

Diepgaande sollicitatievragen en antwoorden
Tegenwoordig wordt Deep Learning gezien als een van de snelstgroeiende technologie met een enorme mogelijkheid om een applicatie te ontwikkelen die al een tijdje geleden als zwaar werd beschouwd. Spraakherkenning, beeldherkenning, patronen zoeken in een gegevensset, objectclassificatie in foto's, het genereren van tekentekst, zelfrijdende auto's en nog veel meer zijn slechts enkele voorbeelden waar Deep Learning het belang ervan heeft aangetoond.
Dus je hebt eindelijk je droombaan gevonden in Deep Learning, maar je vraagt je af hoe je het Deep Learning Interview kunt kraken en wat de waarschijnlijke Deep Learning Interview-vragen kunnen zijn. Elk interview is anders en de reikwijdte van een baan is ook anders. Met dit in gedachten hebben we de meest voorkomende Deep Learning-interviewvragen en -antwoorden ontworpen om u te helpen succes te behalen in uw interview.
Hieronder staan enkele Deep Learning Interview-vragen die veel worden gesteld in Interview en die ook kunnen helpen om je niveaus te testen:
Deel 1 - Diepgaande sollicitatievragen (basis)
Dit eerste deel behandelt basisvragen en antwoorden op Deep Learning-interviews
1. Wat is diep leren?
Antwoord:
Het gebied van machine learning dat zich richt op diepe kunstmatige neurale netwerken die losjes door hersenen worden geïnspireerd. Alexey Grigorevich Ivakhnenko publiceerde de eerste generaal over het werk Deep Learning-netwerk. Tegenwoordig heeft het zijn toepassing op verschillende gebieden, zoals computer vision, spraakherkenning, natuurlijke taalverwerking.
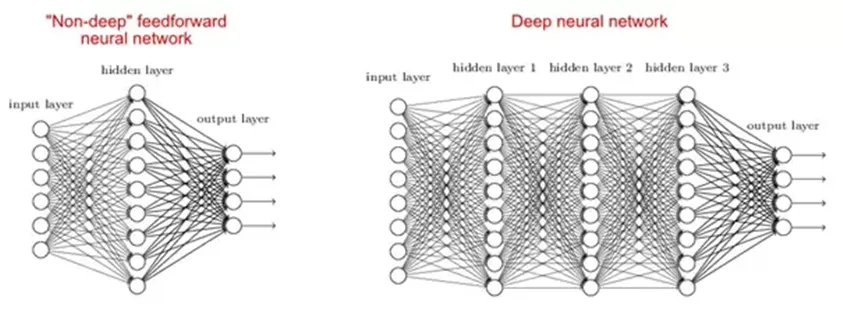
2. Waarom zijn diepe netwerken beter dan oppervlakkige?
Antwoord:
Er zijn onderzoeken die zeggen dat zowel ondiepe als diepe netwerken bij elke functie passen, maar omdat diepe netwerken verschillende verborgen lagen hebben, vaak van verschillende typen, kunnen ze betere functies bouwen of extraheren dan ondiepe modellen met minder parameters.
3. Wat is de kostenfunctie?
Antwoord:
Een kostenfunctie is een maat voor de nauwkeurigheid van het neurale netwerk met betrekking tot het gegeven trainingsvoorbeeld en de verwachte output. Het is een enkele waarde, niet-vector, omdat het de prestaties van het neurale netwerk als geheel geeft. Het kan als volgt worden berekend Mean Squared Error-functie: -
MSE = 1nΣi = 0 n (Y i-Yi) 2
Waar Y en de gewenste waarde Y is wat we willen minimaliseren.
Laten we doorgaan naar de volgende Deep Learning-interviewvragen.
4. Wat is kleurverloop?
Antwoord:
Gradiëntdaling is in feite een optimalisatie-algoritme, dat wordt gebruikt om de waarde te leren van parameters die de kostenfunctie minimaliseren. Het is een iteratief algoritme dat zich verplaatst in de richting van de steilste afdaling zoals gedefinieerd door het negatief van de gradiënt. We berekenen de verloopdaling van de kostenfunctie voor een bepaalde parameter en werken de parameter bij met de onderstaande formule: -
Θ: = Θ-αd∂ΘJ (Θ)
Waar Θ - de parametervector is, α - leersnelheid, J (Θ) - een kostenfunctie is.
5. Wat is backpropagation?
Antwoord:
Backpropagation is een trainingsalgoritme dat wordt gebruikt voor een neuraal netwerk met meerdere lagen. Bij deze methode verplaatsen we de fout van een uiteinde van het netwerk naar alle gewichten binnen het netwerk en maken zo een efficiënte berekening van de gradiënt mogelijk. Het kan als volgt in verschillende stappen worden verdeeld: -
Voorwaartse verspreiding van trainingsgegevens om output te genereren.
Vervolgens kan de afgeleide van de doelwaarde en de outputwaardefout worden berekend met betrekking tot de activering van de output.
Vervolgens maken we een back-propagage voor het berekenen van de afgeleide van de fout met betrekking tot uitgangsactivering op vorige en gaan we hiermee door voor alle verborgen lagen.
Met behulp van eerder berekende derivaten voor output en alle verborgen lagen berekenen we foutderivaten met betrekking tot gewichten.
En dan werken we de gewichten bij.
6. Verklaar de volgende drie varianten van gradiëntdaling: batch, stochastisch en mini-batch?
Antwoord:
Stochastische gradiëntdaling : hier gebruiken we slechts één trainingsvoorbeeld voor het berekenen van gradiënt- en update-parameters.
Batch Gradient Descent : hier berekenen we het verloop voor de hele dataset en voeren we de update uit bij elke iteratie.
Mini-batch Gradient Descent : het is een van de meest populaire optimalisatie-algoritmen. Het is een variant van Stochastic Gradient Descent en hier wordt in plaats van een enkel trainingsvoorbeeld een mini-batch monsters gebruikt.
Deel 2 - Interviewvragen diep leren (geavanceerd)
Laten we nu eens kijken naar de geavanceerde Deep Learning-interviewvragen.
7. Wat zijn de voordelen van mini-batch gradiëntdaling?
Antwoord:
Hieronder staan de voordelen van minidaling gradiëntdaling
• Dit is efficiënter in vergelijking met stochastische gradiëntdaling.
• De generalisatie door de vlakke minima te vinden.
• Mini-batches bieden hulp bij het benaderen van de gradiënt van de gehele trainingsset, wat ons helpt lokale minima te vermijden.
8. Wat is gegevensnormalisatie en waarom hebben we het nodig?
Antwoord:
Gegevensnormalisatie wordt gebruikt tijdens backpropagation. Het belangrijkste motief achter gegevensnormalisatie is het verminderen of elimineren van gegevensredundantie. Hier schalen we waarden opnieuw om in een specifiek bereik te passen om een betere convergentie te bereiken.
Laten we doorgaan naar de volgende Deep Learning-interviewvragen.
9. Wat is gewichtsinitialisatie in neurale netwerken?
Antwoord:
Gewichtsinitialisatie is een van de zeer belangrijke stappen. Een slechte gewichtsinitialisatie kan voorkomen dat een netwerk leert, maar een goede gewichtsinitialisatie helpt bij het geven van een snellere convergentie en een betere algemene fout. Biases kunnen in het algemeen op nul worden geïnitialiseerd. De regel voor het instellen van de gewichten moet bijna nul zijn zonder te klein te zijn.
10. Wat is een auto-encoder?
Antwoord:
Een autoencoder is een autonoom machine learning-algoritme dat het backpropagation-principe gebruikt, waarbij de doelwaarden gelijk zijn aan de verstrekte invoer. Intern heeft het een verborgen laag die een code beschrijft die wordt gebruikt om de invoer te vertegenwoordigen.
Enkele belangrijke feiten over de autoencoder zijn als volgt: -
• Het is een onbewaakt ML-algoritme vergelijkbaar met Principal Component Analysis
• Het minimaliseert dezelfde objectieve functie als Principal Component Analysis
• Het is een neuraal netwerk
• De doeluitvoer van het neurale netwerk is de invoer
11. Is het OK om van een Layer 4-uitgang terug te verbinden met een Layer 2-ingang?
Antwoord:
Ja, dit kan worden gedaan, gezien het feit dat de uitvoer van laag 4 uit de vorige tijdstap is, zoals in RNN. We moeten er ook van uitgaan dat de vorige invoerbatch soms gecorreleerd is met de huidige batch.
Laten we doorgaan naar de volgende Deep Learning-interviewvragen.
12. Wat is de Boltzmann-machine?
Antwoord:
Boltzmann Machine wordt gebruikt om de oplossing van een probleem te optimaliseren. Het werk van de Boltzmann-machine is in feite het optimaliseren van de gewichten en de hoeveelheid voor het gegeven probleem.
Enkele belangrijke punten over Boltzmann Machine -
• Het gebruikt een terugkerende structuur.
• Het bestaat uit stochastische neuronen, die bestaan uit een van de twee mogelijke toestanden, 1 of 0.
• De neuronen hierin bevinden zich ofwel in een adaptieve (vrije toestand) of geklemde (bevroren toestand).
• Als we gesimuleerde gloeiing toepassen op een discreet Hopfield-netwerk, wordt dit Boltzmann Machine.
13. Wat is de rol van de activeringsfunctie?
Antwoord:
De activeringsfunctie wordt gebruikt om niet-lineariteit in het neurale netwerk te introduceren, waardoor het complexere functies kan leren. Zonder welke het neurale netwerk alleen in staat zou zijn om een lineaire functie te leren die een lineaire combinatie is van zijn invoergegevens.
Aanbevolen artikelen
Dit is een leidraad geweest voor Lijst met Deep Learning Interview Vragen en Antwoorden zodat de kandidaat deze Deep Learning Interview Vragen gemakkelijk kan beantwoorden. U kunt ook de volgende artikelen bekijken voor meer informatie
- Leer de top 10 meest bruikbare HBase-interviewvragen
- Nuttige vragen en antwoorden over machinaal leren
- Top 5 meest waardevolle sollicitatievragen voor Data Science
- Belangrijke sollicitatievragen en antwoorden voor Ruby