
Inleiding tot Data Lake versus Data Warehouse
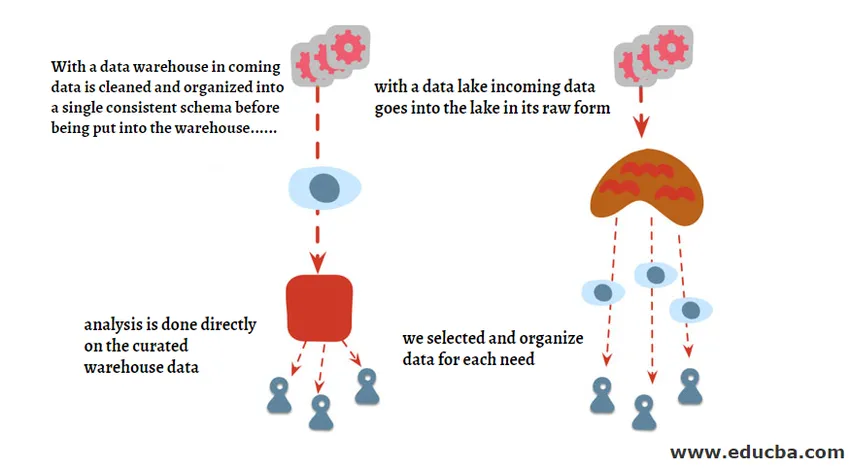
Data Lake versus Data Warehouse zijn de termen die door elkaar worden gebruikt, maar er zijn verschillen tussen beide termen. We hebben het onderstaande diagram gepresenteerd om het verschil op hoog niveau tussen deze twee te begrijpen en zeer binnenkort zullen we in detail gaan voor elk ervan.
Wat is Data Lake?
Een Data Lake is een soort opslagrepository die alleen uit onbewerkte gegevens bestaat in de vorm van een gestructureerd, semi-gestructureerd en ongestructureerd formaat. Het datameer wordt meestal gebruikt door Data Scientists en Machine Learning Engineers omdat het hen helpt vragen te beantwoorden die nog niet zijn beantwoord of misschien een vraag te creëren die nog niet bekend is. Het bevat een enorme hoeveelheid gegevens met verschillende typen en wanneer ze zijn geïntegreerd, blijken ze zeer nuttig te zijn in termen van voorspellende modellering die meestal wordt gebruikt om modellen voor machinaal leren te bouwen.
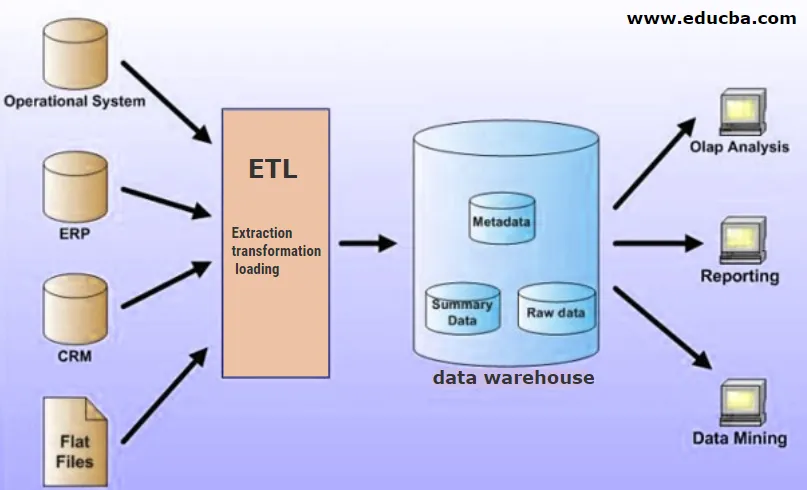
Wat is een datawarehouse?
Een datawarehouse is een gecentraliseerde locatie voor het opslaan van de getransformeerde gegevens die in een gestructureerd formaat zijn gemaakt voordat deze in het datawarehouse worden opgeslagen. Een gegevensmagazijn kan gegevens uit meerdere gegevensbronnen hebben die via het ETL-proces in het magazijn worden geladen en vervolgens voor Business Intelligence-doeleinden worden gebruikt.
Head to Head-vergelijking tussen Data Lake versus Data Warehouse (Infographics)
Hieronder staan de 14 belangrijkste verschillen tussen Data Lake en Data Warehouse 
Belangrijkste verschillen
Er zijn grote belangrijke verschillen tussen data lake versus datawarehouse:
- Het bestaat uit ongestructureerde en gestructureerde gegevens van verschillende platforms zoals sensoren, applicaties en websites, enz. Het bestaat voornamelijk uit relationele gegevens uit RDBMS, DBMS-systemen en andere operationele databases en applicaties.
- Data Lake is schema-on-read-verwerking. Het datawarehouse is schema-on-write-verwerking.
- Het is zeer behendig. Het is minder wendbaar.
- De configuratie is eenvoudig en kan worden aangepast aan wijzigingen. Het heeft een vaste configuratie en is erg moeilijk te veranderen.
- Het wordt meestal gebruikt door AI-wetenschappers en professionals in Machine Learning. Het wordt gebruikt door zakelijke professionals.
Vergelijkingstabel tussen Data Lake en Data Warehouse:
Laten we het grootste verschil bespreken tussen Data Lake en Data Warehouse
| Kenmerken | Data Lake | Data Warehouse |
| opslagruimte | Gegevens worden in onbewerkte vorm bewaard in Data Lake en hier worden alle gegevens bewaard, ongeacht de bron van de gegevens. Ze worden alleen omgezet in andere vormen wanneer dat nodig is. | Data Warehouse bestaat uit gegevens die worden geëxtraheerd uit transactionele en andere metrieksystemen. Hier zijn de gegevens niet in onbewerkte vorm en worden ze altijd getransformeerd en schoon. |
| Gebruik en doel | Het belangrijkste doel van Data Lake is Data Scientists, Big Data Developers en Machine Learning Engineers die diepgaande analyses moeten uitvoeren om modellen voor het bedrijf te maken, zoals voorspellende modellen. | Het belangrijkste doel van Data Warehouse zijn de operationele gebruikers, aangezien deze gegevens in een gestructureerd formaat zijn en klaar zijn om rapporten te maken. Dus ze worden meestal gebruikt voor business intelligence. |
| Gegevensinvoer | De belangrijkste input voor Data Lake zijn allerlei soorten gegevens, zoals gestructureerde, semi-gestructureerde en ongestructureerde gegevens. Deze gegevens bevinden zich in data Lake in hun oorspronkelijke vorm. | De belangrijkste input voor Datawarehouse zijn gestructureerde gegevens die afkomstig zijn van transactionele en metrische systemen die vervolgens worden georganiseerd in de vorm van schema's. |
| Data kwaliteit | Bestaat uit onbewerkte gegevens die al dan niet worden beheerd. | Het bestaat uit beheerde gegevens die zijn gecentraliseerd en klaar zijn om te worden aangeklaagd voor business intelligence en analytische doeleinden. |
| Normalisatie | Hier zijn de gegevens niet in genormaliseerde vorm. | Gedenormaliseerde schema's |
| Geschiedenis | De technologieën die worden gebruikt in datameren zoals Hadoop en Machine Learning zijn relatief nieuw in vergelijking met het datawarehouse. | Hier is de technologie die wordt gebruikt voor een datawarehouse ouder. |
| Tijdlijn van gegevens | Een datameer kan allerlei soorten gegevens bevatten en kan worden gebruikt met het oog op verleden, heden en prospects. | Wat Data Warehouse betreft, wordt hier het grootste deel van de tijd besteed aan het analyseren van verschillende gegevensbronnen. |
| Verwerkingstijd | Hier is de verwerkingstijd tijdens het analyseren en verkrijgen van resultaten van Data Lake veel kleiner dan die van Data Warehouse omdat hier de gegevens worden opgeslagen in de vorm van onbewerkte gegevens en die niet in getransformeerde indeling zijn en waardoor we de tijd hebben verkort die mogelijk worden besteed aan het transformeren van de gegevens. We kunnen de gegevens gewoon ophalen zoals ze zijn en wat basis opschonen en beginnen met het bouwen van onze modellen. | In het geval van Datawarehouse is de verwerkingstijd meer in vergelijking met het datameer. De reden hiervoor is dat de gegevens in elk datawarehouse eerst moeten worden getransformeerd en vervolgens kunnen worden geanalyseerd. |
| Kosten van opslag | De opslagkosten hier in datameertechnologieën zijn relatief lager dan die van het datawarehouse en zijn ook minder tijdrovend. | De opslagkosten in datawarehouse-technologieën zijn hoger dan in het datameer. Dit komt omdat het meer opslag nodig heeft voor de getransformeerde gegevens omdat het eerst de onbewerkte gegevens moet opslaan en vervolgens moet transformeren om verschillende velden toe te wijzen volgens de structuur van het Data Warehouse. |
| Compatibiliteit | Hier worden gegevens altijd in de onbewerkte indeling bewaard en alleen getransformeerd als dat nodig is of klaar is voor gebruik. | Hier worden de gegevens in getransformeerde indeling opgeslagen en kunnen we problemen ondervinden wanneer we proberen wijzigingen aan te brengen. |
| Toegankelijkheid | Gegevens in het gegevensmeer zijn zeer toegankelijk en kunnen snel worden bijgewerkt. | Gegevens in het datawarehouse zijn ingewikkelder en het vereist meer kosten om wijzigingen aan te brengen, de toegankelijkheid is ook beperkt tot alleen geautoriseerde gebruikers. |
| Positie van het schema | Schema wordt meestal gemaakt nadat de gegevens zijn opgeslagen. Dit brengt een hoge behendigheid met zich mee. | Hier wordt het schema meestal vóór de gegevensopslag gemaakt. |
| Proces van verwerking | Het gegevensmeer maakt gebruik van het ELT-proces, namelijk Extraheren, Laden en Transformeren. | Het datawarehouse maakt gebruik van de traditionele aanpak van ETL, namelijk Extraheren, Transformeren en Laden. |
| Voordelen | Datameer leidt tot nieuwe uitvindingen omdat de integratie verschillende soorten gegevens samenbrengt en ook antwoorden biedt op veel onbeantwoorde vragen. | De meeste gebruikers van de organisatie zijn betrokken bij operationele activiteiten en het datawarehouse biedt zo'n briljant platform om rapporten en statistieken te maken bovenop getransformeerde gegevens. |
Conclusie
In dit bericht hebben we kennis gemaakt met Data Lakes vs Data Warehouse. We gingen ook door en vergeleken beide op basis van verschillende parameters. Dit moet elke leerling helpen een basisidee te krijgen achter de technologieën die Data Lake en Data Warehouse ondersteunen.
Aanbevolen artikelen
Dit is een leidraad geweest voor het grootste verschil tussen Data Lake en Data Warehouse. Hier hebben we de belangrijkste verschillen tussen Data Lake en Data Warehouse met infographics en vergelijkingstabel besproken. U kunt ook de volgende artikelen bekijken voor meer informatie -
- Scrum vs Waterfall - Topverschillen
- MySQL vs MySQLi - Welke is beter?
- Microprocessor versus Microcontroller
- Sollicitatievragen voor Data Modeling