
Inleiding tot R CSV-bestanden
CSV-bestanden worden veel gebruikt om de informatie in tabelvorm op te slaan, waarbij elke regel gegevens registreert. Om gegevens in R te kunnen lezen, schrijven of manipuleren, moeten we enkele gegevens bij de hand hebben. Gegevens kunnen op internet worden gevonden of kunnen worden verzameld uit verschillende bronnen, zoals enquêtes. Met behulp van R kan men de gegevens lezen, schrijven en bewerken die zijn opgeslagen in een externe omgeving. R kan gegevens lezen en schrijven vanuit verschillende formaten, zoals XML, CSV en Excel. In dit artikel zullen we zien hoe R kan worden gebruikt om verschillende bewerkingen op CSV-bestanden te lezen, schrijven en uitvoeren.
CSV-bestand maken in R
In deze sectie zullen we zien hoe een dataframe kan worden gemaakt en geëxporteerd naar het CSV-bestand in R. In de eerste zullen we een dataframe maken dat bestaat uit variabelen werknemer en respectief salaris.
> df <- data.frame(Employee = c('Jonny', 'Grey', 'Mouni'),
+ Salary = c(23000, 41000, 32344))
> print (df)
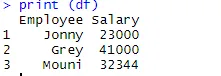
Zodra het dataframe is gemaakt, wordt het tijd dat we de exportfunctie van R gebruiken om een CSV-bestand in R te maken. Om het dataframe naar CSV te exporteren, kunnen we de onderstaande code gebruiken.
> write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv', row.names = FALSE)
In de bovenstaande coderegel hebben we een padmap voor onze gegevensfame opgegeven en het dataframe opgeslagen in CSV-indeling. In het bovenstaande geval werd het CSV-bestand opgeslagen op mijn persoonlijke bureaublad. Dit specifieke bestand zal in onze tutorial worden gebruikt voor het uitvoeren van meerdere bewerkingen.
CSV-bestanden lezen in R
Tijdens het uitvoeren van analyses met behulp van R, zijn we in veel gevallen verplicht om de gegevens uit het CSV-bestand te lezen. R is zeer betrouwbaar tijdens het lezen van CSV-bestanden. In het bovenstaande voorbeeld hebben we het bestand gemaakt dat we zullen gebruiken om te lezen met de opdracht read.csv. Hieronder is het voorbeeld om dit te doen in R.
> df <- read.csv(file="C:\\Users\\Pantar User\\Desktop\\Employee.csv", header=TRUE,
sep=", ")
> df

De bovenstaande opdracht leest het bestand Employee.csv dat beschikbaar is op desktop en geeft dat weer in R studio. Het commando koptekst houdt in dat de koptekst beschikbaar wordt gemaakt voor de gegevensset en het commando sep betekent dat de gegevens worden gescheiden door komma's.
Schrijf CSV-bestanden in R
Schrijven naar CSV-bestand is een van de meest bruikbare functionaliteiten die in R beschikbaar zijn voor een data-analist. Dit kan worden gebruikt om een bewerkt CSV-bestand naar een nieuw CSV-bestand te schrijven om de gegevens te analyseren. De opdracht Write.csv wordt gebruikt om het bestand naar CSV te schrijven.
In de onderstaande code df in het gegevensframe waarin onze gegevens beschikbaar zijn, wordt append gebruikt om aan te geven dat het nieuwe bestand wordt gemaakt in plaats van het oude bestand toe te voegen of te overschrijven. Voeg false toe suggereert dat er een nieuw CSV-bestand is gemaakt. Sep staat voor het veld gescheiden door een komma.
# Writing CSV file in R
write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv' append = FALSE, sep = “, ”)
CSV-operaties
CSV-bewerkingen zijn vereist om de gegevens te inspecteren nadat ze in het systeem zijn geladen. R heeft verschillende ingebouwde functionaliteiten om de gegevens te verifiëren en inspecteren. Deze bewerkingen bieden volledige informatie over de gegevensset.
Een van de meest gebruikte opdrachten is een samenvatting.
> summary(df)
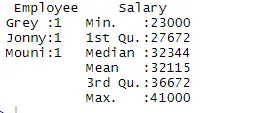
Het samenvattingscommando biedt ons kolomstatistieken. De numerieke variabele wordt op een statistische manier beschreven, inclusief statistische resultaten zoals gemiddelde, min, mediaan en max. In het bovenstaande voorbeeld worden twee variabelen, die werknemer en salaris zijn, gescheiden en worden statistieken voor de numerieke variabele die salaris is, aan ons getoond.
De opdracht View () wordt gebruikt om de gegevensset op een ander tabblad te openen en handmatig te verifiëren.
> View(df)

De functie Str biedt gebruikers meer informatie over de kolom van de gegevensset. In het onderstaande voorbeeld kunnen we zien dat de variabele Werknemer Factor als gegevenstype heeft en de variabele Salaris int (geheel getal) als gegevenstype.
> str(df)

In veel gevallen moeten we het totale aantal beschikbare rijen zien in het geval van de grote gegevensset, waarvoor we de opdracht nrow () kunnen gebruiken. Zie het onderstaande voorbeeld.
> # to show the total number of rows in the dataset
> nrow(df)

Op een vergelijkbare manier om het totale aantal kolommen weer te geven, kunnen we de opdracht ncol () gebruiken
> ncol(df)

Met R kunnen we het gewenste aantal rijen weergeven met behulp van onderstaande opdracht. Wanneer hun n aantal rijen beschikbaar is in de gegevensset, kunnen we het bereik van de rijen specificeren dat moet worden weergegeven.
> # to display first 2 rows of the data
> df(1:2, )

Gegevensbewerking wordt uitgevoerd op de grote gegevensset. Ter illustratie heb ik NI postcode open-source dataset van internet gedownload.
> NiPostCode <- read.csv("NIPostcodes.csv", na.strings="", header=FALSE)
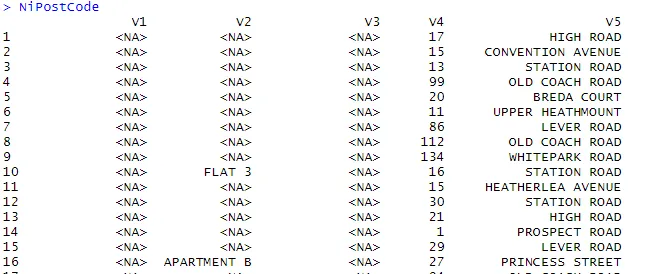
In de bovenstaande gegevensset zien we dat de kopnamen ontbreken en dat er veel nulwaarden aanwezig zijn. De gegevensset moet worden schoongemaakt om gereed te zijn voor analyse. In de volgende stap worden de koppen dienovereenkomstig namen.
> # adding headers/title
> names(NiPostCode)(1) <-"OrganisationName"
> names(NiPostCode)(2) <-"Sub-buildingName"
> names(NiPostCode)(3) <-"BuildingName"
> names(NiPostCode)(4) <-"Number"
> names(NiPostCode)(5) <-"Location"
> names(NiPostCode)(6) <-"Alt Thorfare"
> names(NiPostCode)(7) <-"Secondary Thorfare"
> names(NiPostCode)(8) <-"Locality"
> names(NiPostCode)(9) <-"Townland"
> names(NiPostCode)(10) <-"Town"
> names(NiPostCode)(11) <-"County"
> names(NiPostCode)(12) <-"Postcode"
> names(NiPostCode)(13) <-"x-coordinates"
> names(NiPostCode)(14) <-"y-coordinates"
> names(NiPostCode)(15) <-"Primary Key"

Laten we nu het aantal ontbrekende waarden in het dataframe tellen en deze vervolgens dienovereenkomstig verwijderen.
> # count of all missing values
> table(is.na (NiPostCode))

Uit de bovenstaande opdracht zien we dat het totale aantal lege cellen of NA in het dataframe bijna 5445148 is. Het verwijderen van alle null-waarden leidt tot verlies van de enorme hoeveelheid gegevens, daarom is het verstandig om de kolommen te verwijderen waarvan meer dan de helft van 50% gegevens ontbreekt.
> # delete columns with more than 50% missing values
> NiPostcodes 0.5)) > (NiPostcodes)
Conclusie
In deze zelfstudie hebben we gezien hoe CSV-bestanden kunnen worden gemaakt, gelezen en toegevoegd met behulp van bewerkingen in R. We hebben geleerd hoe we een nieuwe gegevensset in R kunnen maken en deze vervolgens kunnen importeren in CSV-formaat. We hebben verder meerdere bewerkingen gezien, zoals het hernoemen van de koptekst en het tellen van het aantal rijen en kolommen.
Aanbevolen artikelen
Dit is een handleiding voor R CSV-bestanden. Hier bespreken we het maken, lezen en schrijven van CSV-bestanden in R met CSV Operations. U kunt ook het volgende artikel bekijken voor meer informatie -
- JSON versus CSV
- Datamining-proces
- Carrières in data-analyse
- Excel versus CSV