

Inleiding tot methoden voor datamining
Gegevens nemen dagelijks op enorme schaal toe. Maar alle verzamelde of verzamelde gegevens zijn niet nuttig. Betekenisvolle gegevens moeten worden gescheiden van lawaaierige gegevens (betekenisloze gegevens). Dit scheidingsproces wordt uitgevoerd door datamining.
Wat is datamining?
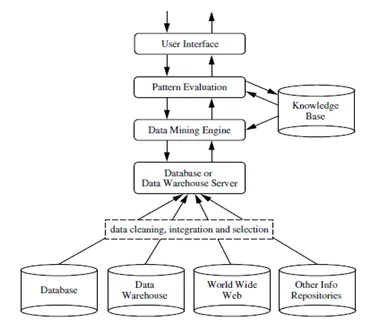
Datamining is een proces waarbij nuttige informatie of kennis wordt onttrokken aan een enorme hoeveelheid gegevens (of big data). De kloof tussen gegevens en informatie is verkleind door verschillende dataminingtools te gebruiken. Datamining kan ook worden aangeduid als Kennisdetectie uit gegevens of KDD .
Bronnen: - www.ques10.com
Datamining kan worden uitgevoerd op verschillende soorten databases en informatieopslagplaatsen zoals relationele databases, datawarehouses, transactionele databases, datastromen en nog veel meer.
Verschillende methoden voor datamining:
Er zijn veel methoden die worden gebruikt voor datamining, maar de cruciale stap is om de juiste methode te selecteren op basis van het bedrijf of de probleemstelling. Deze dataminingmethoden helpen bij het voorspellen van de toekomst en vervolgens het nemen van beslissingen dienovereenkomstig. Deze helpen ook bij het analyseren van de markttendens en bij het verhogen van de bedrijfsinkomsten.
Sommige methoden voor datamining zijn:
- Vereniging
- Classificatie
- Clustering analyse
- Voorspelling
- Opeenvolgende patronen of Patroon volgen
- Beslissingsbomen
- Uitbijteranalyse of Anomalieanalyse
- Neuraal netwerk
Laten we alle dataminingmethoden één voor één begrijpen.
1. Vereniging:
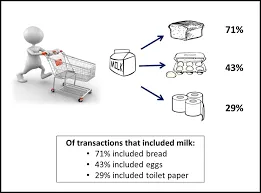
Het is een methode die wordt gebruikt om een correlatie tussen twee of meer items te vinden door het verborgen patroon in de gegevensset te identificeren en wordt daarom ook wel relatieanalyse genoemd . Deze methode wordt gebruikt in marktmandanalyse om het gedrag van de klant te voorspellen.
Stel dat de marketingmanager van een supermarkt wil bepalen welke producten vaak samen worden gekocht.
Als voorbeeld,
Koopt (x, "bier") -> koopt (x, "chips") (ondersteuning = 1%, vertrouwen = 50%)
- Hier staat x voor een klant die samen bier en friet koopt.
- Vertrouwen toont zekerheid dat als een klant een biertje koopt, de kans 50% is dat hij / zij de chips ook zal kopen.
- Ondersteuning betekent dat 1% van alle geanalyseerde transacties aantoonde dat bier en chips samen werden gekocht.
Veel vergelijkbare voorbeelden zoals brood en boter of computer en software kunnen worden overwogen.
Er zijn twee soorten associatieregels:
- Regeling voor eendimensionale associatie: deze regels bevatten één kenmerk dat wordt herhaald.
- Multidimensionale associatieregel: deze regels bevatten meerdere attributen die worden herhaald.
https://bit.ly/2N61gzR
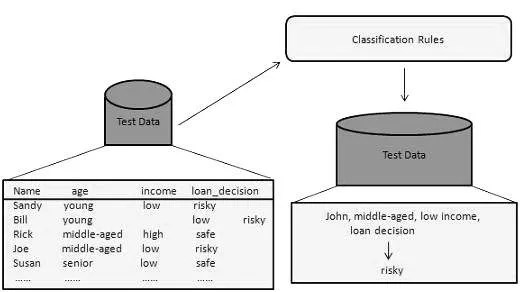
2. Classificatie:
Deze datamining-methode wordt gebruikt om de items in de datasets in klassen of groepen te onderscheiden. Het helpt om het gedrag van items binnen de groep nauwkeurig te voorspellen. Het is een proces in twee stappen:
- Leerstap (trainingsfase): hierin bouwt een classificatie-algoritme de classifier op door een trainingsset te analyseren.
- Classificatiestap: testgegevens worden gebruikt om de nauwkeurigheid of precisie van de classificatieregels te schatten.
Een bankbedrijf gebruikt bijvoorbeeld om kredietaanvragers te identificeren met een laag, gemiddeld of hoog kredietrisico. Evenzo analyseert een medisch onderzoeker kankergegevens om te voorspellen welk geneesmiddel aan de patiënt moet worden voorgeschreven.
Bronnen: - www.tutorialspoint.com
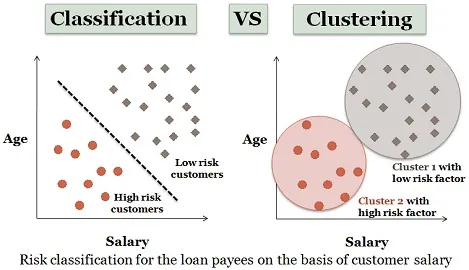
3. Clusteringanalyse:
Clustering is bijna vergelijkbaar met classificatie, maar in deze clusters worden gemaakt afhankelijk van de overeenkomsten van gegevensitems. Verschillende clusters hebben ongelijksoortige of niet-gerelateerde objecten. Het wordt ook wel gegevenssegmentatie genoemd omdat het enorme gegevensreeksen in clusters verdeelt volgens de overeenkomsten.
Er zijn verschillende clustermethoden die worden gebruikt:
- Hiërarchische Agglomeratieve methoden
- Grid-gebaseerde methoden
- Partitioneermethoden
- Modelgebaseerde methoden
- Op dichtheid gebaseerde methoden
Een vergelijkbaar voorbeeld van leningaanvragers kan hier ook worden overwogen. Er zijn enkele verschillen die in onderstaande figuur worden weergegeven.
https://bit.ly/2N6aZpP
4. Voorspelling:
Deze methode wordt gebruikt om de toekomst te voorspellen op basis van trends in het verleden en heden of gegevensset. Voorspelling wordt meestal gebruikt in combinatie met andere methoden voor datamining, zoals classificatie, patroonvergelijking, trendanalyse en relatie.
Als de verkoopmanager van een supermarkt bijvoorbeeld wil voorspellen hoeveel inkomsten elk artikel zou genereren op basis van eerdere verkoopgegevens. Het modelleert een continu gewaardeerde functie die ontbrekende numerieke gegevenswaarden voorspelt.

Bronnen: - data-mining.philippe-fournier
Regressieanalyse is de beste keuze om voorspellingen uit te voeren. Het kan worden gebruikt om een relatie tussen onafhankelijke variabelen en afhankelijke variabelen in te stellen.
5. Opeenvolgende patronen of patroon volgen:
Deze dataminingmethode wordt gebruikt om patronen te identificeren die gedurende een bepaalde periode vaak voorkomen.
De verkoopmanager van het kledingbedrijf ziet bijvoorbeeld dat de verkoop van jassen lijkt te stijgen vlak voor het winterseizoen, of de omzet in bakkerij stijgt tijdens kerst of oudejaarsavond.
Laten we een voorbeeld bekijken met een grafiek
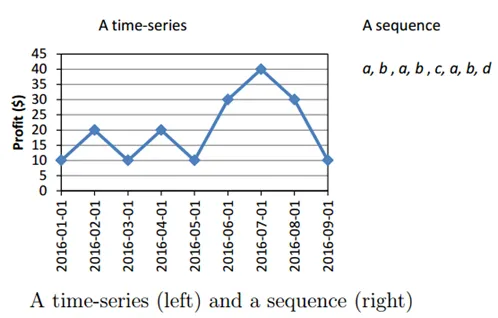
Bronnen: - data-mining.philippe-fournier-viger
6. Besluit Bomen:
Een beslissingsboom is een boomstructuur (zoals de naam al doet vermoeden), waar
- Elk intern knooppunt vertegenwoordigt een test op het kenmerk.
- Branch geeft het resultaat van de test aan.
- Terminalknooppunten bevatten het klassenlabel.
- Het bovenste knooppunt is het hoofdknooppunt met de eenvoudige vraag met twee of meer antwoorden. Dienovereenkomstig groeit de boom en wordt een stroomdiagramachtige structuur gegenereerd.
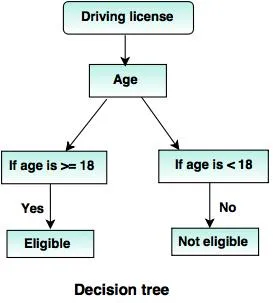
Bronnen: - www.tutorialride.com
In deze beslissing classificeert de boomregering burgers jonger dan 18 jaar of ouder dan 18 jaar. Dit zou hen helpen om te beslissen of een vergunning aan een bepaalde burger moet worden verleend of niet.
7.Outlier-analyse of anomalie-analyse:
Deze dataminingmethode wordt gebruikt om de gegevensitems te identificeren die niet voldoen aan het verwachte patroon of verwachte gedrag. Deze onverwachte gegevensitems worden beschouwd als uitbijters of ruis. Ze zijn nuttig in veel domeinen zoals creditcardfraude detectie, inbraakdetectie, foutdetectie etc. Dit wordt ook wel Outlier Mining genoemd .
Laten we bijvoorbeeld aannemen dat de onderstaande grafiek is uitgezet met behulp van enkele gegevenssets in onze database.
Dus de best passende lijn wordt getekend. De punten die dichtbij de lijn liggen, vertonen verwacht gedrag, terwijl het punt ver van de lijn een uitbijter is.
Dit zou helpen om de afwijkingen op te sporen en dienovereenkomstig mogelijke acties te ondernemen.
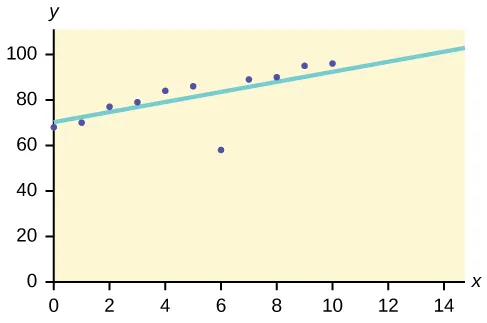
https://bit.ly/2GrgjDP
8. Neuraal netwerk:
Deze dataminingmethode of -model is gebaseerd op biologische neurale netwerken. Het is een verzameling neuronen zoals verwerkingseenheden met gewogen verbindingen daartussen. Ze worden gebruikt om de relatie tussen ingangen en uitgangen te modelleren. Het wordt gebruikt voor classificatie, regressieanalyse, gegevensverwerking enz. Deze techniek werkt op drie pijlers:
- Model
- Leeralgoritme (onder toezicht of zonder toezicht)
- Activeringsfunctie
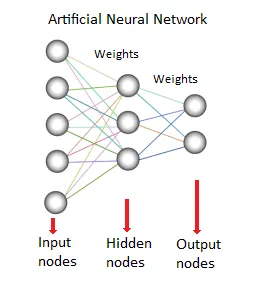
Bronnen: - www.saedsayad.com
Aanbevolen artikelen
Dit is een gids voor dataminingmethoden Hier hebben we besproken wat datamining en verschillende soorten dataminingmethode met het voorbeeld is. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Big Data Analytics-software
- Sollicitatievragen voor Data Structure
- Belangrijke technieken voor datamining
- Datamining-architectuur