

Inleiding tot de beperkte Boltzmann-machine
Beperkte Boltzmann-machine is een methode die automatisch patronen in gegevens kan vinden door onze invoer te reconstrueren. Geoff Hinton is de oprichter van deep learning. RBM is een oppervlakkig tweelaags netwerk waarin het eerste zichtbaar is en het volgende de verborgen laag. Elk knooppunt in de zichtbare laag is verbonden met elk knooppunt in de verborgen laag. Beperkte Boltzmann-machine wordt als beperkt beschouwd omdat twee knooppunten van dezelfde laag geen verbinding vormen. Een RBM is het numerieke equivalent van een tweewegvertaler. In het voorwaartse pad ontvangt een RBM de invoer en zet deze om in een reeks getallen die de invoer coderen. In het achterwaartse pad neemt het dit als resultaat en verwerkt deze set ingangen en vertaalt ze in omgekeerde richting om de teruggetrokken ingangen te vormen. Een supergetraind netwerk zal deze omgekeerde overgang met hoge waarheidsgetrouwheid kunnen uitvoeren. In twee stappen spelen gewicht en waarden een zeer belangrijke rol. Ze stellen RBM in staat om de onderlinge relaties tussen de ingangen te decoderen en helpen de RBM ook om te beslissen welke ingangswaarden het belangrijkst zijn bij het detecteren van de juiste uitgangen.
Werking van Beperkte Boltzmann-machine
Elk zichtbaar knooppunt ontvangt een lage niveauwaarde van een knooppunt in de gegevensset. Bij de eerste knoop van de onzichtbare laag wordt X gevormd door een gewichtsproduct en toegevoegd aan een voorspanning. De uitkomst van dit proces wordt aan activering toegevoerd die de kracht van het gegeven ingangssignaal of de uitgang van het knooppunt produceert.
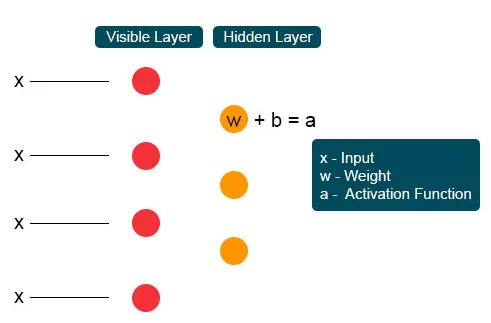
In het volgende proces zouden verschillende ingangen samenkomen op één verborgen knooppunt. Elke X wordt gecombineerd door het individuele gewicht, de toevoeging van het product wordt naar waarden geknuppeld en opnieuw wordt het resultaat door activering geleid om de uitvoer van de knoop te geven. Bij elke onzichtbare knoop wordt elke ingang X gecombineerd door individueel gewicht W. Ingang X heeft hier drie gewichten, waardoor er twaalf samen zijn. Het gewicht dat tussen de laag wordt gevormd, wordt een array waar rijen nauwkeurig zijn voor invoerknooppunten en kolommen voldoen aan uitvoerknooppunten.
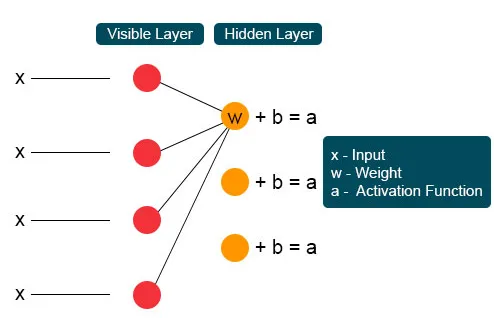
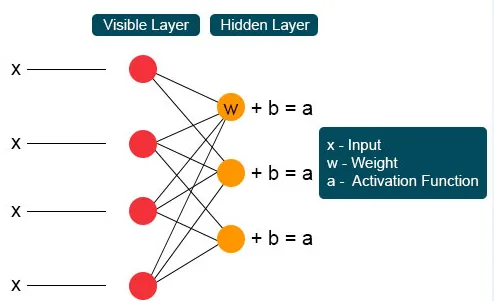
Elke onzichtbare knoop krijgt vier antwoorden vermenigvuldigd met hun gewicht. De toevoeging van dit effect wordt opnieuw toegevoegd aan de waarde. Dit fungeert als een katalysator voor een activeringsproces en het resultaat wordt opnieuw ingevoerd in het activeringsalgoritme dat elke output voor elke onzichtbare input produceert.
Het eerste model dat hier is afgeleid, is het op energie gebaseerde model. Dit model associeert scalaire energie met elke configuratie van de variabele. Dit model definieert de kansverdeling via een energiefunctie als volgt,
(1) 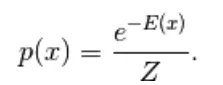
Hier is Z de normaliserende factor. Het is de partitiefunctie in termen van fysieke systemen
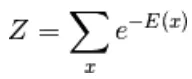
In deze op energie gebaseerde functie volgt een logistieke regressie dat de eerste stap de log zal definiëren. waarschijnlijkheid en de volgende definieert verliesfunctie als een negatieve waarschijnlijkheid.
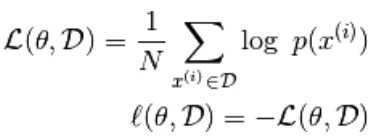
met behulp van het stochastische verloop, 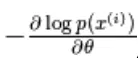 waar
waar 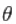 zijn de parameters,
zijn de parameters,
het op energie gebaseerde model met een verborgen eenheid wordt gedefinieerd als 'h'
Het geobserveerde deel wordt aangeduid als 'x'
Uit vergelijking (1) wordt de vergelijking van vrije energie F (x) als volgt gedefinieerd
(2) 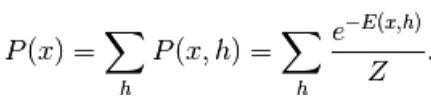
(3) 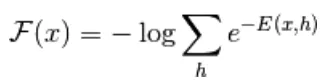
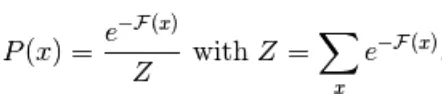
Het negatieve verloop heeft de volgende vorm,
(4) 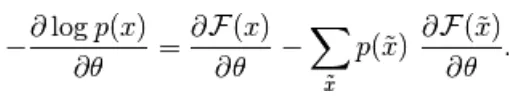
De bovenstaande vergelijking heeft twee vormen, de positieve en negatieve vorm. De term positief en negatief wordt niet weergegeven door tekens van de vergelijkingen. Ze tonen het effect van de waarschijnlijkheidsdichtheid. Het eerste deel toont de waarschijnlijkheid van het verminderen van de overeenkomstige vrije energie. Het tweede deel toont hoe de kans op gegenereerde monsters wordt verkleind. Vervolgens wordt het verloop als volgt bepaald,
(5) 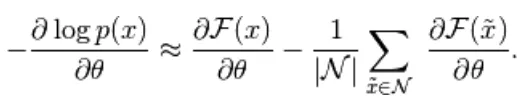
Hier is N negatieve deeltjes. In dit op energie gebaseerde model is het moeilijk om de gradiënt analytisch te identificeren, omdat deze de berekening van omvat 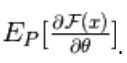
Daarom hebben we in dit EBM-model lineaire observatie die de gegevens niet nauwkeurig kan weergeven. Dus in het volgende model Beperkte Boltzmann-machine is de verborgen laag meer om een hoge nauwkeurigheid te hebben en gegevensverlies te voorkomen. De RBM-energiefunctie is gedefinieerd als,
(6) 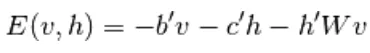
Hier is W gewichtsverbinding tussen zichtbare en verborgen lagen. b is offset van de zichtbare laag. c is offset van de verborgen laag. door om te zetten in gratis energie,
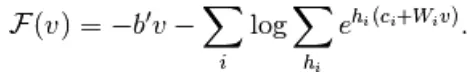
In RBM zijn de eenheden van de zichtbare en verborgen laag volledig onafhankelijk, die als volgt kunnen worden geschreven,
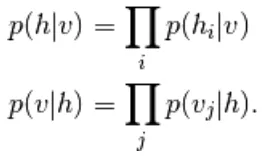
Uit vergelijking 6 en 2, een probabilistische versie van de neuron-activeringsfunctie,
(7) 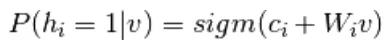
(8) 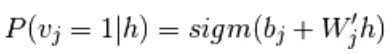
Het is verder vereenvoudigd in
(9) 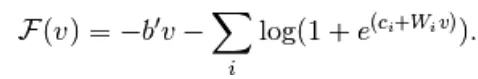
Vergelijking van 5 en 9,
(10) 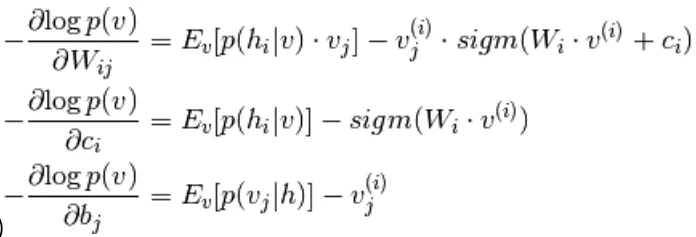
Bemonstering in Beperkte Boltzmann-machine
Gibbs-steekproef van het gewricht van N willekeurige variabelen 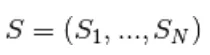 wordt gedaan door een reeks van N steekproefsubstappen van het formulier
wordt gedaan door een reeks van N steekproefsubstappen van het formulier 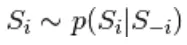 waar
waar
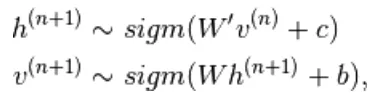
bevat 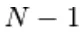 de andere willekeurige variabelen in
de andere willekeurige variabelen in 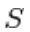 exclusief.
exclusief. 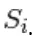
In RBM is S een reeks zichtbare en verborgen eenheden. De twee delen zijn onafhankelijk die Gibbs-bemonstering kunnen uitvoeren of blokkeren. Hier voert de zichtbare eenheid bemonstering uit en geeft verborgen eenheden een vaste waarde, terwijl verborgen eenheden door bemonstering vaste waarden aan de zichtbare eenheid gaven
hier, 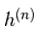 is een set van alle verborgen eenheden. Een voorbeeld
is een set van alle verborgen eenheden. Een voorbeeld 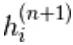 wordt willekeurig gekozen als 1 (versus 0) met waarschijnlijkheid,
wordt willekeurig gekozen als 1 (versus 0) met waarschijnlijkheid, 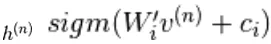 en op dezelfde manier
en op dezelfde manier 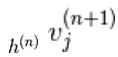 wordt willekeurig gekozen als 1 (versus 0) met waarschijnlijkheid
wordt willekeurig gekozen als 1 (versus 0) met waarschijnlijkheid 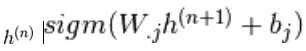
Contrastieve divergentie
Het wordt gebruikt als katalysator om het bemonsteringsproces te versnellen
Omdat we verwachten waar te zijn, verwachten we 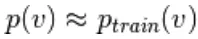 waarbij de distributiewaarde dicht bij P ligt, zodat deze een convergentie vormt met de uiteindelijke verdeling van P
waarbij de distributiewaarde dicht bij P ligt, zodat deze een convergentie vormt met de uiteindelijke verdeling van P
Maar contrastdivergentie wacht niet tot de ketting convergeert. Het monster wordt alleen verkregen na het proces van Gibb, dus stellen we hier k = 1 in waar het verrassend goed werkt.
Aanhoudende contrastverschillen
Dit is een andere methode voor benaderingssteekproefformulier. Het is een persistente toestand voor elke bemonsteringsmethode waarmee nieuwe monsters worden geëxtraheerd door eenvoudig de parameters van K te wijzigen.
Lagen van beperkte Boltzmann-machine
Beperkte Boltzmann-machine heeft twee lagen, ondiepe neurale netwerken die samen een blok van diepe geloofsnetwerken vormen. De eerste laag is de zichtbare laag en de andere laag is de verborgen laag. Elke eenheid verwijst naar een neuron-achtige cirkel die een knoop wordt genoemd. De knooppunten van de verborgen laag zijn verbonden met knooppunten van de zichtbare laag. Maar twee knooppunten van dezelfde laag zijn niet verbonden. Hier verwijst de term beperkt naar geen intralayer communicatie. Elk knooppunt verwerkt de invoer en neemt de stochastische beslissing om de invoer al dan niet te verzenden.
Voorbeelden
De belangrijke rol van RBM is een kansverdeling. Talen zijn uniek in hun letters en geluiden. De kansverdeling van de brief kan hoog of laag zijn. In het Engels worden de letters T, E en A veel gebruikt. Maar in het IJslands zijn de gemeenschappelijke letters A en N. we kunnen niet proberen het IJslands te reconstrueren met een op Engels gebaseerd gewicht. Het zal tot divergentie leiden.
Het volgende voorbeeld zijn afbeeldingen. De waarschijnlijkheidsverdeling van hun pixelwaarde verschilt voor elke soort afbeelding. We kunnen overwegen dat er twee afbeeldingen Olifant en Hond zijn voor slepeninvoerknooppunten, de voorwaartse doorgang van RBM zal vragen genereren zoals moet ik een sterke pixelknoop genereren voor een olifantsknoop of een hondenknoop? Dan zal de achteruitgang vragen genereren zoals voor olifanten, hoe moet ik een verdeling van pixels verwachten? Dan met gezamenlijke waarschijnlijkheid en activering geproduceerd door knooppunten, zullen ze een netwerk bouwen met gezamenlijk voorkomen zoals grote oren, grijze niet-lineaire buis, floppy oren, rimpel is de olifant. Vandaar dat RBM het proces is van diep leren en visualisatie. Ze vormen twee belangrijke vooroordelen en handelen op basis van hun activerings- en reconstructiegevoel.
Voordelen van Beperkte Boltzmann-machine
- Beperkte Boltzmann-machine is een toegepast algoritme dat wordt gebruikt voor classificatie, regressie, onderwerpmodellering, collaboratieve filtering en leren van functies.
- Beperkte Boltzmann-machine wordt gebruikt voor neuro-imaging, spaarzame beeldreconstructie in mijnplanning en ook bij radarherkenning
- RBM kan probleem van onevenwichtige gegevens oplossen met de SMOTE-procedure
- RBM vindt ontbrekende waarden door de steekproef van Gibb die wordt toegepast om de onbekende waarden te dekken
- RBM overwint het probleem van lawaaierige labels door niet-gecorrigeerde labelgegevens en de reconstructiefouten
- Het probleem ongestructureerde gegevens wordt verholpen door de functie-extractor die de onbewerkte gegevens omzet in verborgen eenheden.
Conclusie
Diep leren is zeer krachtig, wat de kunst is om complexe problemen op te lossen, het is nog steeds een ruimte voor verbetering en complex om te implementeren. Vrije variabelen moeten met zorg worden geconfigureerd. De ideeën achter het neurale netwerk waren eerder moeilijk, maar vandaag is diep leren de voet van machine learning en kunstmatige intelligentie. Daarom geeft RBM een glimp van de enorme algoritmen voor diep leren. Het gaat over de basiseenheid van compositie die geleidelijk uitgroeide tot vele populaire architecturen en op grote schaal werd gebruikt in veel grootschalige industrieën.
Aanbevolen artikel
Dit is een gids geweest voor de beperkte Boltzmann-machine. Hier bespreken we de werking, bemonstering, voordelen en Lagen van beperkte Boltzmann-machine. U kunt ook onze andere voorgestelde artikelen bekijken voor meer informatie _
- Machine Learning-algoritmen
- Machine Learning-architectuur
- Soorten machine learning
- Hulpmiddelen voor machine leren
- Implementatie van neurale netwerken