

Overzicht van datamining-architectuur
Datamining is de manier om de basis- of gevorderde patronen te vinden en te verkennen in een gecompliceerde set van grote datasets waarbij de methoden op het snijvlak van statistieken, machine learning en ook databasesystemen worden gebruikt. Men kan zeggen dat het een interdisciplinair veld van statistiek en computerwetenschappen is, waarbij het doel is om de informatie met behulp van intelligente methoden en technieken uit een bepaalde set gegevens te extraheren door middel van extractie en daarmee de gegevens te transformeren. De gegevensbeheeractiviteiten en gegevensvoorbewerkingsactiviteiten samen met afwegingsoverwegingen worden ook in overweging genomen. In dit artikel gaan we diep in op de architectuur van datamining.
Datamining-architectuur
De datamining is de techniek om interessante kennis te extraheren uit een set enorme hoeveelheden data die vervolgens wordt opgeslagen in vele databronnen zoals bestandssystemen, datawarehouses, databases. De primaire componenten van de dataminingarchitectuur omvatten -
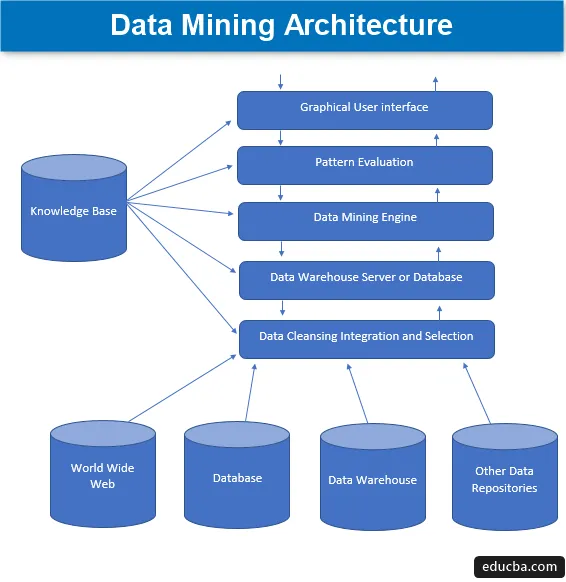
1. Gegevensbronnen
Een grote verscheidenheid aan huidige documenten zoals datawarehouse, database, www of in de volksmond een World wide web genoemd dat de feitelijke gegevensbronnen wordt. Meestal kan het ook zijn dat de gegevens niet aanwezig zijn in een van deze gouden bronnen, maar alleen in de vorm van tekstbestanden, gewone bestanden of reeksbestanden of spreadsheets en dan moeten de gegevens in een zeer op dezelfde manier als de verwerking zou plaatsvinden op basis van de gegevens ontvangen van gouden bronnen. Het grootste deel van de gegevens wordt tegenwoordig van internet of het world wide web ontvangen, omdat alles wat tegenwoordig op internet aanwezig is, gegevens in een of andere vorm zijn die een vorm van informatie-repository-eenheden vormen.
Voordat de gegevens worden verwerkt, omvatten de verschillende processen waarmee ze worden verwerkt gegevens opschonen, integreren en selecteren voordat de gegevens uiteindelijk worden doorgegeven aan de database of een van de EDW-servers (enterprise datawarehouse). De grote uitdaging die soms ligt bij deze set gegevens, is verschillende niveaus van bronnen en een breed scala aan gegevensindelingen die de gegevenscomponenten vormen. Daarom kunnen de gegevens niet direct worden gebruikt voor verwerking in de naïeve staat, maar op een veel meer bruikbare manier worden verwerkt, getransformeerd en vervaardigd. Op deze manier wordt ook de betrouwbaarheid en volledigheid van de gegevens gewaarborgd. De primaire stap omvat dus het verzamelen, opschonen en integreren van gegevens, en dat alleen de relevante gegevens worden doorgegeven. Al deze activiteit maakt deel uit van een afzonderlijke reeks hulpmiddelen en technieken.
2. Data Warehouse Server of Database
De databaseserver is de werkelijke ruimte waar de gegevens zich bevinden zodra ze zijn ontvangen van het verschillende aantal gegevensbronnen. De server bevat de feitelijke set gegevens die gereed is om te worden verwerkt en daarom beheert de server het ophalen van gegevens. Al deze activiteit is gebaseerd op het verzoek om datamining van de persoon.
3. Datamining-engine
In het geval van datamining vormt de motor de kerncomponent en is het belangrijkste onderdeel, oftewel de drijvende kracht die alle aanvragen afhandelt en beheert en wordt gebruikt om een aantal modules te bevatten. Het aantal aanwezige modules omvat mijnbouwtaken zoals classificatietechniek, associatietechniek, regressietechniek, karakterisering, voorspelling en clustering, tijdreeksanalyse, naïeve Bayes, ondersteuning van vectormachines, ensemble-methoden, boosting- en bagging-technieken, willekeurige bossen, beslissingsbomen, enz.
4. Patroonevaluatiemodules
Deze evaluatietechniek van de modules is voornamelijk verantwoordelijk voor het meten van de interessantheid van al die patronen die worden gebruikt voor het berekenen van het basisniveau van de drempelwaarde en wordt ook gebruikt om te communiceren met de datamining-engine om te coördineren bij de evaluatie van andere modules. Al met al is het hoofddoel van dit onderdeel om te zoeken naar en zoeken naar alle interessante en bruikbare patronen die de gegevens van een relatief betere kwaliteit kunnen maken.
5. Grafische gebruikersinterface
Wanneer de gegevens worden gecommuniceerd met de motoren en bij verschillende patroonevaluaties van modules, wordt het een noodzaak om te communiceren met de verschillende aanwezige componenten en het gebruiksvriendelijker te maken zodat een efficiënt en effectief gebruik van alle aanwezige componenten kan worden gemaakt en daarom ontstaat de behoefte aan een grafische gebruikersinterface die in de volksmond GUI wordt genoemd.
Dit wordt gebruikt om een gevoel van contact tussen de gebruiker en het datamining-systeem tot stand te brengen, waardoor gebruikers worden geholpen het systeem efficiënt en gemakkelijk te benaderen en te gebruiken om hen vrij te houden van enige complexiteit die zich tijdens het proces heeft voorgedaan. Dit is een vorm van abstractie waarbij alleen de relevante componenten worden getoond aan de gebruikers en alle complexiteiten en functionaliteiten die verantwoordelijk zijn voor het bouwen van het systeem zijn verborgen omwille van de eenvoud. Wanneer de gebruiker een vraag indient, werkt de module vervolgens samen met de algehele set van een datamining-systeem om een relevante output te produceren die gemakkelijk aan de gebruiker op een veel begrijpelijkere manier kan worden getoond.
6. Kennisbank
Dit is de component die de basis vormt van het algehele dataminingproces, omdat het helpt bij het begeleiden van de zoektocht of bij de evaluatie van de interessantheid van de gevormde patronen. Deze kennisbank bestaat uit overtuigingen van gebruikers en ook de gegevens verkregen uit gebruikerservaringen die op hun beurt nuttig zijn in het dataminingproces. De motor kan zijn set inputs ontvangen uit de gecreëerde kennisbasis en biedt daardoor efficiëntere, nauwkeurigere en betrouwbaardere resultaten.
Datamining is tegenwoordig een van de belangrijkste technieken die betrekking hebben op gegevensbeheer en gegevensverwerking die de ruggengraat van elke organisatie vormt. Analyse van gegevens in elke organisatie zal vruchtbare resultaten opleveren. Elk onderdeel van de dataminingtechniek en -architectuur heeft zijn eigen manier om verantwoordelijkheden uit te voeren en ook om datamining efficiënt te voltooien. De verschillende modules zijn nodig om correct te interageren om een waardevol resultaat te produceren en de complexe procedure van datamining met succes te voltooien door de juiste set informatie aan het bedrijf te verstrekken.
Aanbevolen artikelen
Dit is een gids voor dataminingarchitectuur. Hier bespreken we de primaire componenten van de datamining-architectuur. U kunt ook onze andere voorgestelde artikelen doornemen voor meer informatie -
- Data Mining Tool
- Voordelen van datamining
- Wat is clustering in datamining?
- Vragen en antwoorden over HTML5-sollicitatiegesprekken
- Meest gebruikte technieken van ensemble leren
- Algoritmen van modellen in datamining