

Verschil tussen Map Reduce en Spark
Map Reduce is een open-source framework voor het schrijven van gegevens in HDFS en het verwerken van gestructureerde en ongestructureerde gegevens in HDFS. Map Reduce is beperkt tot batchverwerking en op andere Spark kan elk type verwerking worden uitgevoerd. SPARK is een onafhankelijke verwerkingsengine voor realtime verwerking die kan worden geïnstalleerd op elk gedistribueerd bestandssysteem zoals Hadoop. SPARK biedt een prestatie die 10 keer sneller is dan Map Reduce op schijf en 100 keer sneller dan Map Reduce op een netwerk in het geheugen.
Behoefte aan VONK
- Iteratieve analyse: Map-reductie is niet zo efficiënt als een SPARK om problemen op te lossen die iteratieve analyse vereisen, omdat het voor elke iteratie naar de schijf moet.
- Interactieve analyse: Map-reductie wordt vaak gebruikt om ad-hocquery's uit te voeren waarvoor het naar schijfgeheugen moet gaan dat weer niet zo efficiënt is als SPARK omdat dit laatste verwijst naar het in-geheugen dat sneller is.
- Niet geschikt voor OLTP: omdat het werkt op het batch-georiënteerde framework, is het niet geschikt voor een groot aantal van de korte transactie.
- Niet geschikt voor grafiek: de Apache Graph-bibliotheek verwerkt de grafiek die de Map Reduce complexer maakt.
- Niet geschikt voor triviale bewerkingen: voor bewerkingen zoals een filter en joins moeten we de taken wellicht herschrijven, wat complexer wordt vanwege het sleutel / waarde-patroon.
Head-to-Head vergelijking tussen Map Reduce vs Spark (Infographics)
Hieronder staat de top 15 Verschil tussen MapReduce en Spark

Belangrijkste verschillen tussen Map Reduceeren versus Spark
Hieronder staan de lijst met punten, beschrijf de belangrijkste verschillen tussen MapReduce en Spark:
- Spark is geschikt voor real-time omdat het verwerkt in het geheugen, terwijl MapReduce beperkt is tot batchverwerking.
- Spark heeft RDD (Resilient Distributed Dataset) die ons operatoren op hoog niveau biedt, maar in Map reduce moeten we elke bewerking coderen waardoor het relatief moeilijk wordt.
- Spark kan grafieken verwerken en ondersteunt de Machine learning tool.
- Hieronder is het verschil tussen MapReduce vs Spark ecosysteem.
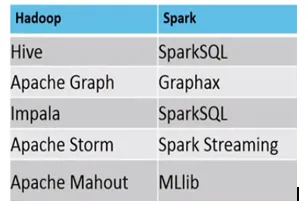
Voorbeeld, waar MapReduce vs Spark geschikt zijn, zijn als volgt
Spark: detectie van creditcardfraude
MapReduce: Regelmatige rapporten opstellen waarvoor besluitvorming vereist is.
Vergelijkingstabel MapReduce vs Spark
| Vergelijkingsbasis | MapReduce | Vonk |
| Kader | Een open-source framework voor het schrijven van gegevens in HDFS en het verwerken van gestructureerde en ongestructureerde gegevens in HDFS. | Een open-source framework voor snellere en algemene gegevensverwerking |
| Snelheid | Map-Reduce verwerkt de gegevens (lezen en schrijven) van schijf zodat het seep traag is in vergelijking met Spark. | Spark is minstens 10X sneller op schijf en 100X sneller in geheugen als die van Map Reduce. |
| moeilijkheid | We moeten elk proces coderen / verwerken. | Met de beschikbaarheid van RDD (Resilient Distributed Dataset) is het eenvoudig te programmeren. |
| Echte tijd | Niet geschikt voor OLTP-transacties alleen voor batchmodus | Het kan de realtime verwerking aan. SPARK Streaming gebruiken. |
| Wachttijd | Framework voor latentiecomputing op hoog niveau | Framework voor latentiecomputing op laag niveau. |
| Fouttolerantie | Master daemons controleren de hartslag van slave daemons en in het geval slave daemons falen master daemons herschikken alle lopende en lopende operatie naar een andere slave. | RDD's bieden fouttolerantie voor SPARK. Ze verwijzen naar de dataset die aanwezig is in externe opslag zoals (HDFS, HBase) en werken parallel. |
| Scheduler | In Map Reduce gebruiken we een externe planner zoals Oozie. | Omdat SPARK met in-memory computing werkt, fungeert het als zijn eigen planner. |
| Kosten | Map Reduce is relatief goedkoper in vergelijking met SPARK. | Omdat het in het geheugen werkt, vereist het veel RAM waardoor het relatief duurder is. |
| Platform ontwikkeld op | Map Reduce is ontwikkeld met behulp van Java. | SPARK is ontwikkeld met behulp van Scala. |
| Ondersteunde taal | Map Reduce ondersteunt in principe C, C ++, Ruby, Groovy, Perl, Python. | Spark ondersteunt Scala, Java, Python, R, SQL. |
| SQL-ondersteuning | Map Reduceer zoekopdrachten met Hive Query Language. | Spark heeft zijn eigen querytaal die bekend staat als Spark SQL. |
| schaalbaarheid | In Map Reduce kunnen we maximaal n aantal knooppunten toevoegen. De grootste Hadoop-cluster heeft 14000 knooppunten. | In Spark kunnen we ook n aantal knooppunten toevoegen. Het grootste Spark-cluster heeft 8000 knooppunten. |
| Machine leren | Map Reduce ondersteunt Apache Mahout-tool voor machine learning. | Spark ondersteunt MLlib-tool voor machine learning. |
| caching | Map verkleinen kan geheugengegevens niet opslaan in de cache, dus het is niet zo snel in vergelijking met Spark. | Spark slaat de gegevens in het geheugen op voor verdere iteraties, dus het is erg snel in vergelijking met Map Reduce. |
| Veiligheid | Map Reduce ondersteunt meer beveiligingsprojecten en functies in vergelijking met Spark | Vonkbeveiliging is nog niet gerijpt als die van Map Reduce |
Conclusie - MapReduce vs Spark
Volgens het bovenstaande verschil tussen MapReduce en Spark, is het vrij duidelijk dat SPARK een veel geavanceerdere computer is in vergelijking met Map Reduce. Spark is compatibel met elk type bestandsindeling en ook behoorlijk sneller dan Map Reduce. De vonk heeft bovendien ook grafische verwerking en machine learning-mogelijkheden.
Enerzijds is Map Reduce beperkt tot batchverwerking en anderzijds kan Spark elk type verwerking uitvoeren (batch, interactief, iteratief, streaming, grafiek). Vanwege de grote compatibiliteit is Spark de favoriet van Data Scientist en daarom vervangt het Map Reduce en groeit het snel. Maar toch moeten we de gegevens opslaan in HDFS en misschien hebben we soms ook HBase nodig. We moeten dus zowel Spark als Hadoop uitvoeren om de beste te krijgen.
Aanbevolen artikelen:
Dit is een leidraad geweest voor MapReduce vs Spark, hun betekenis, vergelijking van persoon tot persoon, belangrijkste verschillen, vergelijkingstabel en conclusie. U kunt ook de volgende artikelen bekijken voor meer informatie -
- 7 Belangrijke dingen over Apache Spark (gids)
- Hadoop vs Apache Spark - interessante dingen die u moet weten
- Apache Hadoop vs Apache Spark | Top 10 vergelijkingen die u moet weten!
- Hoe werkt MapReduce?
- Samenloop van technologie- en bedrijfsanalyses