
Inleiding tot modellen voor machinaal leren
Een overzicht van verschillende machine learning-modellen die in de praktijk worden gebruikt. Volgens de definitie is een machine learning-model een wiskundige configuratie die wordt verkregen na toepassing van specifieke machine learning-methoden. Met behulp van de uitgebreide reeks API's is het bouwen van een machine learning-model tegenwoordig vrij eenvoudig met minder regels codes. Maar de echte vaardigheid van een professional in toegepaste gegevenswetenschap ligt in het kiezen van het juiste model op basis van de probleemstelling en kruisvalidatie in plaats van gegevens willekeurig naar fancy algoritmen te gooien. In dit artikel bespreken we verschillende machine learning-modellen en hoe ze effectief te gebruiken op basis van het soort problemen dat ze aanpakken.
Soorten modellen voor machinaal leren
Op basis van het type taken kunnen we machine learning-modellen in de volgende typen classificeren:
- Classificatiemodellen
- Regressiemodellen
- clustering
- Dimensionaliteitsreductie
- Diep leren etc.
1) Classificatie
Met betrekking tot machine learning is classificatie de taak om het type of de klasse van een object te voorspellen binnen een eindig aantal opties. De uitvoervariabele voor classificatie is altijd een categorische variabele. Het voorspellen van een e-mail is bijvoorbeeld spam of niet, is een standaard binaire classificatietaak. Laten we nu enkele belangrijke modellen voor classificatieproblemen noteren.
- K-dichtstbijzijnde buren algoritme - eenvoudig maar rekenkundig uitputtend.
- Naïeve Bayes - Gebaseerd op de stelling van Bayes.
- Logistische regressie - Lineair model voor binaire classificatie.
- SVM - kan worden gebruikt voor binaire / multiclass-classificaties.
- Beslisboom - ' If Else ' gebaseerde classificatie, robuuster voor uitbijters.
- Ensembles - Combinatie van meerdere samengeklapte modellen voor machine learning om betere resultaten te krijgen.
2) Regressie
In de machine is leerregressie een reeks problemen waarbij de uitgangsvariabele continue waarden kan aannemen. Het voorspellen van de luchtvaartprijs kan bijvoorbeeld worden beschouwd als een standaard regressietaak. Laten we enkele belangrijke regressiemodellen noteren die in de praktijk worden gebruikt.
- Lineaire regressie - Eenvoudigste baselinemodel voor regressietaak, werkt alleen goed als gegevens lineair van elkaar kunnen worden gescheiden en er minder of geen multicollineariteit aanwezig is.
- Lasso-regressie - Lineaire regressie met L2-regularisatie.
- Ridge-regressie - Lineaire regressie met L1-regularisatie.
- SVM-regressie
- Beslisboomregressie enz.
3) Clustering
In eenvoudige woorden, clustering is de taak om vergelijkbare objecten bij elkaar te groeperen. Machine learning-modellen helpen om vergelijkbare objecten automatisch te identificeren zonder handmatige tussenkomst. We kunnen geen effectieve modellen voor machinaal leren onder toezicht (modellen die moeten worden getraind met handmatig samengestelde of gelabelde gegevens) bouwen zonder homogene gegevens. Clustering helpt ons dit op een slimmere manier te bereiken. Hier volgen enkele van de meest gebruikte clustermodellen:
- K betekent - Eenvoudig maar lijdt aan grote variantie.
- K betekent ++ - Gewijzigde versie van K betekent.
- K medoiden.
- Agglomeratieve clustering - Een hiërarchisch clustermodel.
- DBSCAN - Op dichtheid gebaseerd clusteringalgoritme enz.
4) Dimensionaliteitsreductie
Dimensionaliteit is het aantal voorspellende variabelen dat wordt gebruikt om de onafhankelijke variabele of het doel te voorspellen. In de echte gegevenssets is het aantal variabelen vaak te hoog. Te veel variabelen brengen ook de vloek van overfitting naar de modellen. Onder deze grote aantallen variabelen dragen in de praktijk niet alle variabelen in gelijke mate bij aan het doel en in een groot aantal gevallen kunnen we variaties met een kleiner aantal variabelen behouden. Laten we een paar veelgebruikte modellen voor vermindering van de dimensionaliteit opsommen.
- PCA - Het creëert minder aantallen nieuwe variabelen uit een groot aantal voorspellers. De nieuwe variabelen zijn onafhankelijk van elkaar, maar minder interpreteerbaar.
- TSNE - Biedt lagere dimensionale inbedding van hoger-dimensionale datapunten.
- SVD - Enkelvoudige ontleding van waarden wordt gebruikt om de matrix in kleinere delen te ontleden om een efficiënte berekening te verkrijgen.
5) Diep leren
Diep leren is een subset van machine learning die zich bezighoudt met neurale netwerken. Laten we op basis van de architectuur van neurale netwerken een lijst maken van belangrijke modellen voor diep leren:
- Meerlaagse perceptron
- Convolution neurale netwerken
- Terugkerende neurale netwerken
- Boltzmann-machine
- Autoencoders etc.
Welk model is het beste?
Hierboven namen we ideeën over veel modellen voor machine learning. Nu komt een voor de hand liggende vraag bij ons op: 'Wat is het beste model onder hen?' Het hangt af van het probleem bij de hand en andere bijbehorende attributen zoals uitbijters, het volume van beschikbare gegevens, gegevenskwaliteit, engineering van functies, enz. In de praktijk heeft het altijd de voorkeur om te beginnen met het eenvoudigste model dat van toepassing is op het probleem en de complexiteit te vergroten geleidelijk door juiste parameterafstemming en kruisvalidatie. Er is een spreekwoord in de wereld van data science - 'Cross-validatie is betrouwbaarder dan domeinkennis'.
Hoe een model te bouwen?
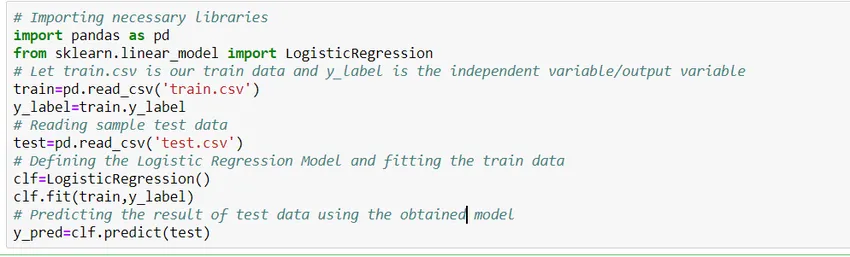
Laten we eens kijken hoe we een eenvoudig logistiek regressiemodel kunnen bouwen met behulp van de Scikit Learn-bibliotheek van python. Voor de eenvoud gaan we ervan uit dat het probleem een standaardclassificatiemodel is en 'train.csv' is de trein en 'test.csv' is respectievelijk de trein- en testgegevens.
Conclusie
In dit artikel hebben we de belangrijke machine learning-modellen besproken die voor praktische doeleinden worden gebruikt en hoe een eenvoudig machine learning-model in python kan worden gebouwd. Het kiezen van een geschikt model voor een bepaalde use case is erg belangrijk om het juiste resultaat van een machine learning-taak te verkrijgen. Om de prestaties tussen verschillende modellen te vergelijken, zijn evaluatiemetrieken of KPI's gedefinieerd voor bepaalde bedrijfsproblemen en wordt het beste model gekozen voor productie na toepassing van de statistische prestatiecontrole.
Aanbevolen artikelen
Dit is een handleiding voor modellen voor machinaal leren. Hier bespreken we de Top 5 soorten machine learning-modellen met zijn definitie. U kunt ook onze andere voorgestelde artikelen doornemen voor meer informatie -
- Machine leermethoden
- Soorten machine learning
- Machine Learning-algoritmen
- Wat is machinaal leren?
- Machine leren van hyperparameter
- KPI in Power BI
- Hiërarchisch clusteringalgoritme
- Hiërarchische clustering | Agglomerative & Divisive Clustering