
Verschillen tussen Data Science versus Data Visualization
Data science : een kunst van het interpreteren van de gegevens en het verkrijgen van inzichten uit de gegevens. Het is ook een studie van observaties en interpretatie voor een beter resultaat.
Gegevensvisualisatie: weergave van de gegevens. Gegevenswetenschappers hebben hulpmiddelen nodig om met de gegevens om te gaan. Wat kan daar het beste uit halen? Hoe kan het worden afgebroken? Hoe is de ene parameter gecorreleerd met de andere? Al deze vragen worden beantwoord met een van de oplossingen: tutorials voor datavisualisatie.
Het beste voorbeeld van data science op onze dagelijkse basis is de aanbeveling van Amazon voor een gebruiker tijdens het winkelen. De machine leert over de webactiviteit van een gebruiker en interpreteert en manipuleert deze dus door de beste aanbeveling te geven op basis van uw interesses en winkelkeuze. Om deze aanbeveling te geven, vertegenwoordigen (visualiseren) de gegevenswetenschappers de webactiviteit van de gebruiker en analyseren ze om de beste keuzes voor de gebruiker te bieden.
Data science en data visualisatie zijn geen twee verschillende entiteiten. Ze zijn aan elkaar gebonden. Datavisualisatie is een subset van data science. Data science is geen enkel proces of een methode of een workflow. Het is een gecombineerd effect van kleine miniaturen die met de gegevens omgaan. Of het nu een proces is van dataminingtechnieken, de EDA, modellering, representatie.
Use-case
Voorbeeld : om elk incident / verhaal in onze dagelijkse basis weer te geven, zou het als een toespraak kunnen worden overgebracht, maar wanneer het visueel wordt weergegeven, wordt de echte waarde ervan vastgesteld en begrepen.
Het gaat ook niet alleen om het weergeven van het uiteindelijke resultaat, maar ook om inzicht in de onbewerkte gegevens. Het is altijd beter om de gegevens weer te geven om betere inzichten te krijgen en het probleem op te lossen of om er zinvolle informatie uit te halen die het systeem beïnvloedt.
Voor een beter begrip van data science en data visualisatie,
Laten we zeggen dat we willen voorspellen wat de iPhone-verkoop voor het jaar 2018 zal zijn,
Hoe kan men precies de verkoop in de toekomst voorspellen? Wat zijn de vereisten, hoe vertrouwen is uw voorspelling, wat is het foutenpercentage? Al deze worden beantwoord en gerechtvaardigd met behulp van data science.
Vereisten voor een voorspelling ,
1. Historische gegevens - iPhone-verkopen uit het jaar 2010 - 2017
2. Aankoopgeschiedenis op locatieniveau
3. Gebruikersgegevens zoals leeftijd, enz
3. Belangrijkste factoren - Recente veranderingen in organisatie, recente marktwaarde en klantbeoordelingen van de afgelopen verkoop
wanneer de historische gegevens goed worden geploegd, zullen er veel attributen worden overwogen om de machine voor te bereiden om de voorspelling te maken.
Een belangrijke sleutel om voorspellingen of categorisaties of analyses uit te voeren, is altijd een beter beeld van de invoergegevens te hebben. Hoe meer u de gegevens begrijpt, des te beter de voorspelling.
Hoe goed kan men meer inzichten krijgen uit de historische gegevens? De beste manier is om het te visualiseren.
Datavisualisatie speelt een sleutelrol in twee fasen
- De eerste fase van analyse (dwz representeer de beschikbare gegevens en concludeer welke attributen en parameters moeten worden gebruikt om een voorspellende machine te bouwen). Dit stimuleert de datawetenschapper om de oplossing met verschillende benaderingen te bieden. Dus hier in ons voorbeeld is het historische gegevensrepresentatie welk historische jaar het beste kan worden gekozen voor analyse. Dit wordt besloten op basis van de visualisatie.
- Twee - resultaat. De voorspellingsresultaten voor het jaar 2018 moeten zodanig worden weergegeven dat deze de wereld bereiken. Vergelijking tussen telefoon- en google-pixelverkopen voor de komende jaren. Het zal leiden tot betere besluitvorming voor de organisaties.
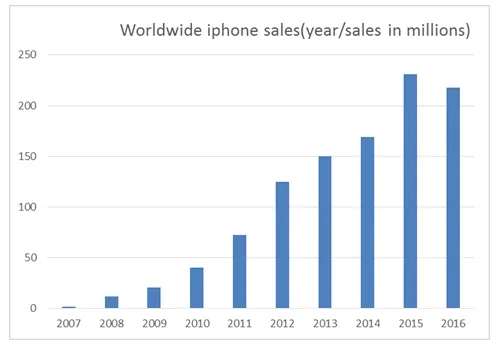
Terug naar de iPhone-analyse, moeten de historische gegevens worden geanalyseerd en de beste attributen kiezen die een significante invloed hebben op de voorspellingsgraad (zoals verkoop op locatie, seizoen, leeftijd).
Gevolgd door het beste model op te pikken (algoritmen zoals lineaire regressie, logistieke regressie,
en ondersteuning van vectormachines - om er maar een paar te noemen). Train het model met behulp van de historische gegevens en krijg de voorspelling voor het komende jaar. Dit is een beeld op hoog niveau van de processen die betrokken zijn bij de gegevenswetenschap.
Zodra de voorspellingsresultaten voor het komende jaar zijn vastgesteld, kunnen deze worden weergegeven en enkele inzichten krijgen die de verkoop- en marketingtechnieken van een product beïnvloeden.
Head to Head-vergelijking tussen Data Science versus Data Visualization (Infographics)
Hieronder vindt u de Top 7-vergelijking tussen Data Science en Data Visualization. 
Belangrijkste verschillen tussen Data Science versus Data Visualization
- Gegevenswetenschap bestaat uit meerdere statistische oplossingen om een probleem op te lossen, terwijl visualisatie een techniek is waarbij gegevenswetenschappers deze gebruiken om de gegevens te analyseren en het eindpunt weer te geven.
- Data science gaat over algoritmen om de machine te trainen (automatisering - Geen menselijke kracht, de machine zal simuleren als de mens om veel handmatige processen te verminderen. Het gaat om observatie en interpretatie van de activiteit). Datavisualisatie gaat over grafieken, plotten en het beste model kiezen op basis van weergave.
Vergelijkingstabel tussen Data Science versus Data Visualization
Hieronder staan de lijst met punten, beschrijf de vergelijking tussen Data Science en Data Visualization
| Basis voor vergelijking | Data science | Data visualisatie |
| Concept | Inzichten over de gegevens. Uitleg van de gegevens. Voorspelling, feiten | Weergave van de gegevens (zij het een bron of de resultaten) |
| Toepassing / gebruikscasussen | Volgende wereldbekervoorspelling, geautomatiseerde auto's | Kritieke Prestatie Indicatoren, Organisatiestatistieken |
| Wie doet dit? | Gegevenswetenschappers, gegevensanalisten, wiskundigen | Gegevenswetenschappers, UI / UX |
| Gereedschap | Python, Matlab, R (om er maar een paar te noemen) | Tableau, SAS, Power BI, d3 js (om er maar een paar te noemen). Python en R hebben ook bibliotheken om plots en grafieken te genereren. |
| Werkwijze | Dataverzameling, data mining, data munging, data opschoning, modellering, meting | Vertegenwoordig het in om het even welke grafiekvorm of grafieken |
| Hoe belangrijk | Veel organisaties vertrouwen op gegevenswetenschappelijke resultaten voor het nemen van beslissingen. | Het helpt datawetenschappers bij het begrijpen van de bron en het oplossen van het probleem of het doen van aanbevelingen. |
| Vaardigheden | Statistieken, algoritmen | Gegevensanalyse en plottechnieken. |
Conclusie - Data Science versus Data Visualization
Er zijn veel perspectieven als het gaat om data science. Op een gemakkelijke manier om te benaderen, is het hoe een probleem op te lossen in verschillende gevallen, het is een voorspelling, categorisatie, aanbevelingen, sentimentanalyse. Kortom, dit alles zou kunnen worden bereikt met behulp van de statistische manier van probleemoplossing. Het is een combinatie van (machine learning, deep learning, neurale netwerken, NLP, data mungling etc)
Datavisualisatie vormt een belangrijk ingrediënt bij het oplossen van de problemen. Het is een foto voor je script (in de term van de leek).
Aanbevolen artikel
Dit is een leidraad geweest voor verschillen tussen data science versus datavisualisatie, hun betekenis, vergelijking van persoon tot persoon, belangrijkste verschillen, vergelijkingstabel en conclusie. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Leer 5 nuttige vergelijkingen tussen data science en statistieken
- Data Science versus kunstmatige intelligentie - 9 Geweldige vergelijking
- Datavisualisatie versus business intelligence - welke is beter
- Beste gids voor datavisualisatie met Tableau