

Inleiding tot ANOVA in R
Het volgende artikel ANOVA in R biedt een overzicht voor het vergelijken van de gemiddelde waarde van verschillende groepen. Een variantieanalyse (ANOVA) is een veel voorkomende techniek die wordt gebruikt om de gemiddelde waarde van verschillende groepen te vergelijken. ANOVA-model wordt gebruikt voor het testen van hypothesen, waarbij een bepaalde veronderstelling of parameter wordt gegenereerd voor een populatie en de statistische methode wordt gebruikt om te bepalen of de hypothese waar of onwaar is.
De hypothese is afgeleid van de veronderstelling van de onderzoeker en beschikbare informatie over de populatie. ANOVA wordt een variantieanalyse genoemd en gebruikt voor het testen van hypotheses waarbij middelen van een variabele in meerdere onafhankelijke groepen moeten worden gemeten.
In een laboratorium bijvoorbeeld om een nieuw medicijn voor obesitas te bestuderen of uit te vinden, vergelijken onderzoekers het resultaat van experimentele en standaardbehandeling. In een onderzoek naar obesitas kunnen waardevolle resultaten worden afgeleid wanneer het gemiddelde percentage obesitas van de bevolking in verschillende leeftijdsgroepen kan worden vergeleken. In dit geval zou men het gemiddelde obesitaspercentage onder verschillende leeftijdsgroepen, zoals leeftijd (5 tot 18), (19, 35) en (36 tot 50), willen observeren. De ANOVA-methode wordt toegepast omdat er meer dan twee groepen zijn die onafhankelijk zijn. ANOVA-methode wordt gebruikt om de gemiddelde zwaarlijvigheid van de onafhankelijke groepen te vergelijken. De functie aov () wordt gebruikt en Syntaxis is aov (formule, data = dataframe) In dit artikel zullen we meer te weten komen over het ANOVA-model en zullen we het ANOVA-model in één en twee richtingen verder bespreken met voorbeelden.
Waarom ANOVA?
- Deze techniek wordt gebruikt om de hypothese te beantwoorden tijdens het analyseren van meerdere groepen gegevens. Er zijn meerdere statistische benaderingen, maar de ANOVA in R wordt toegepast wanneer vergelijking op meer dan twee onafhankelijke groepen moet worden uitgevoerd, zoals in ons vorige voorbeeld drie verschillende leeftijdsgroepen.
- ANOVA-techniek meet het gemiddelde van de onafhankelijke groepen om onderzoekers het resultaat van de hypothese te geven. Om nauwkeurige resultaten te krijgen, moet rekening worden gehouden met steekproefgemiddelden, steekproefomvang en standaardafwijking van elke afzonderlijke groep.
- Het is mogelijk om het gemiddelde voor elk van de drie groepen afzonderlijk te bekijken ter vergelijking. Deze benadering heeft echter beperkingen en kan onjuist blijken te zijn omdat deze drie vergelijkingen geen rekening houden met totale gegevens en dus kunnen leiden tot type 1-fouten. R biedt ons de functie om de ANOVA-analyse uit te voeren om de variabiliteit tussen de onafhankelijke gegevensgroepen te onderzoeken. Er zijn vijf fasen in het uitvoeren van de ANOVA-analyse. In de eerste fase worden gegevens in csv-indeling gerangschikt en wordt de kolom voor elke variabele gegenereerd. Een van de kolommen zou een afhankelijke variabele zijn en de rest is de onafhankelijke variabele. In de tweede fase worden de gegevens in R studio gelezen en op de juiste manier benoemd. In de derde fase wordt een dataset gekoppeld aan individuele variabelen en gelezen door het geheugen. Ten slotte wordt de ANOVA in R gedefinieerd en geanalyseerd. In de onderstaande secties heb ik een paar voorbeelden van case study's gegeven waarin ANOVA-technieken moeten worden gebruikt.
- Zes insecticiden werden getest op elk 12 velden, en de onderzoekers telden het aantal insecten dat in elk veld achterbleef. Nu moeten de boeren weten of de insecticiden enig verschil maken, en zo ja, welke ze het beste gebruiken. U beantwoordt deze vraag door de functie aov () te gebruiken om een ANOVA uit te voeren.
- Vijftig patiënten kregen een van de vijf cholesterolverlagende medicamenteuze behandelingen (trt). Drie van de behandelingsomstandigheden betroffen hetzelfde medicijn toegediend als 20 mg eenmaal per dag (1 keer) 10 mg tweemaal per dag (2 keer) 5 mg vier keer per dag (4 keer). De twee resterende aandoeningen (drugD en drugE) vertegenwoordigden concurrerende geneesmiddelen. Welke medicamenteuze behandeling produceerde de grootste cholesterolverlaging (respons)?
ANOVA One-Way
- De eenrichtingsmethode is een van de basis ANOVA-technieken waarin variantieanalyse wordt toegepast en de gemiddelde waarde van meerdere populatiegroepen wordt vergeleken.
- One-way ANOVA kreeg zijn naam vanwege de beschikbaarheid van one-way geclassificeerde gegevens. Op een enkele manier kunnen ANOVA enkele afhankelijke variabele en een of meer onafhankelijke variabelen beschikbaar zijn.
- We zullen bijvoorbeeld de ANOVA-techniek op cholesterolgegevensset uitvoeren. De dataset bestaat uit twee variabelen trt (dit zijn behandelingen op 5 verschillende niveaus) en responsvariabelen. Onafhankelijke variabele - groepen medicamenteuze behandeling, afhankelijke variabele - middelen van 2 of meer groepen ANOVA. Op basis van deze resultaten kunt u bevestigen dat het 4 keer daags innemen van de doses van 5 mg beter was dan het eenmaal daags innemen van een dosis van twintig mg. Medicijn D heeft betere effecten in vergelijking met dat medicijn E
Geneesmiddel D geeft betere resultaten als het wordt ingenomen in doses van 20 mg in vergelijking met geneesmiddel E
Gebruikt cholesterolgegevensset in het multcomp-pakketinstall.packages('multcomp')
library(multcomp)
str(cholesterol)
attach(cholesterol)
aov_model <- aov(response ~ trt)
De ANOVA F-test voor behandeling (trt) is significant (p <.0001), waaruit blijkt dat de vijf behandelingen
# zijn niet allemaal even effectief.
samenvatting (aov_model)
detach (cholesterol)

De plotmeans () -functie in het gplots-pakket kan worden gebruikt om een grafiek van groepsgemiddelden en hun betrouwbaarheidsintervallen te produceren. Dit laat duidelijk behandelingsverschillen zieninstall.packages('gplots')
library(gplots)
plotmeans(response ~ trt, xlab="Treatment", ylab="Response",
main="Mean Plot\nwith 95% CI")
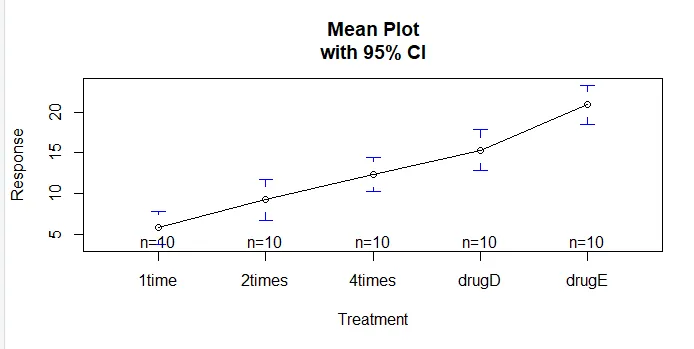
Laten we de uitvoer van TukeyHSD () onderzoeken op paarsgewijze verschillen tussen groepsgemiddelden
TukeyHSD (aov_model)
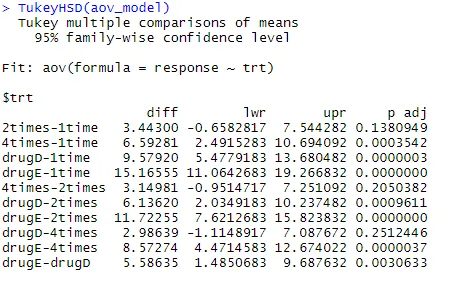
De gemiddelde cholesterolverlagingen voor 1 keer en 2 keer zijn niet significant verschillend van elkaar (p = 0.138), terwijl het verschil tussen 1 keer en 4 keer aanzienlijk verschillend is (p <.001).
par (mar = c (5, 8, 4, 2)) # verhoging linker marge plot (TukeyHSD (aov_model), las = 2)
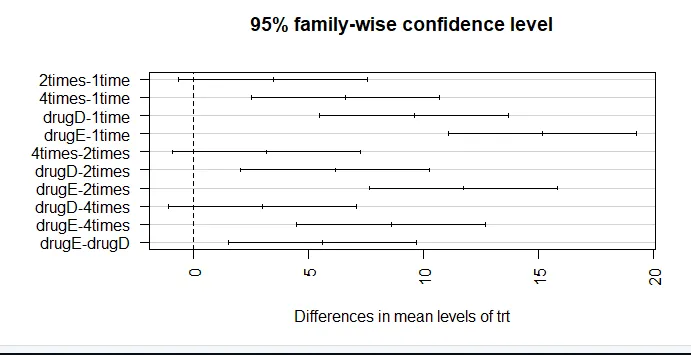
Het vertrouwen in resultaten hangt af van de mate waarin uw gegevens voldoen aan de aannames die aan de statistische tests ten grondslag liggen. In een eenrichtings-ANOVA wordt aangenomen dat de afhankelijke variabele normaal verdeeld is en in elke groep dezelfde variantie heeft. U kunt een QQ-plot gebruiken om de normality-veronderstellingbibliotheek (auto) te beoordelen.
QQ-plot (lm (respons ~ trt, data = cholesterol), simuleren = WAAR, main = ”QQ-plot”, labels = FALSE)
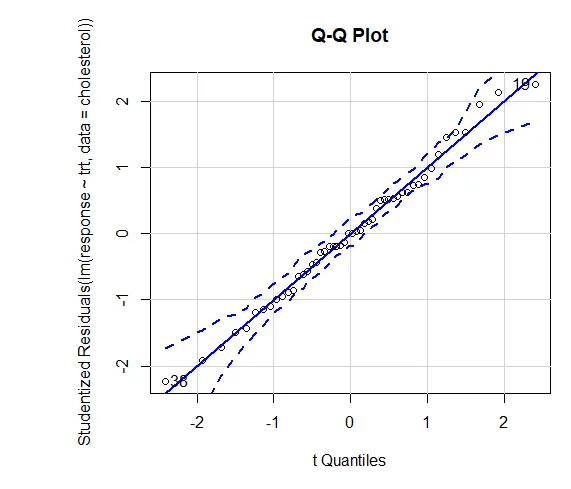
Gestippelde lijn = 95% betrouwbaarheidsomhullende, wat suggereert dat de normaliteitsveronderstelling redelijk goed is voldaan ANOVA veronderstelt dat varianties gelijk zijn tussen groepen of steekproeven. De Bartlett-test kan worden gebruikt om die veronderstelling te verifiëren
bartlett.test (reactie ~ trt, data = cholesterol). Bartlett's test geeft aan dat de varianties in de vijf groepen niet significant verschillen (p = 0, 97).
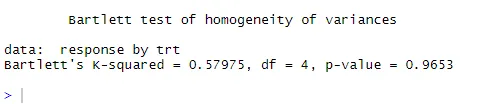
ANOVA is ook gevoelig voor uitbijters op uitbijters met behulp van de functie outlierTest () in het autopakket. U hoeft dit pakket mogelijk niet uit te voeren om uw autobibliotheek bij te werken.update.packages(checkBuilt = TRUE)
install.packages("car", dependencies = TRUE)
library(car)
outlierTest(aov_model)
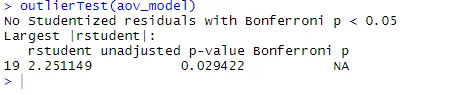
Uit de output kunt u zien dat er geen indicatie is voor uitbijters in de cholesterolgegevens (NA treedt op wanneer p> 1). Uitgaande van de QQ-plot, de test van Bartlett en de uitbijtertest, lijken de gegevens redelijk goed te passen in het ANOVA-model.
Tweerichtingsanova
Een andere variabele wordt toegevoegd in de Two-way ANOVA-test. Wanneer er twee onafhankelijke variabelen zijn, moeten we ANOVA in twee richtingen gebruiken in plaats van ANOVA-techniek in één richting die in het vorige geval werd gebruikt, waarbij we één continu afhankelijke variabele en meer dan één onafhankelijke variabele hadden. Om ANOVA in twee richtingen te verifiëren, moet aan meerdere veronderstellingen worden voldaan.
- Beschikbaarheid van onafhankelijke waarnemingen
- Waarnemingen moeten normaal worden verspreid
- Variantie moet gelijk zijn in waarnemingen
- Uitbijters mogen niet aanwezig zijn
- Onafhankelijke fouten
Om de bidirectionele ANOVA te verifiëren, wordt een andere variabele met de naam BP toegevoegd aan de gegevensset. De variabele geeft de bloeddruk aan bij patiënten. We willen graag controleren of er een statistisch verschil is tussen BP en de dosering die aan de patiënten wordt gegeven.
df <- read.csv ("file.csv")
df
anova_two_way <- aov (antwoord ~ trt + BP, data = df)
samenvatting (anova_two_way)
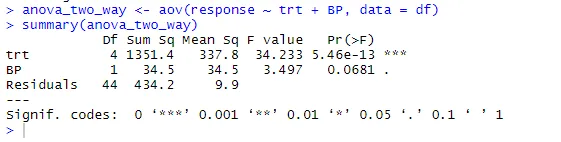
Uit de output kan worden geconcludeerd dat zowel de trt als BP statistisch verschillen van 0. Daarom kan de nulhypothese worden verworpen.
Voordelen van ANOVA in R
ANOVA-test bepaalt het gemiddelde verschil tussen twee of meer onafhankelijke groepen. Deze techniek is zeer nuttig voor analyse van meerdere artikelen, wat essentieel is voor marktanalyse. Met behulp van de ANOVA-test kan men de nodige inzichten uit de gegevens halen. Bijvoorbeeld tijdens een productenquête waarbij meerdere informatie zoals boodschappenlijsten, voorkeuren van klanten en antipathieën van gebruikers worden verzameld. De ANOVA-test helpt ons groepen van de bevolking te vergelijken. De groep kan mannelijk versus vrouwelijk zijn of verschillende leeftijdsgroepen. ANOVA-techniek helpt bij het onderscheiden van de gemiddelde waarden van verschillende bevolkingsgroepen die inderdaad verschillend zijn.
Conclusie - ANOVA in R
ANOVA is een van de meest gebruikte methoden voor het testen van hypothesen. In dit artikel hebben we een ANOVA-test uitgevoerd op de gegevensset bestaande uit vijftig patiënten die een cholesterolverlagende medicamenteuze behandeling hebben gekregen en hebben we verder gezien hoe bidirectioneel ANOVA kan worden uitgevoerd wanneer een aanvullende onafhankelijke variabele beschikbaar is.
Aanbevolen artikelen
Dit is een gids voor ANOVA in R. Hier bespreken we het One-Way en Two-Way Anova-model samen met voorbeelden en voordelen van ANOVA. U kunt ook onze andere voorgestelde artikelen doornemen -
- Regressie versus ANOVA
- Wat is SPSS?
- Resultaten interpreteren met ANOVA-test
- Functies in R