt ondersteuning voor verschillende bronnen en gootstenen zoals Kafka, Avro, spooling directory, Thrift etc
- In Flume kan één bron gegevens naar meerdere kanalen verzenden en die kanalen zullen op hun beurt de gegevens naar meerdere putten verzenden, zodat één bron gegevens naar meerdere putten kan verzenden. Dit mechanisme wordt Fan out genoemd. Flume ondersteunt ook voor Fan out.
- Flume zorgt voor de gestage stroom van gegevensoverdracht, dwz als de gegevensleessnelheid toeneemt en vervolgens ook de gegevensschrijfsnelheid toeneemt.
- Hoewel Flume over het algemeen gegevens naar gecentraliseerde opslag zoals HDFS of Hbase schrijft, kunnen we Flume volgens onze vereisten zodanig configureren dat Sink gegevens naar een andere agent kan schrijven. Dit toont de flexibiliteit van Flume
- Apache Flume is open source in de natuur.
Conclusie
In dit Flume-artikel worden componenten van Flume en werking van Flume in detail besproken. Flume is een flexibel, betrouwbaar en schaalbaar platform voor het verzenden van gegevens naar een gecentraliseerde winkel zoals HDFS. Het vermogen om te integreren met verschillende applicaties zoals Kafka, Hdfs en Thrift maakt het een haalbare optie voor het opnemen van gegevens.
Aanbevolen artikelen
Dit is een gids voor Apache Flume geweest. Hier bespreken we de architectuur, werking en voordelen van Apache Flume. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Wat is Apache Flink?
- Verschil tussen Apache Kafka versus Flume
- Big Data-architectuur
- Hadoop-gereedschappen
- Leer de verschillende JavaScript-gebeurtenissen